All,
Before getting into the week #2 problem, I wanted to sincerely thank everyone who participated in week #1. The response was tremendous – one of our most popular posts of the year, with lots of participants from all around the world. I was particularly pleased by the way each person adapted their solution to meet their individual training needs. Some executed the problem verbatim, whereas others added elements or chose approaches with a higher degree of difficulty. We have built that individualized flexibility into the problem for this week.
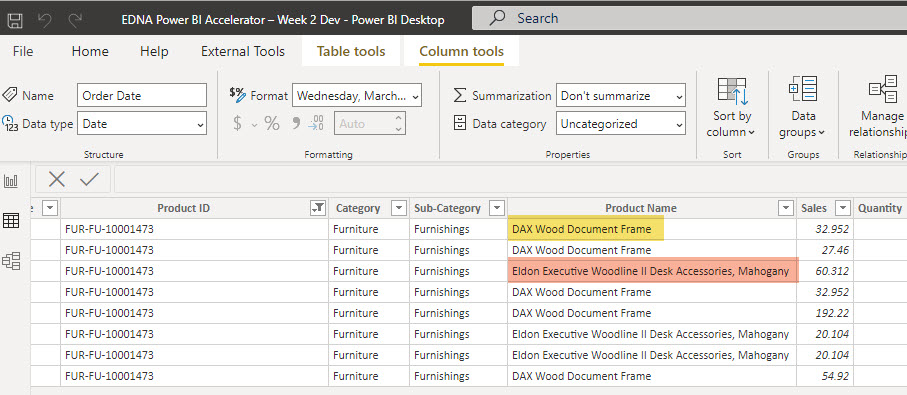
So, speaking of which… this week’s problem deals with a very common real-world scenario in which the client is seeking a detailed analysis, but provides the data associated with that analysis in the form of a single large flat file. Thus, you are required to transform that flat file into a Star Schema dimensional data model before performing any analysis. The attached PBIX file contains all the information you need, including the detailed brief explaining the problem and desired outcome in more detail, as well as providing a list of recommended Enterprise DNA blogs and videos if you need to brush up on any of the skills required to complete this week’s problem. Because you will be doing much of your work this week transforming the original file in Power Query, I have also provided the underlying CSV data file.
We will be conducting the live solution session for this problem on Wednesday, July 21 at 5pm EDT. Registration info to follow soon. Also, you can still click here to register for the live solution session for the Week #1 problem later today. I will be posting my Week #1 solution afterwards, along with a link to a recording of that session.
If you have any questions, feel free to post them on the forum. Also, you are encouraged to post your solutions to the forum so that we can learn from each other, but if you do please use the spoiler alert or summary option to prevent folks still working on the problem from seeing information they would prefer not to.
Good luck with this week’s problem and enjoy. Thanks for participating!
- Brian
P.S. Here are instructions for two tasks that you will need to be able to perform to complete this week’s problem.
Setting the Path of the Source File in Power Query:
- Download the attached PBIX and CSV files
- Open the PBIX file and go to Power Query by clicking Transform Data
- You should see something that looks like this with a yellow error indicator next to Client Flat File:
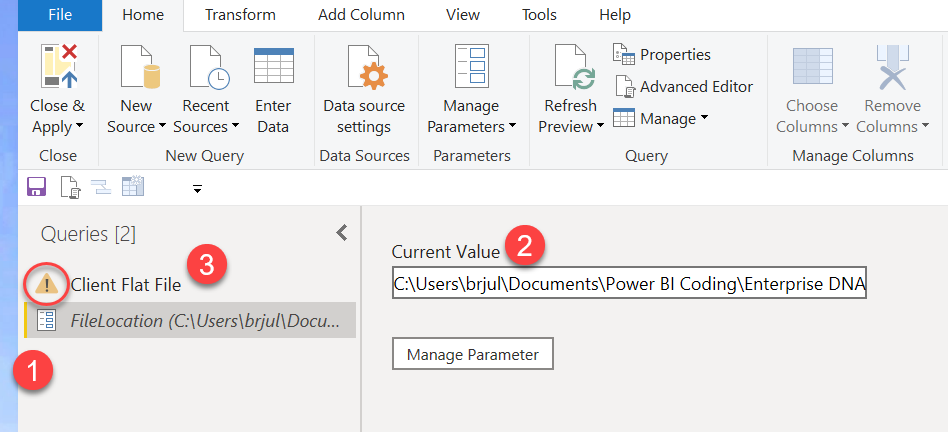
- Click on the File Location parameter
- Then click on Current Value, and enter the full path (no quotes) where you downloaded the CSV file in step #1.
For example, my full path is:
C:\Users\brjul\Documents\Power BI Coding\Enterprise DNA Files\Power BI Accelerator\Week 2\Final Client Flat File.csv
Once you enter you path correctly in the Current Value box, the error indicator next to Client Flat File should disappear, and when you click on that table, you should be able to proceed with the problem in Power Query.
Embedding a Screen Shot of Your Final Data Model
-
When you have completed the data modeling portion of the exercise, hit “Close and Apply” in Power Query and go the data model screen in Power BI (click on the icon below)

-
Take a screenshot of your data model and save the screenshot to your desktop.
-
In Power BI, go to the Solution page of this week’s PBIX file and select Insert and the Image from the menu.
-
Select the screenshot you saved to the desktop in Step #2 above.
EDNA Power BI Accelerator – Week 2 Problem Final.pbix (10.5 MB)
Final Client Flat File.csv (1.6 MB)