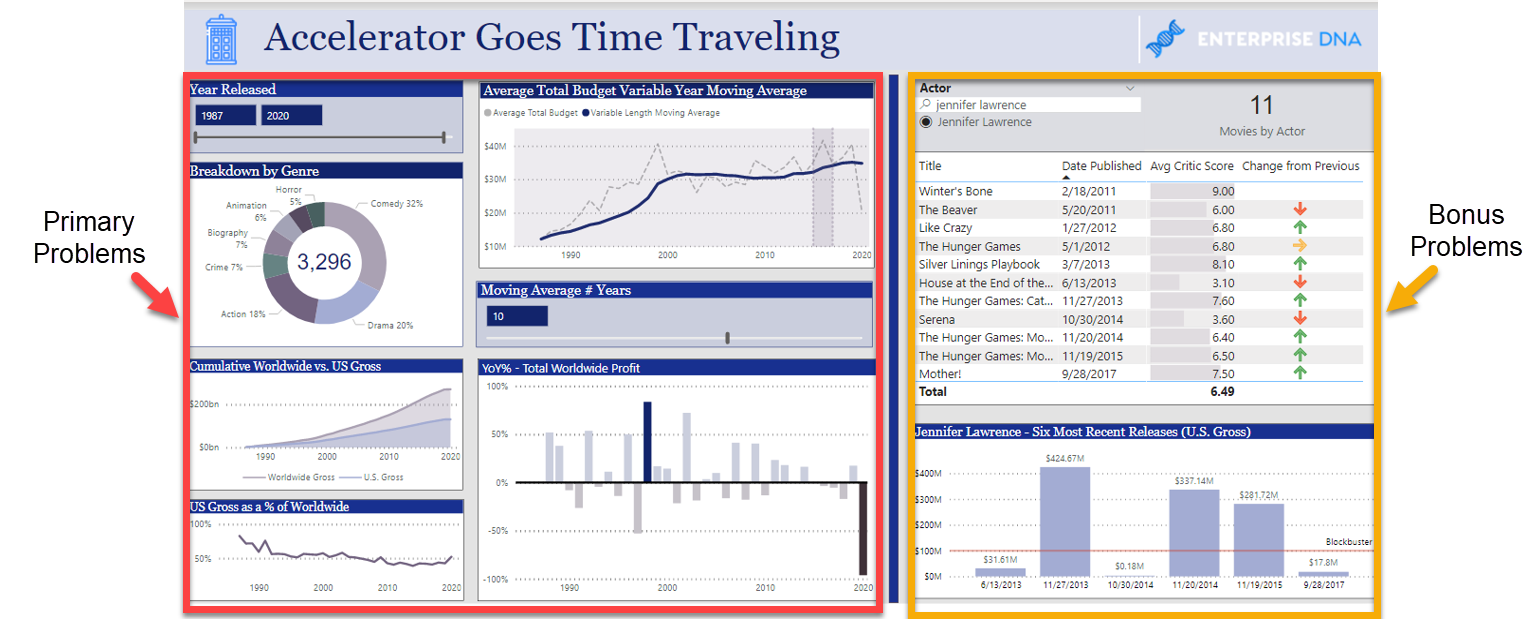
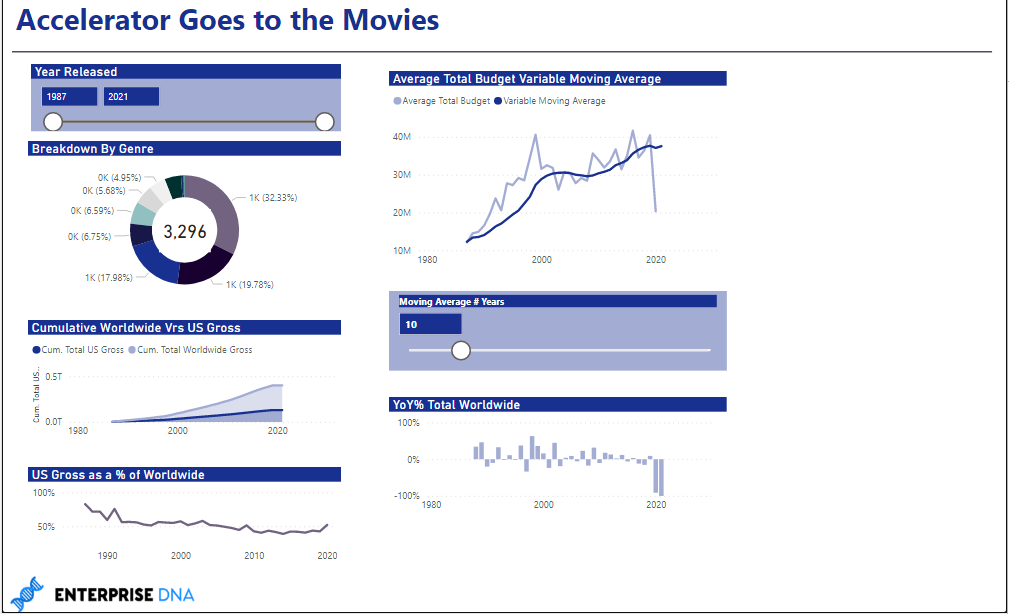
In this week’s Accelerator, we continue our exploration of the IMDB movie dataset, with a particular focus on Time-Intelligence analyses. At some level, these are just applications of the same DAX filter and row context issues we’ve been discussing since the start – they just happen to be applied to time-related issues. However, there are some very commonly used time intelligence patterns that have tremendous analytical power, and this problem set attempts to provide you a quick tour through those particular analyses.
As we continue to assess and revise the implementation of Accelerator, we are trying something new this week - Bonus Problems. The primary problems for the lesson are the ones to the left of the vertical blue line and the ones to the right are bonus problems.
If you complete the left-hand side analyses, you will have met the mission of this week’s exercise and gotten good experience with many of the key TI analyses and patterns. However, for those who want an additional challenge, we’ve added two more questions at increasing difficulty. Please consider these entirely optional, as they will take you well beyond the 1-hour target time.
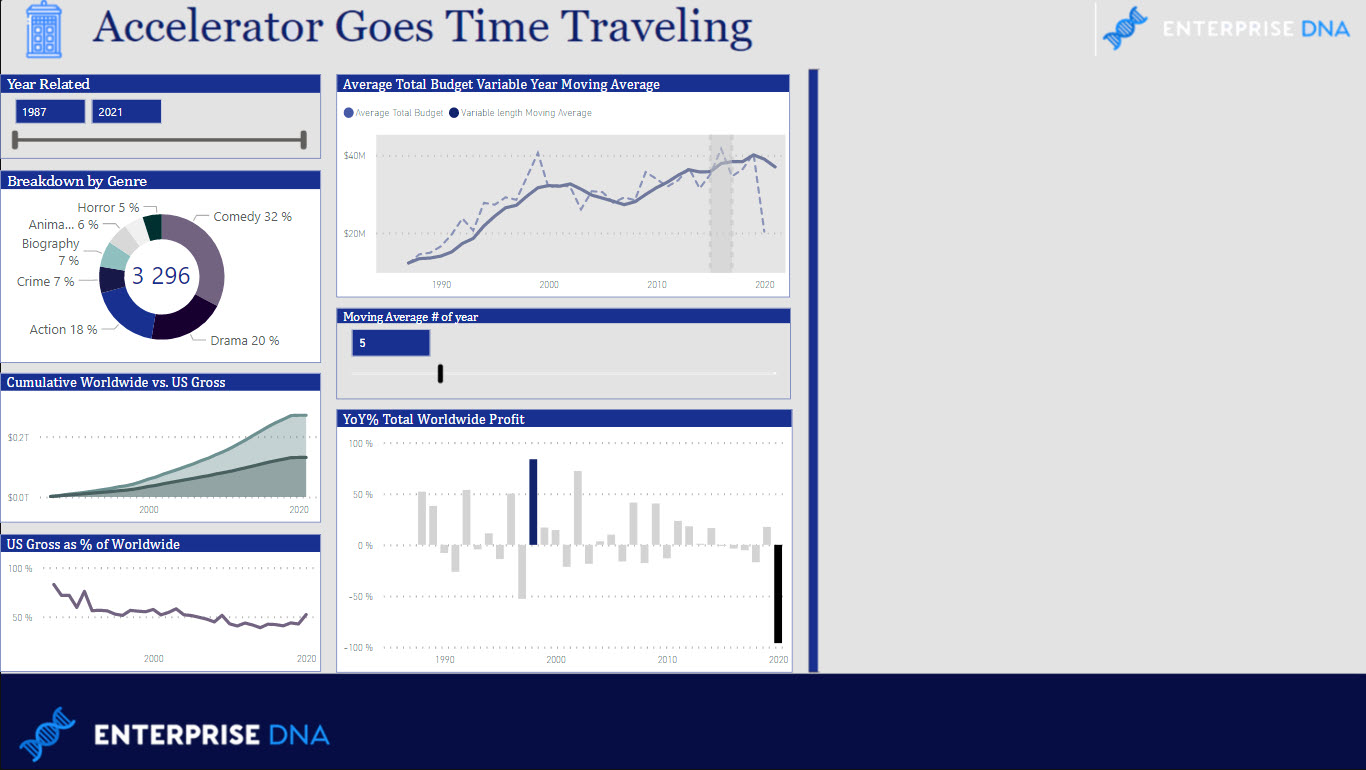
Here’s the Publish to Web version of my solution that you can play around with to explore the various aspects of the problem set.
I’ve tried to include detailed instructions regarding each visual in the attached PBIX, but if anything is unclear, please just give me a shout in this thread.
As always, even if you haven’t been participating to date, feel free to jump into Accelerator at any time. You can find all the past exercises and solution videos and resources here in the portal.
I hope you enjoy this one - I had a lot of fun putting it together. And huge thanks to @KimC and @m.eric for their prompt review and invaluable insight and guidance.
Note that the members-only live solution event will be at 5pm EST on Wed. September 22 (so you’ve got some extra time to dive into the bonus Qs if you’re so inclined…). I’ll post a registration link early next week. Have a great weekend!
Here are the links to the suggested learning resources for Week #5 Accelerator. Particular shoutout to eDNA Expert @Greg whose outstanding DAX Patterns section of the forum likely will be extremely helpful to you in working through this week’s problem set.
The DATEADD Function - The Best and Most Versatile Time Intelligence Function in DAX
Using The Extended Date Table - OFFSETS In Power BI
This Year VS Last Year Time Comparisons & Differences In Power BI
Thank you Brian for pulling this together, it is another great accelerator for us to learn from.
If people have time, I would highly recommend taking the time to try and do the bonus problem. I have learnt so much from it and will be able to apply this to future problems.
Solutions are looking great. A couple of hints on the formatting:
For the constant lines, there is no “between” shading yet, but there is before and after. With a little experimentation, you can simulate a “between” effect.
For 98% of the conditional formatting I do, I base the formatting on field values from DAX measures. In this case, there are four distinct conditions - Max Value, Min Value, greater than or equal to 0, less than zero. Try creating a DAX measure that returns the desired color hex code for each of the four conditions.
Of course, I did not do the job in one hour but I did not encounter any real problem. Before going to each visual I viewed the appropriate resources and all went well.
On the other hand, for the bonus questions I stumble a bit but that’s the goal.
[spoiler] This was fun and a lot quicker to do than expected. Those lessons are starting to stick!
I have started using the tabular editor. It is fantastic and the tutorials are really easy to follow and insightful. Hoping to use it to solve the Aniston problem. As a relative novice to power BI it has been really helpful in laying out measures and being able to see what is actually happening.
When you have a chance, could you please run through this quick poll? I promise it will take less than 2 minutes, but will really help us gauge whether we’re hitting the mark or not on the time and difficulty level of theAccelerator problems sets. Thanks!
I’ve got the Movies by Actor card working, just a count from the actor table. Not sure how to get the titles for that actor. I’ve made a relationship between the 2 on the IMDB ID but that’s going the wrong way. Do I have to make a calculated table or something that is the movies for the selected actor? Not sure how to go about that if so.
Hi @BrianJ
I am done with the Part one of the task and will now be moving onto the bonus problems.
This has been a learning experience and many thanks for that. Some challenges in part one which i encountered and planned to revisit are;
Filtering the genres so that those with less than 2% of the total don’t get shown on the donut chart
The YoY% Total world wide visual is slightly different to yours even when i select the same date range; I will investigate this further as I go through the bonus problems.
OK, confession time on my end. Part of why you’re struggling with this is that the data model for this week’s challenge has some shortcomings. Ideally, the Actor dimension table would be tied to the Movies fact table in a 1:M relationship as per a standard star schema. The problem is that the data in the Actor field of the dataset looks like this:
The issue with this is that to properly shape this data to allow for a 1:M relationship on Actor would have pretty radically changed the structure of the fact table, and blown up the existing measures (don’t worry if this doesn’t entirely make sense - Week #6 is going to be focused on data shaping and we’ll address this in depth - it’s a VERY important and very much under-discussed topic).
So, the bottom line is that we need an approach that allows us to harvest the selected value from the Actor table and apply that to filtering the fact table WITHOUT having a physical relationship between the two tables. Fortunately for us, there are a number of ways to do this. Here’s a video I did a while back that should help you and anyone else who’s wrestling with this issue:
This is actually quite a relevant real world situation. As Sam and I discussed in Week #2, data modeling is an iterative process. Ideally, if I’d been able to accurately forecast what I would need in Week #5 when I put the Week #4 data model together, I would have incorporated Actor into the full star schema. But given that I didn’t, it’s now a choice been what is clearly not a best practice (but will work), and adhering to the best practice, but having to do a major overhaul of the initial model and subsequent analyses and reporting. There’s no right or wrong answer to this question - it will depend on how significant that data is in the overall analyses and reporting, available resources on the project, the effect on the report users of making changes, etc.
Probably a lot more than you bargained for when you asked the question, but I hope this is helpful.