Hi All,
I am very new to power Bi so looking for some help here
Q. I need to find patient visit volume analysis (visit count by volume distribution by year)
i have the below fields like this
I think you should do a modelling effort before we go further … there are over 1 million rows in your [Medico] table and there is much repeating data. Your main fact table should have one row per event (visit?), and I imagine after you extract all the patient-specific info into its own [Patients] table things will look much better. Also, it seems that there are multiple records per event: for example, although I guess “Chart Number” and “Patient ID” are both meant to refer to a specific patient, for “Chart Number” = 2099 and Patient ID = 87663 there are 15 records, while my first try at putting this patient into a table and counting her/his visits gave 3 visits…
There are also many records where the visit appointment date is about 7 years before the appointment created date (I stopped counting at over 8000 with appointments in 2005 and creation dates in 2012).
So, I’d recommend a new model before proceeding. The initial tables I can see are:
[Dates] - with 1 record per date (you’ve already got this)
[Patients] - extract and remove as much information from the [Medico] table as you can, with 1 record per patient
[Visits] - renamed [Medico] table, with 1 record per visit
Here are the notes I began to keep while taking my first look at your sample:
Setup:
turned off “Auto date-time” option for this report
marked [Dates] table as a date table
changed all date formats to “dd-mmm-yyyy”
deleted existing bi-directional relationship between [Dates] and [Medico] tables
created 1-to-many relationship between Dates[Date] --> Medico[Appointment Created Date]
Please post your revised model and I’ll take another look.
So I took another look at your data … I was not able to identify the work you did to clean-up the model (perhaps the wrong file was attached?) but did a quick re-modelling effort myself anyways as follows:
renamed the [Date Table] to [Dates]
marked the [Dates] table as a date table
deleted all existing relationships
used DAX Studio to export the data from the [Med] table to a CSV file
renamed the existing [Med] table to [Med2]
re-imported the [Med] data to use as a staging table, disabled load (~ 1 million rows)
created reference of [Med] for [Patients], and kept only patient-related columns, then removed duplicate (~ 6800 patients)
created reference of [Med] for [Carriers], and kept only carrier-related columns, added [Carrier ID] index, then removed duplicates (327 carriers)
created reference of [Med] for [Visits], merged with [Carriers] to get [Carrier ID], removed patient and carrier columns except for IDs, then removed duplicates (92525 rows)
added 1-to-many relationships:
Dates[Date] --> Visits[Appointment Date]
Patients[Patient ID] --> Visits[Patient ID]
Carriers[Carrier ID] --> Visits[Carrier ID]
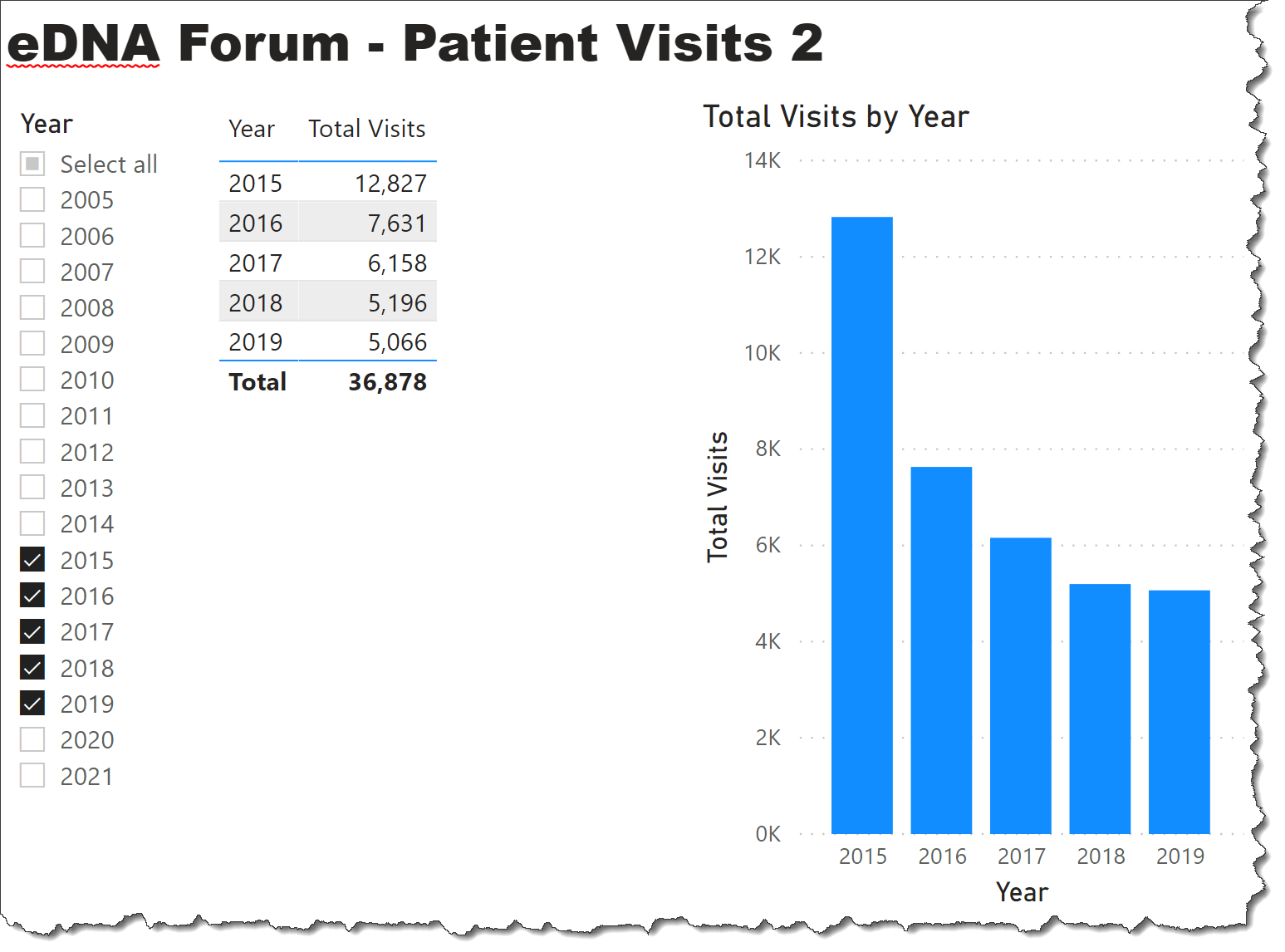
The distribution of visits over the last 5 years that I got was:
So, with minimal modelling I reduced your source file from over 1 million rows to under 100 thousand rows. Given that I don’t know your data, and that my second quick look resulted in over a ten-fold reduction in the amount of data, please re-evaluate your model before we proceed further, and the revised model that should have no duplicate data and, at a minimum:
a [Visits] main (fact) table with only 1 row per visit
a [Patients] lookup (dimension) table with 1 row per patient
a [Carriers] lookup (dimension) table with 1 row per carrier
Could you please explain the below step how you have done …What is staging table ?
re-imported the [Med] data to use as a staging table, disabled load (~ 1 million rows)
Hi @Nagi_k. Staging table is a common term in data warehousing/data preparation. In it simplest form and how it is used here it means a “holding” table that is used to import data only; I was not able to manipulate your data so had to export using DAX Studio and then re-import so I could use the “holding” or “staging” table as a reference. I disabled load as I only wanted 1 copy of the data in the model, and the 3 references I made would pull the data from the 'staging" table as needed.
You shouldn’t need to worry about this, as I hope you can re-visit your source data and vastly reduce the number of rows that get imported when you produce the next version of your data model.
It’s great to know that you are making progress with your query @Nagi_k. Please don’t forget if your question has been answered within the forum it is important to mark your thread as ‘solved’. Also, we’ve recently launched the Enterprise DNA Forum User Experience Survey, please feel free to answer it and give your insights on how we can further improve the Support forum. Thanks!