Hi there,
Could someone please help me in writing the dax for the 3 calculated columns as shown below? My data looks like this: mydata.xlsx (10.4 KB)

Many thanks in advance,
Michelle
Hi there,
Could someone please help me in writing the dax for the 3 calculated columns as shown below? My data looks like this: mydata.xlsx (10.4 KB)
Many thanks in advance,
Michelle
Its easy in Power Query. Let me know if you need only in DAX
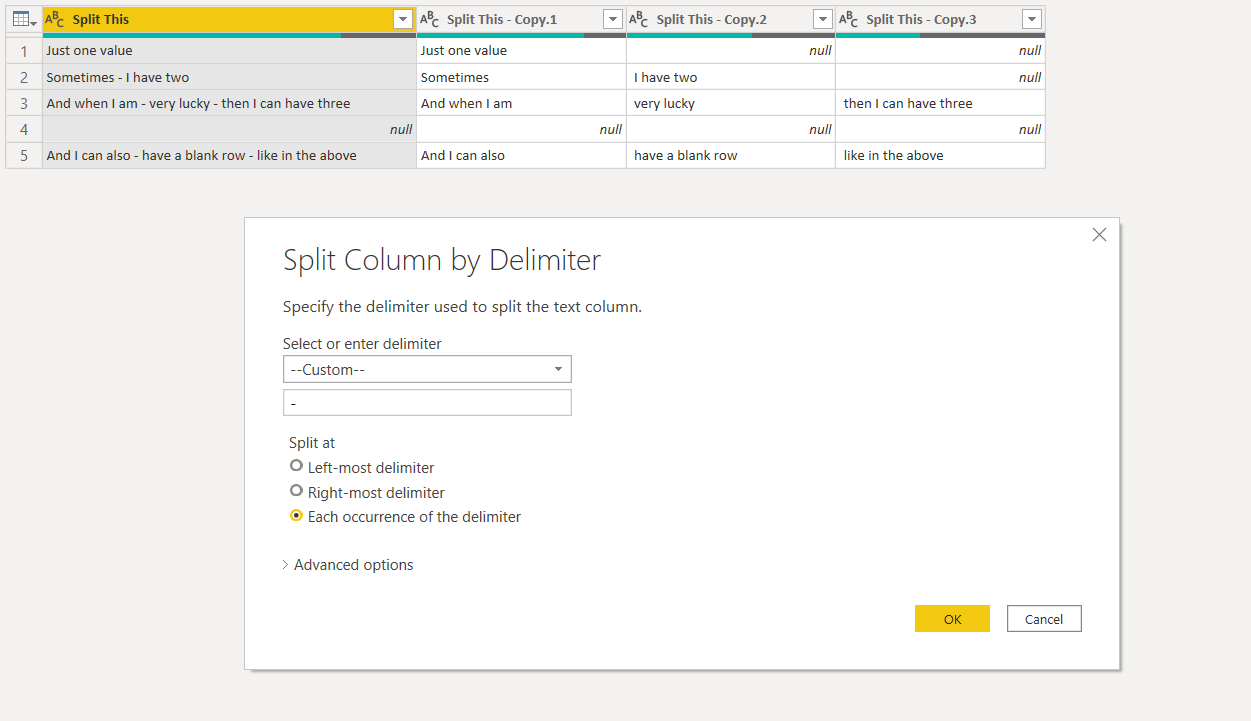
Create duplicate column and split column by delimiter .
Hello Rajesh, thank you for your reply. However, I need a calculated column formula as I cannot use Power Query.
Hi
I attached a step by step on the Poer Qury transformation that may help on the split .
Luca
009-PowerQueryVariousTips.pdf (1.6 MB)
@BrianJ Amazing resource shared by Luca that can be shared with forum members for troubleshooting general issues.
Thanks Luca - - - i need the Dax forumal
for the dax is there any limitation on words?
I would use a combination of Left/Right with search dax function…
I done once for splitting a the Name filed into the two Given Name and Family Name.
Otherwise, I think should use SQL and some playing with the table
lb
A couple of questions:
will there only ever be a max of 2 “-” delimiters?
will the dashes always have a blank space to the left and right of them?
Just want to make sure we won’t be providing an overly specific solution based on a small # of observations.
Thanks.
Have you given any consideration as to why you have to use a calculated column? If you are forced into a calculated column you could possibly make extra columns to have helper columns, but your model loses efficiency with wider columns.
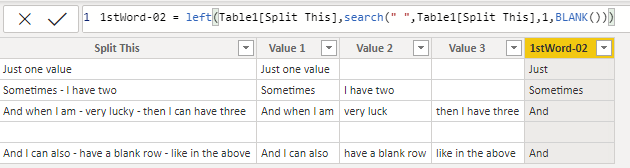
here the example for the first word
1stWord-02 =
left ( Table1[Split This],
search ( " " , Table1[Split This], 1 , BLANK() )
)
with serach i get the position of the first space, and then i get the left side of the text
lb
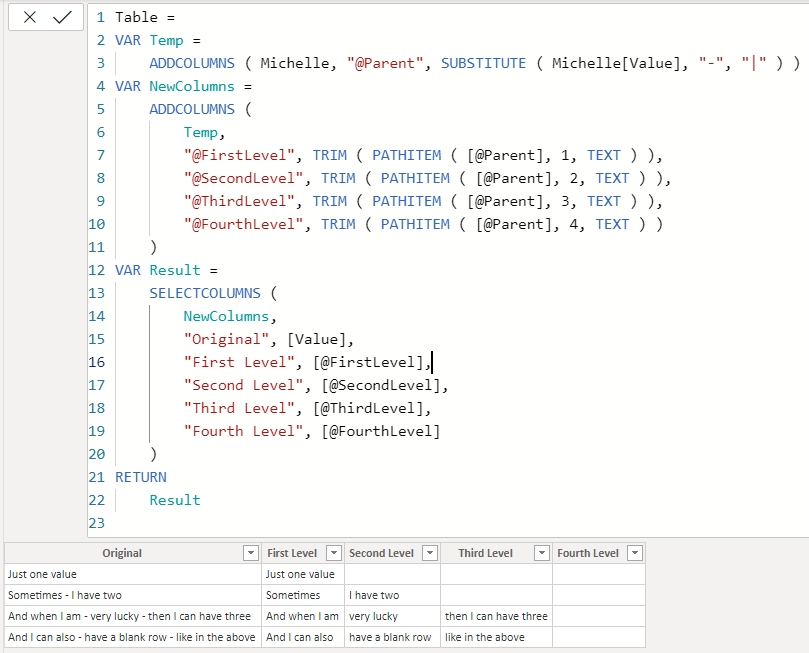
@michellepace Try this:
Michelle.pbix (22.3 KB)
Table =
VAR Temp =
ADDCOLUMNS ( Michelle, "@Parent", SUBSTITUTE ( Michelle[Value], "-", "|" ) )
VAR NewColumns =
ADDCOLUMNS (
Temp,
"@FirstLevel", TRIM ( PATHITEM ( [@Parent], 1, TEXT ) ),
"@SecondLevel", TRIM ( PATHITEM ( [@Parent], 2, TEXT ) ),
"@ThirdLevel", TRIM ( PATHITEM ( [@Parent], 3, TEXT ) ),
"@FourthLevel", TRIM ( PATHITEM ( [@Parent], 4, TEXT ) )
)
VAR Result =
SELECTCOLUMNS (
NewColumns,
"Original", [Value],
"First Level", [@FirstLevel],
"Second Level", [@SecondLevel],
"Third Level", [@ThirdLevel],
"Fourth Level", [@FourthLevel]
)
RETURN
ResultSimilar can be done on “-” but how many level of “-” need to be split?
lb
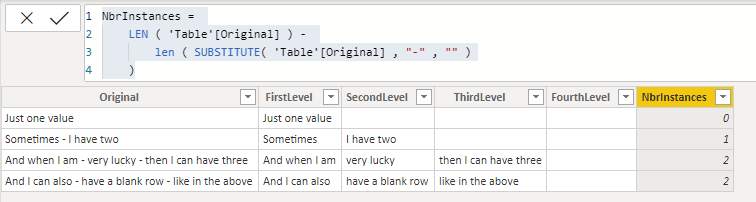
otherwise can compute the number of instances to make the split with
NbrInstances =
LEN ( ‘Table’[Original] ) -
len ( SUBSTITUTE( ‘Table’[Original] , “-” , “” )
)
Hi everyone. Thanks very much for your replies. But I still don’t have the solution I need. I am actually working in SSAS so my requirement really is - - create 3 calculated columns off of 1 existing column in my table. I have managed to get as far as the below. But my code breaks as soon as I have missing hyphen… I am struggling to get that part working - can anyone please help?
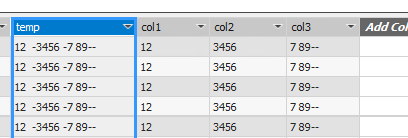
//-------------------------
col1:=
VAR firstHyphen = FIND ( “-”, DimItems[temp], 1, 99 ) //4
RETURN
SWITCH (
firstHyphen,
0, DimItems[temp],
TRIM ( MID ( DimItems[temp], 1, firstHyphen - 1 ) )
)
//-------------------------
col2:=
VAR firstHyphen = FIND("-", DimItems[temp], 1, 0) //4
VAR secondHyphen = FIND("-", DimItems[temp],firstHyphen + 1 ) //10
RETURN
SWITCH (
firstHyphen * secondHyphen,
0, “”,
TRIM( MID(DimItems[temp], firstHyphen+1, secondHyphen-firstHyphen-1))
)
//-------------------------
col3:=
VAR firstHyphen = FIND("-", DimItems[temp], 1, 0) //4
VAR secondHyphen = FIND("-", DimItems[temp],firstHyphen + 1 ) //10
RETURN TRIM(MID(DimItems[temp], secondHyphen+1, len(DimItems[temp])))
//-------------------------
Hi @michellepace.
Here’s another DAX possibility using 4 measures. Count the number of delimiters and then process accordingly.
Delimiter Count =
VAR _CurrentStringToSplit = SELECTEDVALUE( Raw[String to Split] )
VAR _Delimiter = " - "
VAR _DelimiterCount = DIVIDE(
LEN( _CurrentStringToSplit ) - LEN(
SUBSTITUTE( _CurrentStringToSplit, _Delimiter, "" )
),
LEN( _Delimiter )
)
RETURN
_DelimiterCount
String 1 =
VAR _CurrentStringToSplit = SELECTEDVALUE( Raw[String to Split] )
VAR _Delimiter = " - "
VAR _FirstDelimiter = FIND( _Delimiter, _CurrentStringToSplit, 1 )
RETURN
SWITCH(
TRUE(),
[Delimiter Count] = 0,
_CurrentStringToSplit,
[Delimiter Count] >= 1,
MID(
_CurrentStringToSplit,
1,
_FirstDelimiter - 1
),
BLANK()
)
String 2 =
VAR _CurrentStringToSplit = SELECTEDVALUE( Raw[String to Split] )
VAR _Delimiter = " - "
VAR _FirstDelimiter = FIND(
_Delimiter,
_CurrentStringToSplit,
1,
-1
)
VAR _SecondDelimiter = FIND(
_Delimiter,
_CurrentStringToSplit,
_FirstDelimiter + LEN( _Delimiter ),
-1
)
RETURN
IF(
[Delimiter Count] = 2,
MID(
_CurrentStringToSplit,
_FirstDelimiter + LEN( _Delimiter ),
_SecondDelimiter - _FirstDelimiter - LEN( _Delimiter )
),
BLANK()
)
String 3 =
VAR _CurrentStringToSplit = SELECTEDVALUE( Raw[String to Split] )
VAR _Delimiter = " - "
VAR _FirstDelimiter = FIND(
_Delimiter,
_CurrentStringToSplit,
1,
-1
)
VAR _SecondDelimiter = FIND(
_Delimiter,
_CurrentStringToSplit,
_FirstDelimiter + LEN( _Delimiter ),
-1
)
RETURN
IF(
[Delimiter Count] = 2,
MID(
_CurrentStringToSplit,
_SecondDelimiter + LEN( _Delimiter ),
999999
),
BLANK()
)
Hope this helps.
Greg
eDNA Forum - Split by Delimiter.pbix (17.6 KB)
This is freaking brilliant! Would not in a million years have thought of converting this on the fly to a Path hierarchy. Was planning to use a combo of LEFT, RIGHT, MID and SEARCH, but your approach is much more efficient and straightforward.
Mic drop by DAX Mozart!

@BrianJ the solution by @AntrikshSharma deserves a video.
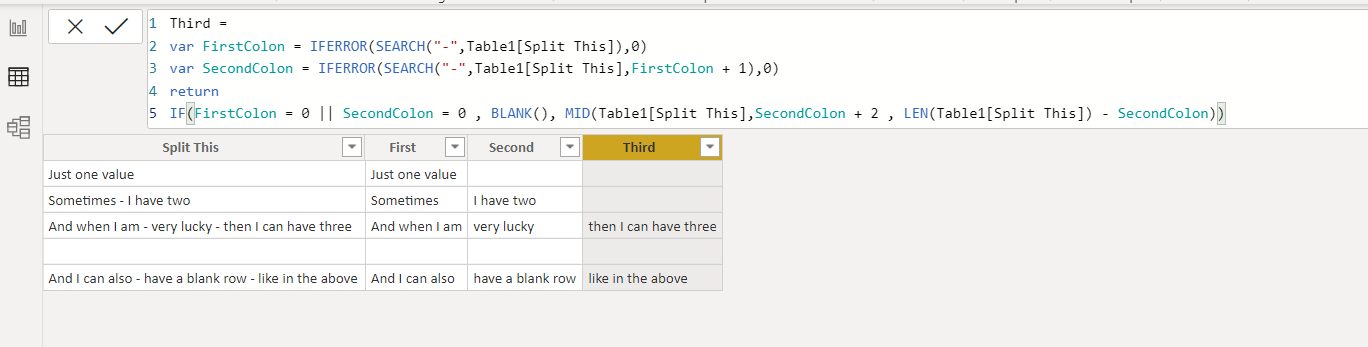
Hello Rajesh, thank you very much for your reply. It was 99% of what I was after. Except there are a few little errors (by 1 character either way). This solution works for me perfectly:
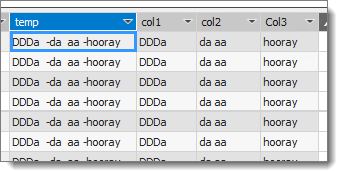
//------------------------------------------------------------------------------------
col1:=
VAR firstHyphen = FIND ( “-”, DimItems[temp], 1, 0 )
RETURN
IF (
firstHyphen = 0,
DimItems[temp],
TRIM ( MID ( DimItems[temp], 1, firstHyphen - 1 ) )
)
//------------------------------------------------------------------------------------
col2:=
VAR firstHyphen = FIND ( “-”, DimItems[temp], 1, 0 )
VAR secondHyphen = FIND ( “-”, DimItems[temp], firstHyphen + 1, 0 )
RETURN
IF (
firstHyphen = 0,
“”,
IF (
secondHyphen = 0,
TRIM ( MID ( DimItems[temp], firstHyphen + 1, LEN ( DimItems[temp] ) ) ),
TRIM ( MID ( DimItems[temp], firstHyphen + 1, secondHyphen - firstHyphen - 1 ) )
)
)
//------------------------------------------------------------------------------------
VAR firstHyphen = FIND ( “-”, DimItems[temp], 1, 0 )
VAR secondHyphen = FIND ( “-”, DimItems[temp], firstHyphen + 1, 0 )
RETURN
IF (
secondHyphen = 0,
“”,
TRIM ( MID ( DimItems[temp], secondHyphen + 1, LEN ( DimItems[temp] ) ) )
)
//------------------------------------------------------------------------------------
sorry that is quite vain - I marked my own solution as the solution