R or Python would definitely be a good option. I’ve done a little web scraping with R and then extracted it to an Excel file. While I haven’t used R or Python as a datasource in Power BI - this is an option. So I would anticipate that a script could be built and then pasted into the PBI datasource.
This is timely. I have a video coming out this week on building a web scraper in Power Query to iterate over tables. With some custom M, PQ is a really powerful and flexible web scraper.
This is a more advanced version of the scraper I build real time in the video:
@Tanzeel - can you please send the url for the site you want to scrape from, so that I can take a look at how complex the iteration might be?
It will first post on YouTube (be sure to subscribe to the eDNA TV channel) and then also be incorporated into the portal site here. I know the video editor was working on it this weekend. I’ll find out what day it’s expected to post and let you know.
It’s always wonderful time for me to contact you.
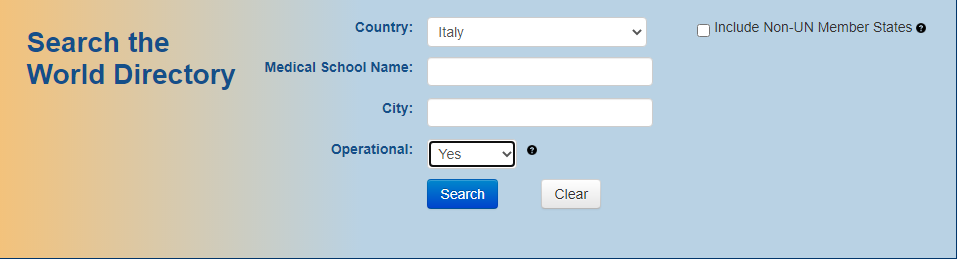
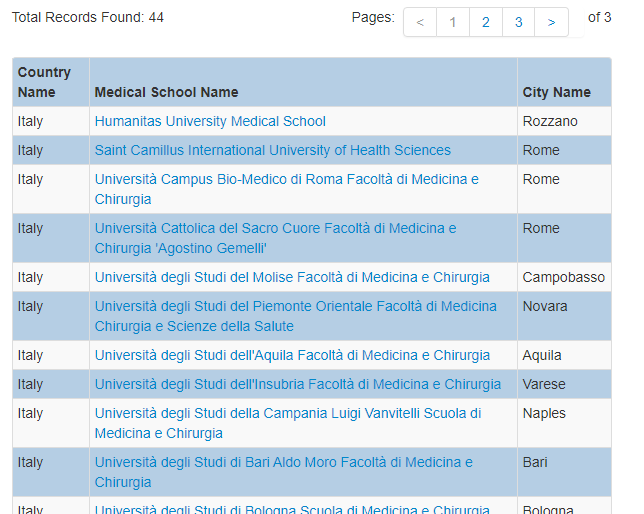
For simplicity and to understand the mechanics of web scraping, I think to use the https://search.wdoms.org/. It seems easy to pull out the data due to systematically data entries.
For my project, I want to scrap the www.uettaxila.edu.pk for faculty members CV from different departments. A sample link is as follows: https://web.uettaxila.edu.pk/EED/faculty.asp#faculty. The power query scrapper should hit every faculty member profile and collect data from each tab like https://fms.uettaxila.edu.pk/Profile/ahsan.ali
It will be great learning to tame the power query to do this wonderful project.
Hope you’ve been well. Always a pleasure working with you, and you never fail to provide interesting questions.
Thanks for the info you provided – exactly what I needed. In looking at the structure of the websites you want to scrape, at first glance they seem to have a clearly discernible, consistently repeating pattern which makes building an iterative web scraper much easier.
Let me do some work on this tonight, and I’ll get back to you late this evening hopefully with a full solution, or at least a clear path forward.
Okay, I’ve been working on this one for a while and it’s going to be much tougher than I originally expected for two reasons:
The bigger problem is that the website you want to scrape is created with ASP.net which doesn’t play very well with the Power BI web connector… The tables containing the faculty information you want to scrape don’t show up directly in the Power Query source step. I did a bunch of research on this, and there is a very relevant article by Gil Raviv about a technique called Children Expansion that looks like it will work here. However, I’ve never used it before and it takes a pretty deep dive into the HTML code to implement it properly. Thus this is going to take me significantly longer than expected to develop a solution for you.
A second substantial problem is how the site generates the individual faculty pages. For faculty with more than a first name, last name (many of them…), the site does not consistently adhere to one specific pattern. This is not as big a problem as #1 above, but also not trivial to address.
So, not nearly as quick and easy a solution as it originally appeared, but some good learning opportunities for both of us.
I understand the underlying issues. Due to it, I chose this project as was stated “For simplicity and to understand the mechanics of web scraping, I think to use the [https://search.wdoms.org/ ]. It seems easy to pull out the data due to systematically data entries”.
In my mind, it could be the starting point.
At first glance, the wdoms.org pages appear well-behaved from the standpoint of building a web scraper, but in fact are probably more difficult than uettaxila.edu pages. There are two main problems, one of which I know how to address, and one of which I don’t (yet).
At the record level, the contact information is not organized in tables, therefore the MS web connector doesn’t recognize the elements on the page:
So, at this point I have no idea how to differentiate these two pages for the purpose of iterating through the country table, but I suspect there’s a way to do it.
I think third option suits us as it will help me in establishing the basics of power query as scrapping tool. If possible, then we may take something from LinkedIn such as CVs of friends etc.
Unfortunately, LinkedIn is not a good choice because Microsoft institutes a number of measures to try to actively block web scraping from the site unless you are a Company Administrator. However, I did find a good example site (Harvard Medical School) that is ill-behaved enough to be interesting , but well-behaved enough to be scrapeable with some fairly straightforward adaptations to the standard approach.
I have built and implemented the scraper for the site, and attached a copy at the end of this post. Here’s the basic information I scraped. The unfiltered table was over 15,000 rows, but included admin staff, lecturers, students, etc. The final filtered table contains only professors, but as you can see many professors hold multiple appointments so the number of unique individuals is far fewer than the 5000+ rows of the filtered table:
Here are the general steps I took in creating this:
First I tried to scrape the department URLs, in order to form the table over which we would iterate to pull together information for all departments. Here’s the departments page: https://hms.harvard.edu/departments
This initial scrape did not work, however, using the “Add Table Using Examples” I was able to get Power Query to properly scrape that table from the page.
Then went to the “People” section of the first department and tried to pull the faculty information off that page. That partially worked, and I was able to get about half the information on the page. Again using the “Add Table Using Examples” function, I was able to pull the remaining information into a second table.
I then took the two tables created in #2 above and turned them into functions that would iterate over the table created in #1. If you’re not sure how to do this, I’ve got a video coming out on YouTube next Tuesday that explains this process in detail, and/or you can examine the M code in the file below for the two functions created.
After executing both functions, I referenced the scraped table created, renamed it Professors and filtered the title field down to only those records that contained “Professor” somewhere in the title.
Then through a combination of transformations of the URL and mail to: fields, I created two new fields in the Professors table – one for department to allow filtering/slicing the data by department, and one for email that just cleaned up the formatting from the web scraped mail to: field.
I hope this is helpful. Please let me know if you have any questions and how you’d like to proceed from here.