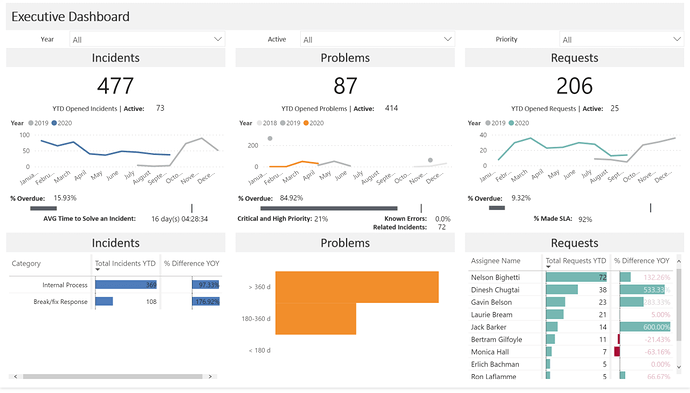
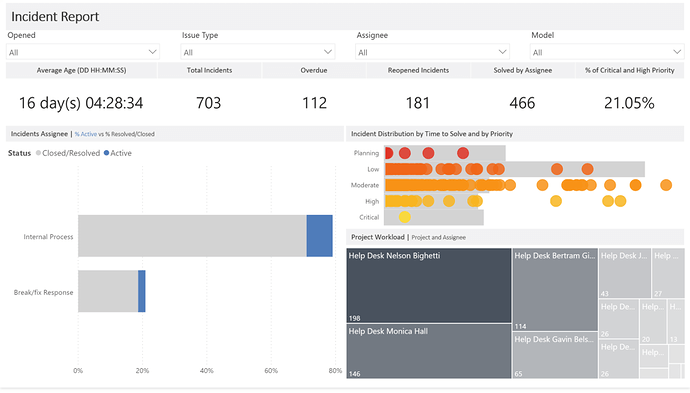
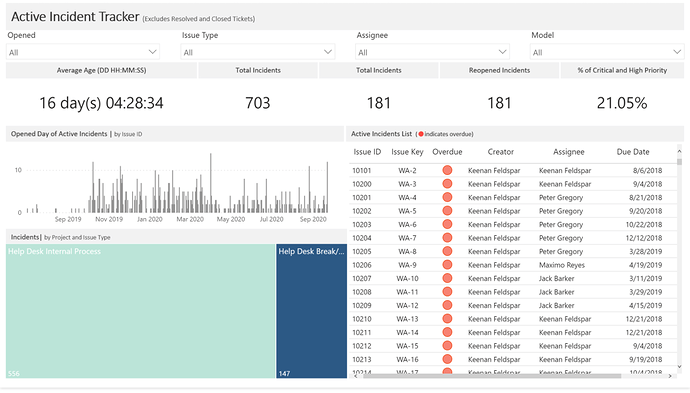
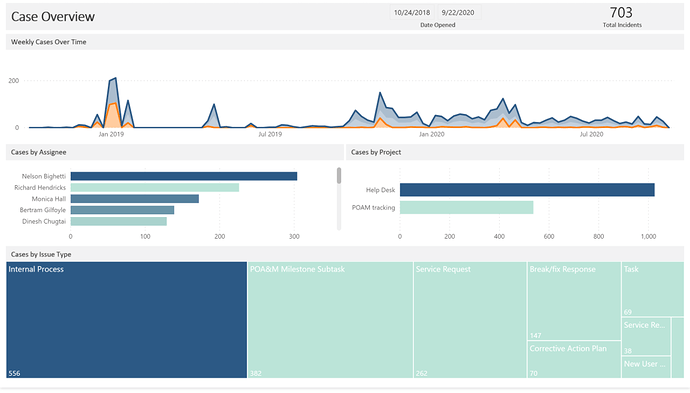
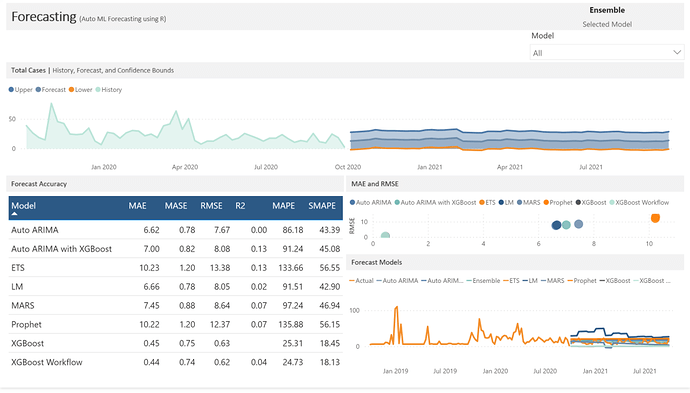
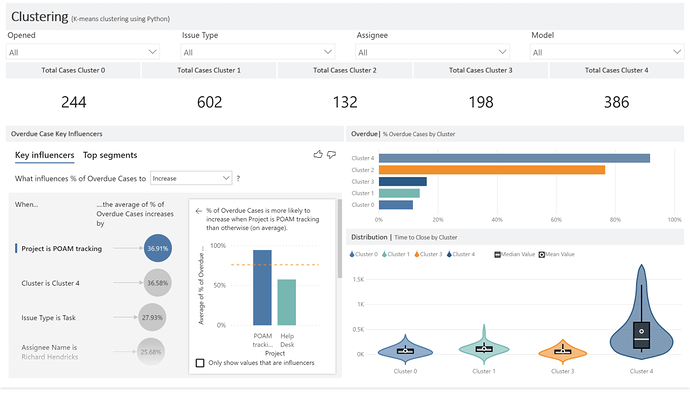
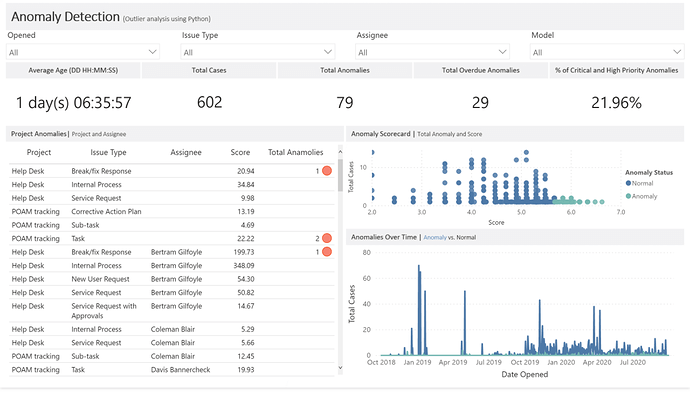
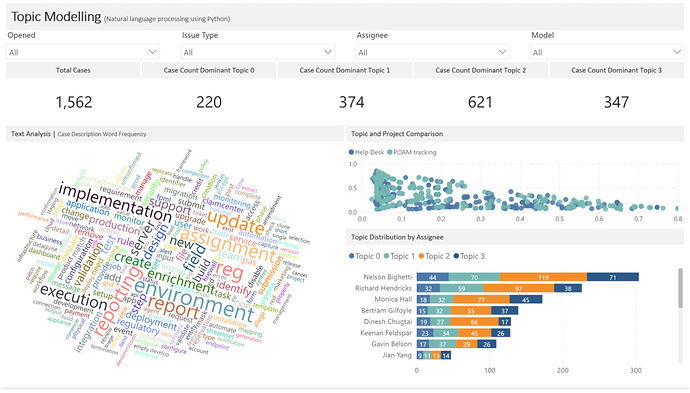
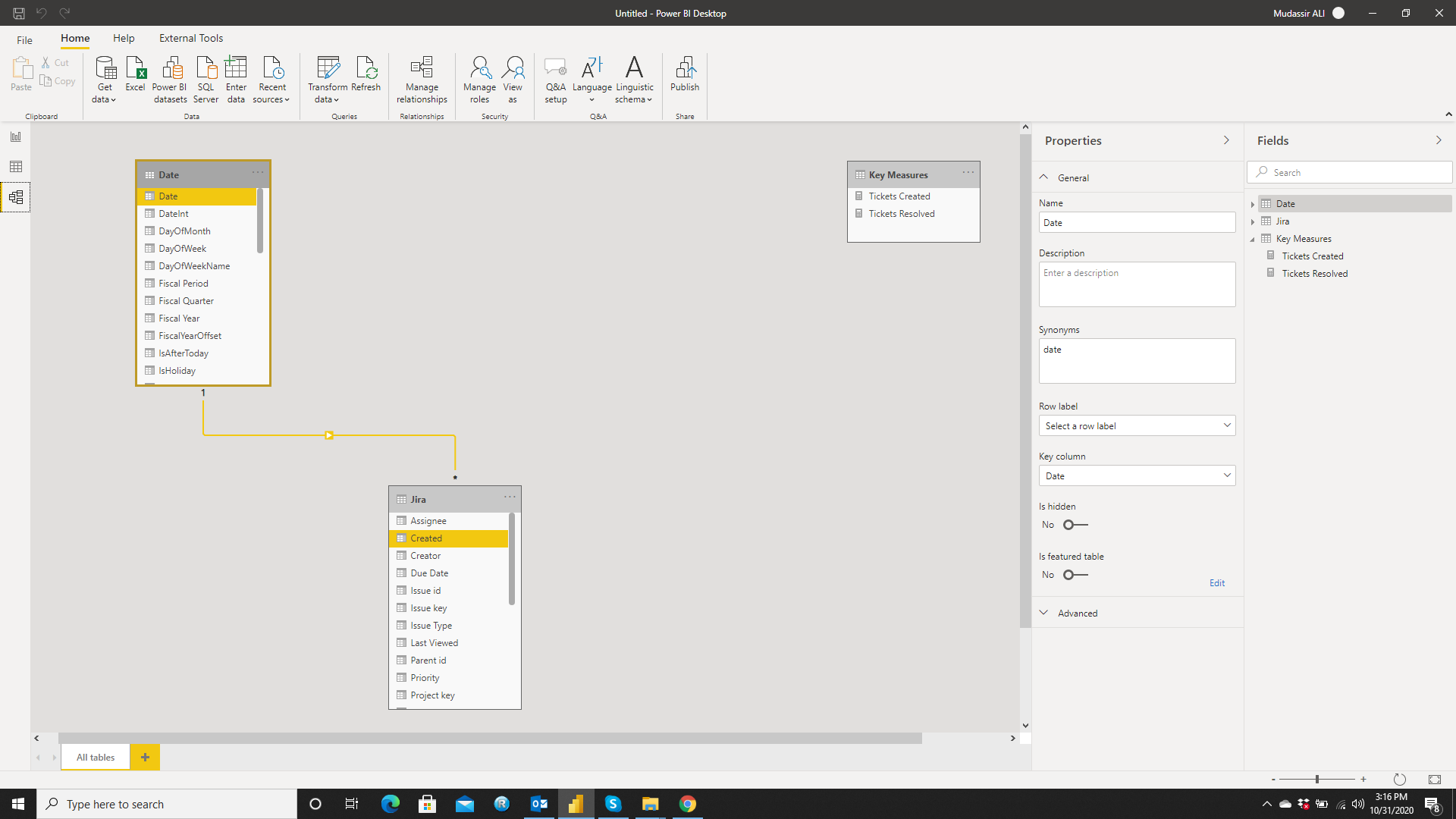
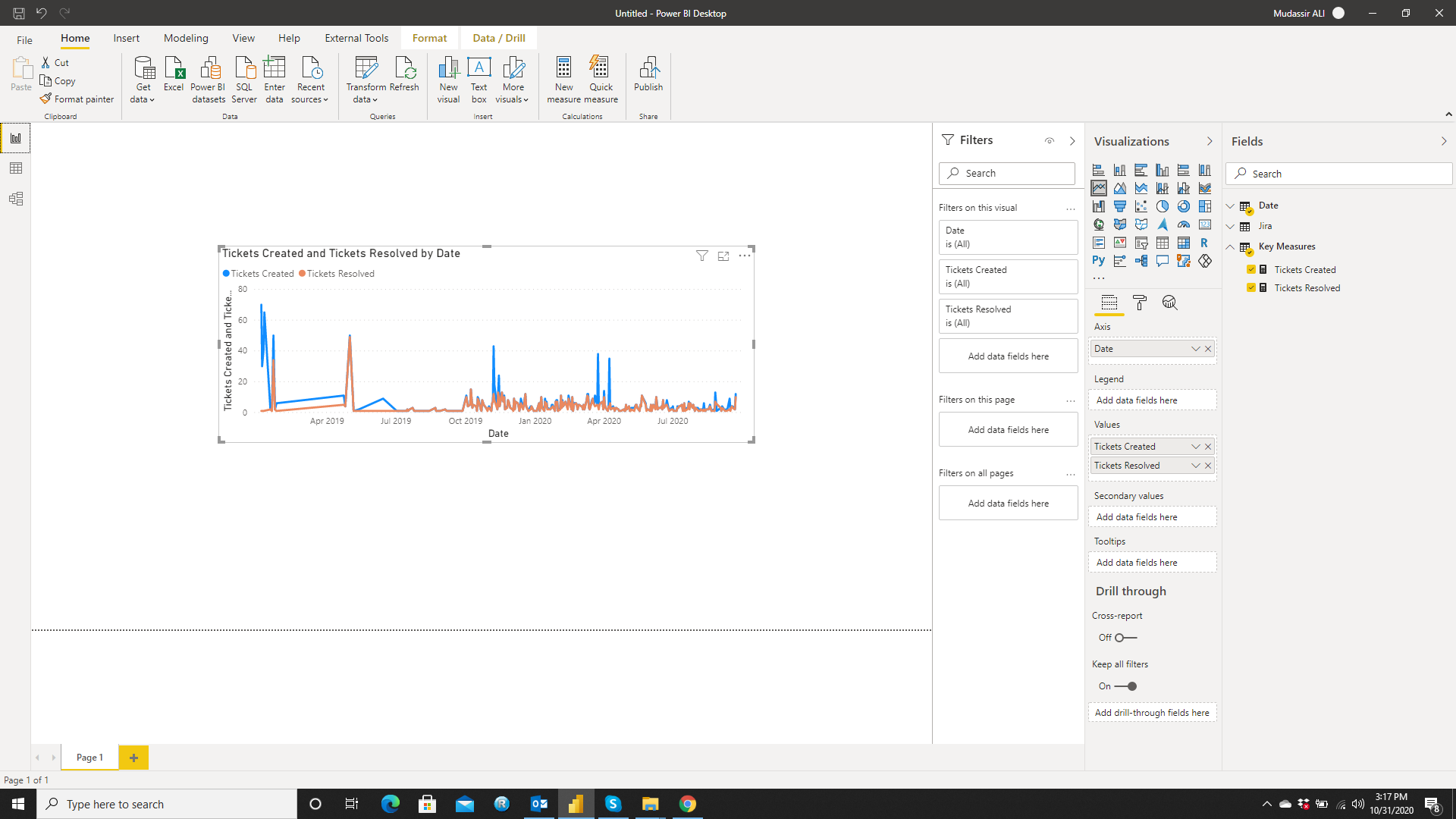
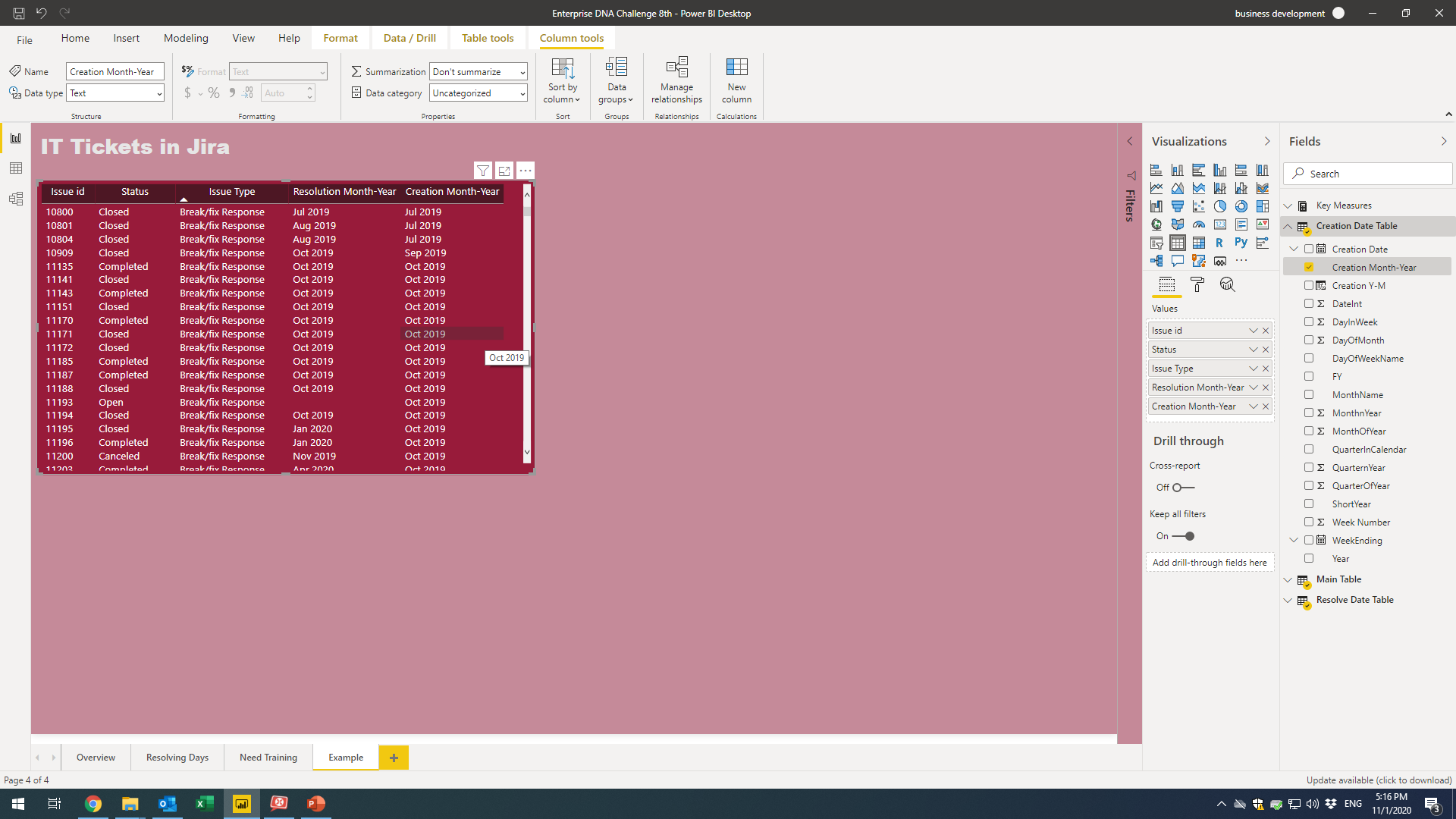
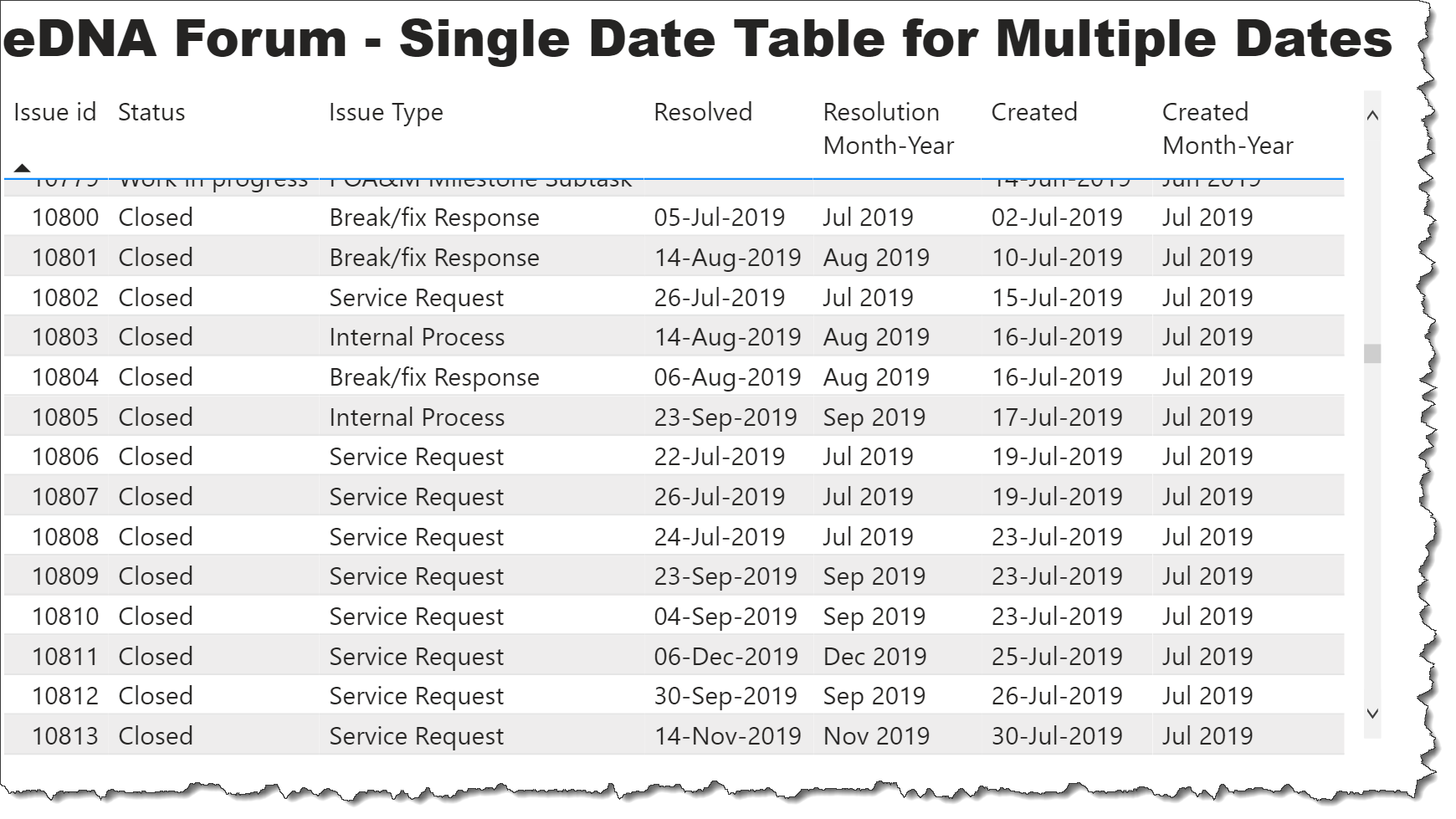
Before I get started, I used some slightly different terminology as most so here’s a quick cheat sheet:
Summary
Total Incidents
// Calculates total distinct incidents.
CALCULATE(
DISTINCTCOUNT(JIRA[Issue id]),
FILTER(JIRA, [Class] = “Incident”)
)
Total Open Cases
// Calculates total active open cases.
CALCULATE(
DISTINCTCOUNT(JIRA[Issue id]) + 0,
REMOVEFILTERS(
JIRA[Opened (modified)],
JIRA[Overdue],
JIRA[Max Year?]
),
FILTER(
JIRA,
[Active (Excluding Resolved)] = “Active”
)
)
Total Overdue Incidents
// Total distinct overdue incidents.
CALCULATE(
DISTINCTCOUNT(JIRA[Issue id]),
FILTER(
JIRA,
JIRA[Overdue] = “Overdue” && [Class] = “Incident”
)
)
Total Closed Cases
// Calculates total closed or resolved cases.
CALCULATE(
DISTINCTCOUNT(JIRA[Issue id]) + 0,
REMOVEFILTERS(
JIRA[Opened (modified)],
JIRA[Overdue],
JIRA[Max Year?]),
FILTER(
JIRA,
[Active (Excluding Resolved)] = “Closed/Resolved”
)
)
Total Cases
// Calculates total cases.
CALCULATE(
DISTINCTCOUNT(JIRA[Issue id]) + 0,
REMOVEFILTERS(
JIRA[Opened (modified)],
JIRA[Overdue],
JIRA[Max Year?]
)
)
Total Active Incidents
// Calculates total distinct active incidents.
CALCULATE(
DISTINCTCOUNT([Issue id]),
REMOVEFILTERS(
JIRA[Opened (modified)],
JIRA[Overdue],
JIRA[Max Year?]
),
FILTER(
JIRA,
[Active] = TRUE && [Class] = “Incident”
)
)
Time to Close an Incident (seconds)
// Calculates the difference in seconds between opening and closing an incident.
CALCULATE(
AVERAGEX(JIRA,
DATEDIFF([Opened (modified)], [Closed], SECOND)
),
FILTER(JIRA,
[Closed] > [Opened (modified)] && [Class] = “Incident”
)
)
Time to Close an Incident
// Calculates the difference in days between opening and closing an incident.
CALCULATE(
AVERAGEX(JIRA,
DATEDIFF([Opened (modified)], [Closed], DAY)
),
FILTER(JIRA,
[Closed] > [Opened (modified)] && [Class] = “Incident”
)
)
Show Group
// Shows selected groups.
SELECTEDVALUE(
JIRA[Issue Type],
“Showing All Groups”
)
Show Assignees
// Shows selected assignees.
SELECTEDVALUE(
JIRA[Assignee],
“All Assignees”
)
Last Year Total Incidents
// Total incidents last year.
CALCULATE(
DISTINCTCOUNT([Issue id]),
FILTER(
JIRA,
[Year] = YEAR(MAX([Opened (modified)])) - 1 && [Class] = “Incident”
)
)
Incidents Solved by Assigned
// Counts each distinct incident solved by the assigned employee.
CALCULATE(
DISTINCTCOUNT([Issue id]),
FILTER(
JIRA,
[Assignee] = [Reporter] && [Class] = “Incident”
)
)
Current Year Total Incidents
// Counts each distinct incident made in the last year.
CALCULATE(
DISTINCTCOUNT(JIRA[Issue id]),
REMOVEFILTERS(
JIRA[Opened (modified)],
JIRA[Overdue],
JIRA[Max Year?]
),
FILTER(
JIRA,
[Max Year?] = TRUE && [Class] = “Incident”
)
)
Incident Average Age (DD:HH:MM:SS)
// Transforms time in seconds into DD:HH:MM:SS format.
// Formats time in seconds into days
FORMAT(
ROUNDDOWN(
CALCULATE(
AVERAGEX(JIRA, [Time to Close an Incident (seconds)]) / 86400,
FILTER(JIRA, [Class] = “Incident”)
),
0
),
“d”
) & " day(s) " &
// Formats time in seconds into hours, minutes, and seconds
FORMAT(
CALCULATE(
AVERAGEX(JIRA, [Time to Close an Incident (seconds)]) / 86400,
FILTER(JIRA, [Class] = “Incident”)
),
“hh:mm:ss”
)
% of Overdue Incidents
// Shows the percentage of incidents which are overdue.
CALCULATE(
DISTINCTCOUNT(JIRA[Issue id]),
FILTER(
JIRA,
JIRA[Overdue] = “Overdue” && [Class] = “Incident”
)
) / CALCULATE(
DISTINCTCOUNT(JIRA[Issue id]),
REMOVEFILTERS(JIRA[Overdue]),
FILTER(JIRA, [Class] = “Incident”)
)
% of Critical and High Priority Incidents
// Shows the percentage of critical or high priority incidents.
CALCULATE(
DISTINCTCOUNT([Issue id]),
FILTER(
JIRA,
[Priority] = “Highest” && [Class] = “Incident” ||
[Priority] = “High” && [Class] = “Incident”
)
) / CALCULATE(
DISTINCTCOUNT([Issue id]),
FILTER(JIRA, [Class] = “Incident”)
)
% Difference Incident YOY
// Calculates the total change in incidents from last year to this year.
([Current Year Total Incidents] - [Last Year Total Incidents]) / [Last Year Total Incidents]
Reopen count (Incident)
// Calculates total distinct incidents reopened after resolved date.
CALCULATE(
DISTINCTCOUNT([Issue id]),
FILTER(
JIRA,
[Updated] > [Resolved] && [Class] = “Incident”
)
)
Diff Between Suggested vs. User Due Date
// Calculates difference between original user input due date and the suggested system due date.
CALCULATE(
AVERAGEX(JIRA,
DATEDIFF(
JIRA[Due Date],
JIRA[Suggested Due Date],
DAY
)
),
FILTER(JIRA, [Due Date] <> BLANK()))
% of Overdue Requests
// Shows the percentage of requests which are overdue.
CALCULATE(
DISTINCTCOUNT(JIRA[Issue id]),
FILTER(
JIRA,
JIRA[Overdue] = “Overdue” && [Class] = “Request”
)
) / CALCULATE(
DISTINCTCOUNT(JIRA[Issue id]),
REMOVEFILTERS(JIRA[Overdue]),
FILTER(JIRA, [Class] = “Request”)
)
Current Year Total Requests
// Counts each distinct request made in the last year.
CALCULATE(
DISTINCTCOUNT(JIRA[Issue id]),
REMOVEFILTERS(
JIRA[Opened (modified)],
JIRA[Overdue],
JIRA[Max Year?]
),
FILTER(
JIRA,
[Max Year?] = TRUE && [Class] = “Request”
)
)
Last Year Total Requests
// Total requests last year.
CALCULATE(
DISTINCTCOUNT([Issue id]) + 0,
FILTER(
JIRA,
[Year] = YEAR(MAX([Opened (modified)])) - 1 && [Class] = “Request”
)
)
Total # Requests
// Calculates total distinct requests.
VAR TotalRequests = CALCULATE(
DISTINCTCOUNT(JIRA[Issue id]),
FILTER(JIRA, [Class] = “Request”))
RETURN
IF(ISBLANK(TotalRequests), 0, TotalRequests)
Total Active Requests
// Calculates total distinct active requests.
CALCULATE(
DISTINCTCOUNT([Issue id]) + 0,
REMOVEFILTERS(
JIRA[Opened (modified)],
JIRA[Overdue],
JIRA[Max Year?]
),
FILTER(
JIRA,
[Active] = TRUE && [Class] = “Request”
)
)
% Difference Problems YOY
// Calculates the total change in problems from last year to this year.
([Current Year Total Problems] - [Last Year Total Problems]) / [Last Year Total Problems]
% of Critical and High Priority
// Shows the percentage of critical or high priority problems.
CALCULATE(
DISTINCTCOUNT([Issue id]) + 0,
FILTER(
JIRA,
[Priority] = “Highest” && [Class] = “Problem” ||
[Priority] = “High” && [Class] = “Problem”
)
) / CALCULATE(
DISTINCTCOUNT([Issue id]),
FILTER(JIRA, [Class] = “Problem”)
)
% of Overdue Problems
// Shows the percentage of problems which are overdue.
CALCULATE(
DISTINCTCOUNT(JIRA[Issue id]),
FILTER(
JIRA,
JIRA[Overdue] = “Overdue” && [Class] = “Problem”
)
) / CALCULATE(
DISTINCTCOUNT(JIRA[Issue id]),
REMOVEFILTERS(JIRA[Overdue]),
FILTER(JIRA, [Class] = “Problem”)
)
Current Year Total Problems
// Counts each distinct problem made in the last year.
CALCULATE(
DISTINCTCOUNT(JIRA[Issue id]),
REMOVEFILTERS(
JIRA[Opened (modified)],
JIRA[Overdue],
JIRA[Max Year?]
),
FILTER(
JIRA,
[Max Year?] = TRUE && [Class] = “Problem”
)
)
Last Year Total Problems
// Total problems last year.
CALCULATE(
DISTINCTCOUNT([Issue id]),
FILTER(
JIRA,
[Year] = YEAR(MAX([Opened (modified)])) - 1 && [Class] = “Problem”
)
)
Problems with Related Incidents
// Counts each distinct problems which has a related incident.
CALCULATE(
DISTINCTCOUNT([Issue id]),
FILTER(JIRA,
JIRA[Related Incidents] > 0 &&
ISBLANK([Related Incidents]) = FALSE &&
[Class] = “Problem”
)
)
Total # Problems
// Calculates total distinct problem.
CALCULATE(
DISTINCTCOUNT(JIRA[Issue id]),
FILTER(JIRA, [Class] = “Problem”)
)
Total Active Problems
// Calculates total distinct active problems.
CALCULATE(
DISTINCTCOUNT([Issue id]),
REMOVEFILTERS(
JIRA[Opened (modified)],
JIRA[Overdue],
JIRA[Max Year?]
),
FILTER(
JIRA,
[Active] = TRUE && [Class] = “Problem”
)
)
% made SLA
// Shows the percentage of requests which made SLA
CALCULATE(
DISTINCTCOUNT(JIRA[Issue id]),
FILTER(JIRA, JIRA[Made SLA] = TRUE)
) / DISTINCTCOUNT(JIRA[Issue id])
% of known error
// Shows the percentage of problems that are known errors
VAR KnownError = CALCULATE(
DISTINCTCOUNT([Issue id]),
FILTER(JIRA,
[Issue Type] = “Break/fix Response” && [Class] = “Problem”
)
) / CALCULATE(
DISTINCTCOUNT([Issue id]),
FILTER(JIRA, [Class] = “Problem”)
)
return
IF(ISBLANK(KnownError), 0, KnownError)
% Difference Requests YOY
// Calculates the total change in requests from last year to this year.
IFERROR(
(([Current Year Total Requests] - [Last Year Total Requests]) / [Last Year Total Requests]),
BLANK()
)
Total Problems Last Two Years
// Calculates Total Problems last two years.
VAR TotalProblems = [Current Year Total Problems] + [Last Year Total Problems]
RETURN
IF(ISBLANK(TotalProblems), 0, TotalProblems)
Total Anamolies
// Total count of anomalies detected.
CALCULATE(
DISTINCTCOUNT([Issue id]),
FILTER(JIRA, JIRA[Label] = 1)
)
Time to Close a Case
// Calculates the difference in days between opening and closing an case.
CALCULATE(
AVERAGEX(JIRA,
DATEDIFF([Opened (modified)], [Closed], DAY)
),
FILTER(JIRA,
[Closed] > [Opened (modified)]
)
)
Time to Close a Case (seconds)
// Calculates the difference in seconds between opening and closing an case.
CALCULATE(
AVERAGEX(JIRA,
DATEDIFF([Opened (modified)], [Closed], SECOND)
),
FILTER(JIRA,
[Closed] > [Opened (modified)]
)
)
Case Average Age (DD:HH:MM:SS)
// Transforms time in seconds into DD:HH:MM:SS format.
// Formats time in seconds into days
FORMAT(
ROUNDDOWN(
CALCULATE(
AVERAGEX(JIRA, [Time to Close a Case (seconds)]) / 86400
),
0
),
“d”
) & " day(s) " &
// Formats time in seconds into hours, minutes, and seconds
FORMAT(
CALCULATE(
AVERAGEX(JIRA, [Time to Close a Case (seconds)]) / 86400
),
“hh:mm:ss”
)
Total Overdue Cases
// Total distinct overdue cases.
CALCULATE(
DISTINCTCOUNT(JIRA[Issue id]),
FILTER(
JIRA,
JIRA[Overdue] = “Overdue”
)
)
Total Anamolies Overdue
// Total count of anomalies overdue.
CALCULATE(
COUNT(JIRA[Label]),
FILTER(JIRA,
JIRA[Label] = 1 &&
[Overdue] = “Overdue”
)
) + 0
% of Critical and High Priority Anomalies
// Shows the percentage of critical or high priority anomalies.
CALCULATE(
DISTINCTCOUNT([Issue id]) + 0,
FILTER(
JIRA,
[Priority] = “Highest” ||
[Priority] = “High”
)
) / CALCULATE(
DISTINCTCOUNT([Issue id])
)
% of Overdue Cases
// Shows the percentage of cases which are overdue.
CALCULATE(
DISTINCTCOUNT(JIRA[Issue id]),
FILTER(
JIRA,
JIRA[Overdue] = “Overdue”
)
) / CALCULATE(
DISTINCTCOUNT(JIRA[Issue id]),
REMOVEFILTERS(JIRA[Overdue])
)
Historic
// Returns only the historic data.
CALCULATE (
AVERAGEX(‘Auto ML - Forecasts’, ‘Auto ML - Forecasts’[.value]),
FILTER (
ALL ( ‘Auto ML - Forecasts’[Model] ),
‘Auto ML - Forecasts’[Model] = “Actual”
)
)
Forecast
// If a forecast model has not been selected then return an ensemble forecast else return the forecast model (excluding actual data or ensemble)
SWITCH(TRUE(),
[Selected Model] = “Ensemble”, CALCULATE(
AVERAGEX(‘Auto ML - Forecasts’, ‘Auto ML - Forecasts’[.value]),
‘Auto ML - Forecasts’[Model] = “Ensemble”
),
CALCULATE(
AVERAGEX(‘Auto ML - Forecasts’, ‘Auto ML - Forecasts’[.value]),
‘Auto ML - Forecasts’[Model] <> “Actual” &&
‘Auto ML - Forecasts’[Model] <> “Ensemble”
)
)
Selected Model
// Returns the selected forecast model.
SELECTEDVALUE(‘Auto ML - Forecasts’[Model], “Ensemble”)
Lower
// If a forecast model has not been selected then return an ensemble lower confidence bound else return the forecast model (excluding actual data or ensemble)
SWITCH(TRUE(),
[Selected Model] = “Ensemble”, CALCULATE(
AVERAGEX(‘Auto ML - Forecasts’, ‘Auto ML - Forecasts’[.conf_lo]),
‘Auto ML - Forecasts’[Model] = “Ensemble”
),
CALCULATE(
AVERAGEX(‘Auto ML - Forecasts’, ‘Auto ML - Forecasts’[.conf_lo]),
‘Auto ML - Forecasts’[Model] <> “Actual” &&
‘Auto ML - Forecasts’[Model] <> “Ensemble”
)
)
Upper
// If a forecast model has not been selected then return an ensemble upper confidence bound else return the forecast model (excluding actual data or ensemble)
SWITCH(TRUE(),
[Selected Model] = “Ensemble”, CALCULATE(
AVERAGEX(‘Auto ML - Forecasts’, ‘Auto ML - Forecasts’[.conf_hi]),
‘Auto ML - Forecasts’[Model] = “Ensemble”
),
CALCULATE(
AVERAGEX(‘Auto ML - Forecasts’, ‘Auto ML - Forecasts’[.conf_hi]),
‘Auto ML - Forecasts’[Model] <> “Actual” &&
‘Auto ML - Forecasts’[Model] <> “Ensemble”
)
)
Summary
Max Year?
IF(
YEAR([Opened (modified)]) = YEAR(MAX([Opened (modified)])),
TRUE,
FALSE
)
Overdue
// Calculates incident overdue status.
IF(
[Active] = FALSE && [Closed] > [Suggested Due Date] && [Suggested Due Date] <> BLANK() ||
[Active] = TRUE && NOW() > [Suggested Due Date] && [Suggested Due Date] <> BLANK(),
“Overdue”,
“Non Overdue”
)
Opened Month Tooltip
// Formats the opening date as the month name.
FORMAT([Opened (modified)], “MMMM”)
Active (Excluding Resolved)
// Calculates if an incident is active and open.
IF(
[Active] = FALSE(),
“Closed/Resolved”,
“Active”
)
Opened (mmm YYYY)
// Formats the opened date as mmm YYYY.
LEFT([Opened Month Tooltip], 3) & " " & [Year]
OpenedMonthYearSort
// Formats the opening year and month as an integer.
[Year] * 100 + MONTH([Opened (modified)])
ActiveExcludingResolvedSort
// Calculates if an incident is active and open.
IF(
[Active] = FALSE(),
1,
2
)
Priority Status
// Defines priority status in standardized terminology.
SWITCH(TRUE(),
[Priority] = “Highest”, “Critical”,
[Priority] = “High”, “High”,
[Priority] = “Medium”, “Moderate”,
[Priority] = “Low”, “Low”,
[Priority] = “Minor”, “Planning”,
BLANK()
)
PrioritySort
// Calculates priority status sort order.
SWITCH(TRUE(),
[Priority] = “Highest”, 5,
[Priority] = “High”, 4,
[Priority] = “Medium”, 3,
[Priority] = “Low”, 2,
[Priority] = “Minor”, 1,
BLANK()
)
Opened Date
// Removes the time from the opening date to link to the Date Opened table.
FORMAT([Opened (modified)], “mm/dd/YYYY”)
Overdue Status
// Calculates incident overdue status flag.
IF(
[Active] = FALSE && [Closed] > [Suggested Due Date] && [Suggested Due Date] <> BLANK() ||
[Active] = TRUE && NOW() > [Suggested Due Date] && [Suggested Due Date] <> BLANK(),
1,
0
)
Class
// Adds an issue type classification group.
VAR LevelNumber = 1
VAR LevelPath = PATH ( JIRA[Issue id], JIRA[Parent id] )
VAR LevelKey = PATHITEM ( LevelPath, LevelNumber, INTEGER )
VAR LevelName = LOOKUPVALUE ( JIRA[Issue id], JIRA[Issue id], LevelKey )
VAR LevelCount = CALCULATE(COUNTROWS(JIRA), ALL(JIRA), JIRA[Parent id] = EARLIER(JIRA[Issue id]))
VAR Result = IF(LevelName = [Issue id], IF(LevelCount <> BLANK(), “Problem”, “Incident”), “Incident”)
RETURN
SWITCH(TRUE(),
[Issue Type] = “New User Request”, “Request”,
[Issue Type] = “Service Request”, “Request”,
[Issue Type] = “Service Request with Approvals”, “Request”,
// I only included these three for visualization purposed. There’s not enough information in the dataset to determine if any of these would be classified as a problem or incident.
[Issue Type] = “Task”, “Problem”,
[Issue Type] = “Sub-task”, “Problem”,
[Issue Type] = “Corrective Action Plan”, “Problem”,
[Issue Type] = “POA&M Milestone Subtask”, “Problem”,
Result
)
Watchers (grouped)
// Concatenates all watchers, skipping blanks.
IF([Watchers] = “”, “”, [Watchers]) &
IF([Watchers_4] = “”, “”, ", " & [Watchers_4]) &
IF([Watchers_5] = “”, “”, ", " & [Watchers_5]) &
IF([Watchers_6] = “”, “”, ", " & [Watchers_6]) &
IF([Watchers_7] = “”, “”, ", " & [Watchers_7])
Suggested Due Date
// Calculates a smart due date.
VAR LevelNumber = 1
VAR LevelPath = PATH ( JIRA[Issue id], JIRA[Parent id] )
VAR LevelKey = PATHITEM ( LevelPath, LevelNumber, INTEGER )
VAR LevelName = LOOKUPVALUE ( JIRA[Due Date], JIRA[Issue id], LevelKey )
VAR DateModifier = CALCULATE(ROUND(AVERAGEX(JIRA, [Resolved] - [Created]), 0), FILTER(JIRA, [Resolved] <> BLANK()))
VAR ResultDate = IF(ISBLANK([Due Date]), LevelName, [Due Date])
VAR UpdatedResult = IF(ISBLANK(ResultDate), [Due Date (modified)], ResultDate)
VAR Result = IF(ISBLANK(UpdatedResult), [Created] + DateModifier, UpdatedResult)
RETURN
Result
Related Incidents
// Calculates total incidents related to a distinct problem.
CALCULATE(
COUNTROWS(JIRA),
ALL(JIRA),
JIRA[Parent id] = EARLIER(JIRA[Issue id])
)
Made SLA
// Calculates if the service level agreement was met.
IF([Suggested Due Date] >= [Resolved], TRUE(), FALSE())
Time Span Breakdown
// Calculates a time span age category.
SWITCH(TRUE(),
DATEDIFF([Opened (modified)], NOW(), DAY) < 180, “< 180 d”,
DATEDIFF([Opened (modified)], NOW(), DAY) > 360, “> 360 d”,
“180-360 d”
)
Time Span Breakdown Sort
// Calculates a time span age category sort value.
SWITCH(TRUE(),
DATEDIFF([Opened (modified)], NOW(), DAY) < 180, 3,
DATEDIFF([Opened (modified)], NOW(), DAY) > 360, 1,
2
)
Anomaly Status
// Returns the anomaly status based on the label flag.
IF([Label] = 1, “Anomaly”, “Normal”)
Time to Close
// Calculates the difference in days between opening and closing an case.
DATEDIFF([Opened (modified)], [Closed], DAY)
Priority Status
// Defines priority status in standardized terminology.
SWITCH(TRUE(),
[Priority] = 5, “Critical”,
[Priority] = 4, “High”,
[Priority] = 3, “Moderate”,
[Priority] = 2, “Low”,
[Priority] = 1, “Planning”,
BLANK()
)
Model
// Creates a shortened forecast model name for reporting purposes.
SWITCH(TRUE(),
[.model_id] = 0, “Actual”,
[.model_id] = 1, “Auto ARIMA”,
[.model_id] = 2, “Auto ARIMA with XGBoost”,
[.model_id] = 3, “ETS”,
[.model_id] = 4, “Prophet”,
[.model_id] = 5, “LM”,
[.model_id] = 6, “XGBoost”,
[.model_id] = 7, “XGBoost Workflow”,
[.model_id] = 8, “MARS”,
[.model_id] = 9, “Ensemble”,
BLANK()
)