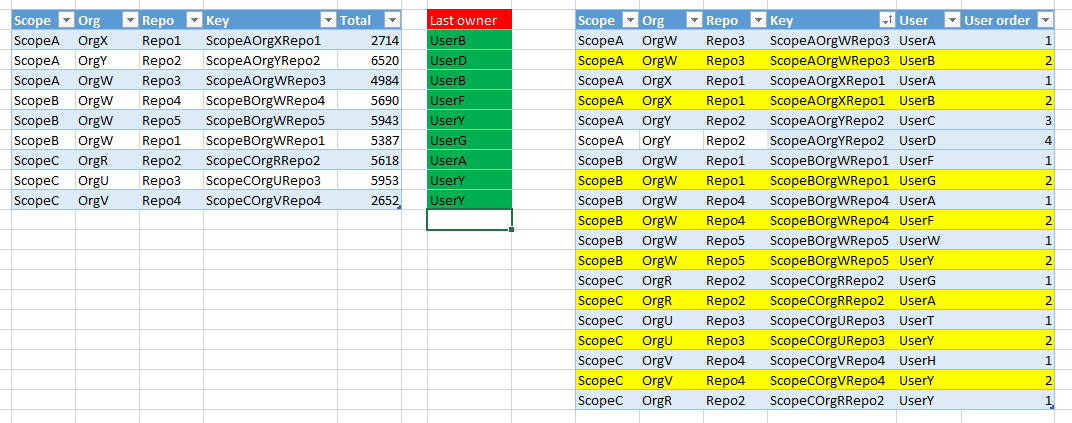
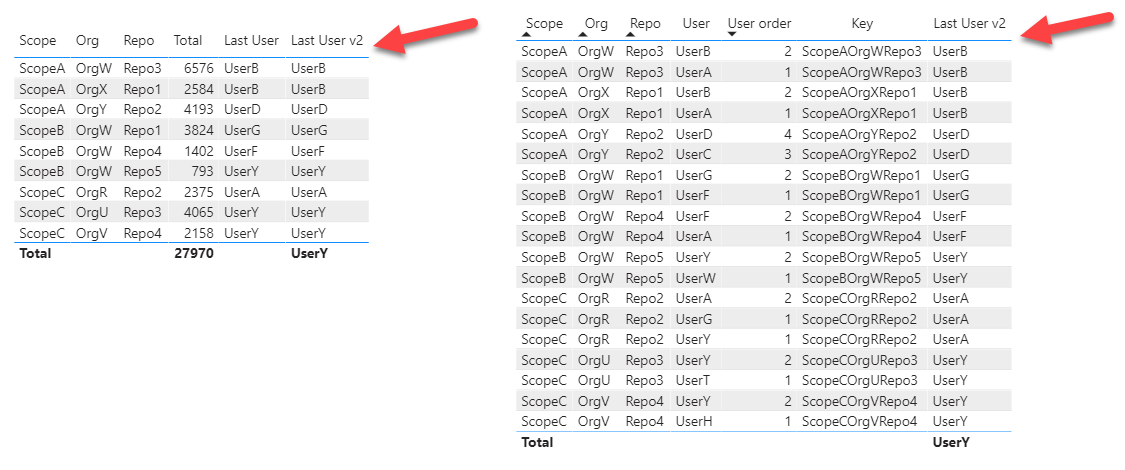
I have a couple of tables, one with a list of repositories which key is the compound of scope, org and repos name and some total, and a user table listing users of each repo. Users have a number indicating the order of the users for that repo (a repo can have then multiple users and a user can be in multiple repos).
I need to get for each repo the latest added user (the user with the higher user order).
I tried using a virtual relation between the two tables using the key as a link, but I cannot get the latest user for that tuple.
May you help?
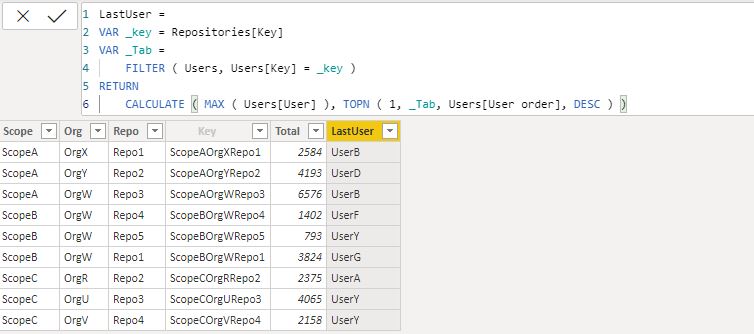
Here is my solution using a measure, not a calculated column. Both solutions are viable, but I prefer a measure over a calculated column as often as possible.
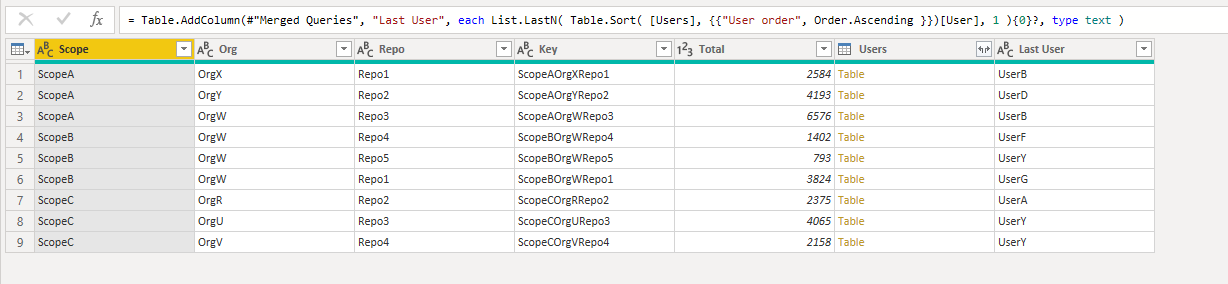
If it’s a Dimension/Attribute then go for the Power Query solution.
From a performance standpoint, always try to push that as far back to the source as you can.
I understand and if there is a performance issue with the Merge the process can be optimized.
There’s a multitude of ways to solve this in Power Query - I guess “cross that bridge when we get there…”
@Rajesh thanks for your elegant solution. My TOPN grasp still needs attention.
So I went through a video where @sam.mckay provides a clear explanation.
Thanks again!
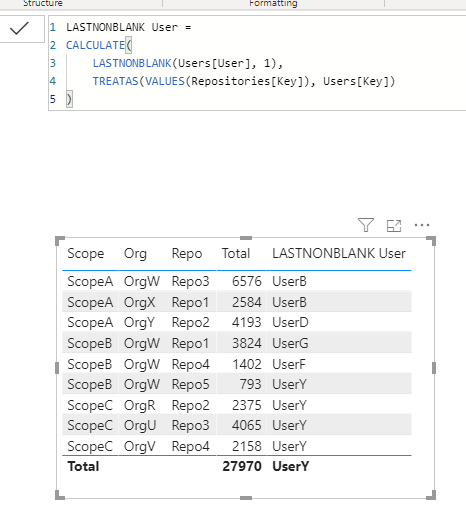
@JarrettM thanks for your kind replay. I do not get how it works (it actually does ).
Does the function lastnonblank relies on some order? User order can be random
In this scenario, slicing is required and it will make building the report easier (focus is on users).
I’ll try both in production where data is massive. Unfortunately, I do simple things, but being the size of data always overwhelming then even if approaches provide the same result, some are not applicable when the going gets tough.
Thanks @Melissa! Your DAX solution will take me some time to be understood. I’ll try also the PQ as well, but as mentioned with large data set I found Power Query is not always the most efficient solution


 ).
).