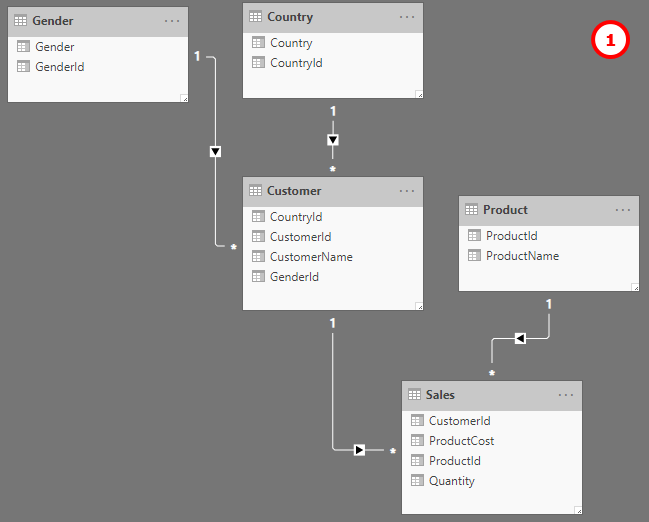
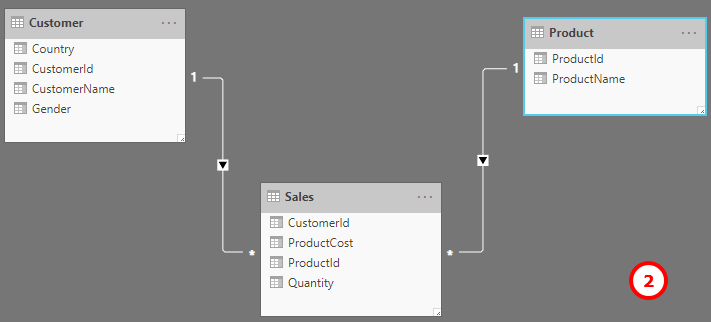
I agree with the above, whenever possible, a star schema is most logical.
However, I am going to add in an argument for Snowflake where appropriate.
Example, in my data set, I have a customer table, each customer has both Ship-To locations, and Departments. These are all dimension tables, my fact table tells me which customer ordered the product, for the specific Ship-To location and Department.
Sounds simple, right? 
Okay, but here’s the twist, a customer might have Ship-Tos A, B, C, & D - and Deparments 1, 2, & 3
Sales can be to any combination of those 4 Ship-Tos and 3 Departments, so if I normalize the customer to include every possible Ship-To and Department combo, for that one customer I will have 14 rows (12 for combos that include both Ship-To and Department, with another 2 for those that have only one of the two).
And, because this is a real-world scenario, yes, I have to go to the Ship-To/Department level, and I have additional detail columns for each.
In this case, with address columns for the Ship-Tos, Contacts (and additional info) for both Ship-To and Department, that really does bloat my customer table to be much larger than it needs to be.
And in this case, yes, I did it - I had 20 additional columns, and multiple rows for each customer, and it was a SLOOOooooW mess. So, I took a weekend, reconfigured to a snowflake, and things were much smoother.
So, yes, sometimes, it just ‘depends’ - try for a star schema whenever possible, but don’t close yourself off to the idea of a snowflake schema if things seem to be too slow.