@BrianJ , once again thank you for the support and time you’ve put in to this - you’ve made my first Enterprise DNA experience top notch, and I hope in future to be able to “give back” in a similar manner!
I’ll put my question here and the rest of my notes below which you can probably ignore 
I am familiar with Snowflake and Star schema, but I always thought they were effectively the same and star points would have further relations.
Question: When we refer to “The Importance of Star Schemas in Power BI” are we actually saying “Try to avoid Snowflake models if you need to analyse core facts by those outlying dimension columns or if there are joins between dimension tables required”?
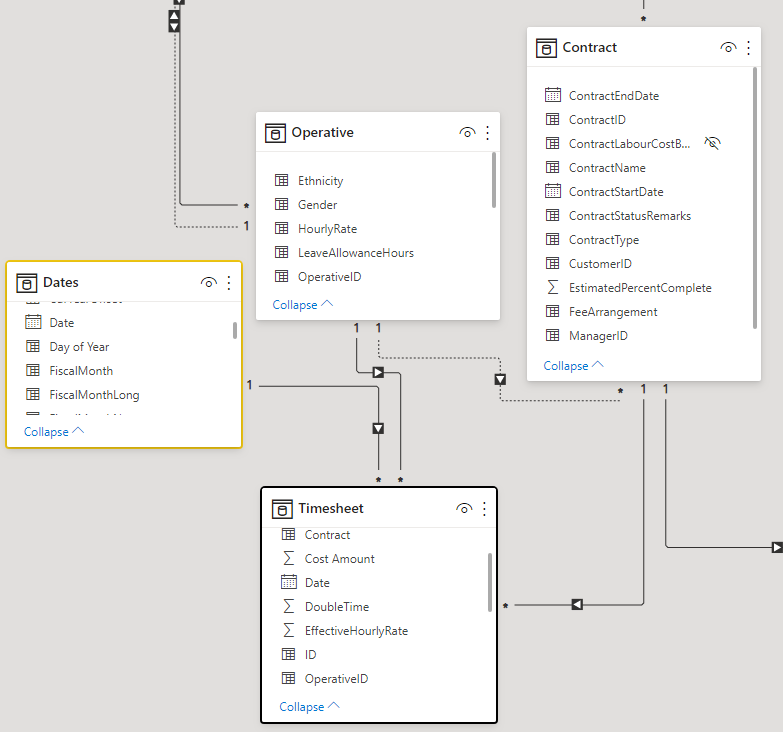
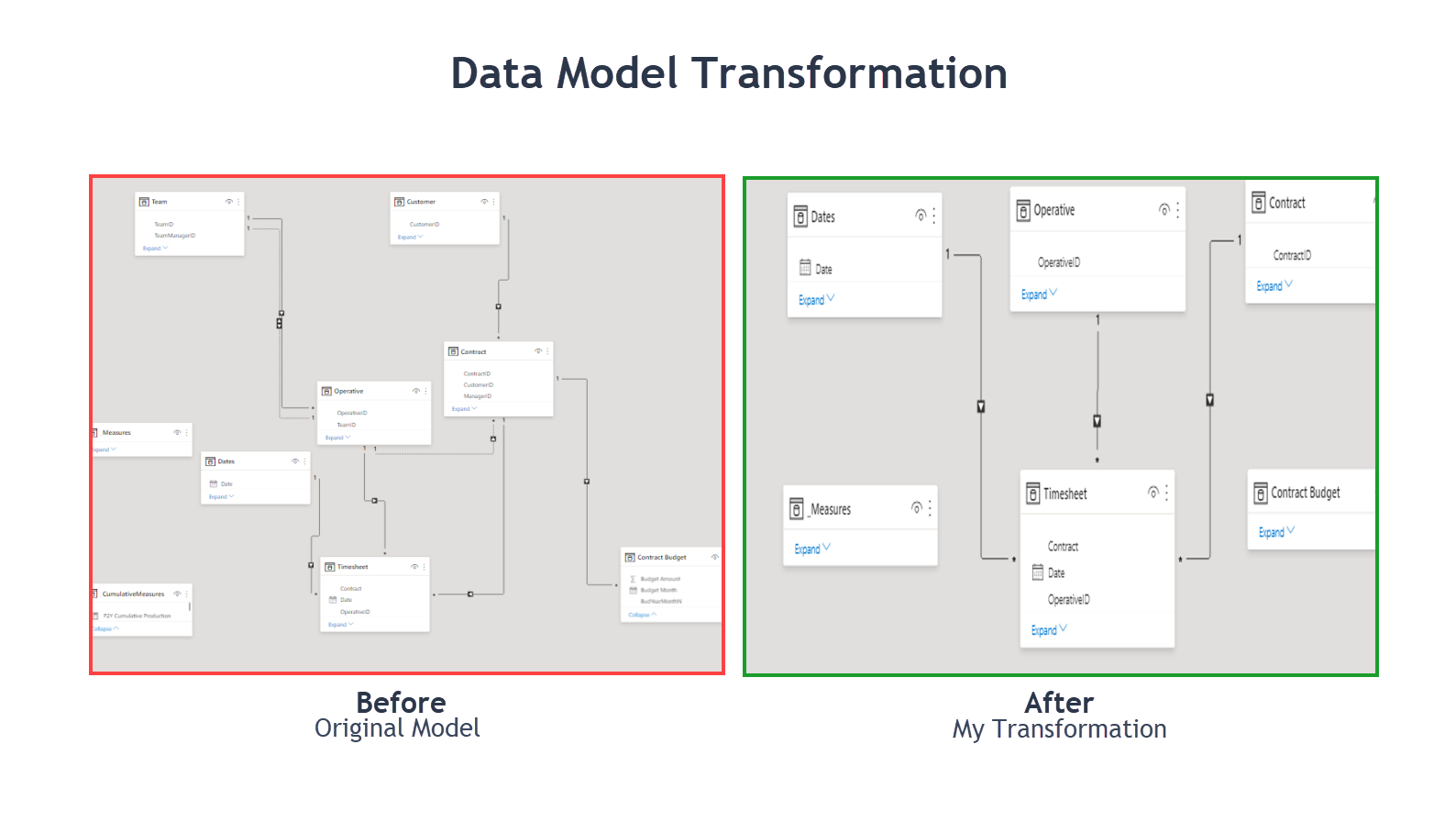
The work you’ve done on the model is what in my old RDBMS-brain I call de-normalisation and I am absolutely comfortable with that - of course when data volumes or dynamics change then other challenges may need to be overcome.
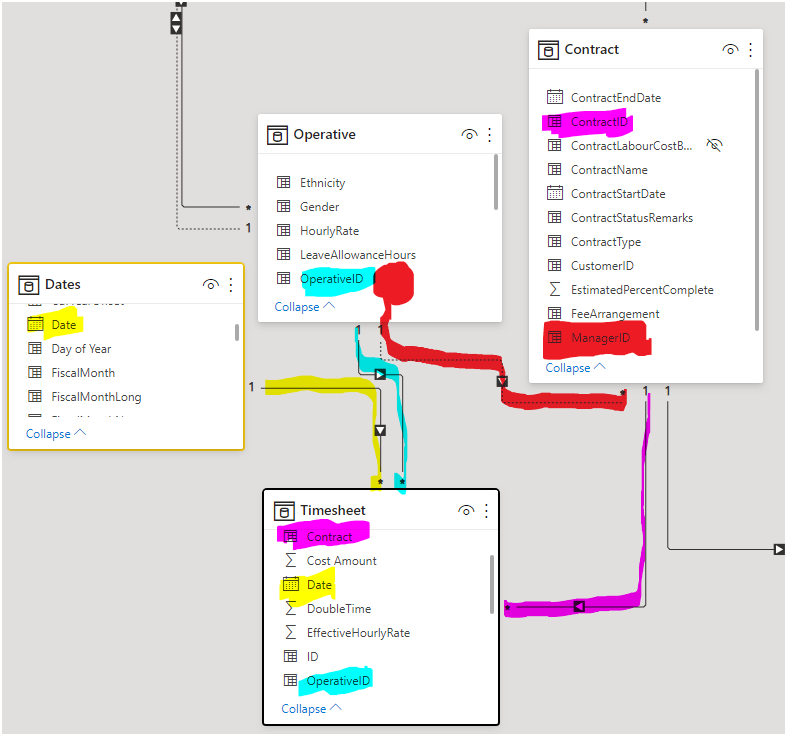
Regarding the re-shaping you’ve done, it’s not quite right but it has given me the answer (Team Manager is not the same as Contract Manager, so I want to see how the Contract Manager (who might also be a Team Manager and an Operative on a job) is performing in managing Contracts under their stewardship).
So, I think I just need to bring the pertinent Operative details for the Manager that I wish to analyse Contracts by over to the Contract table (e.g. set up Contract[Manager Name]) through the data transformation process.
I am familiar with Snowflake and Star schema, but I always thought they were effectively the same and star points would, in my world, almost always have further relations.
Question: When we refer to “The Importance of Star Schemas in Power BI” are we actually saying “Try to avoid Snowflake models if you need to analyse core facts by those outlying dimension columns or if there are joins between dimension tables required”?
Again, thank you very much for your help - I will work through the transformations you’ve done and move forward in that direction.
Matt