Hi all,
I have a ‘Data Validity’ requirement to filter a fact table, so that is shows records where we have an ‘Invalid Combination’ of dimensions. This is where the business has provided some rules saying we should not have any records where DIM A has a value of X and DIM B has value of Y.
My problem is trying to find an efficient way to do this as the fact table is relatively large at 5M rows and I would like to avoid adding a new column.
Please see attached mock up where I have I tried to replicate the issue: Invalid dimension combinations.pbix (181.3 KB)
We have two Dim tables: Regions and Customers and a Sales fact. The table below shows the number of Sales, split by Region and Customer Type:
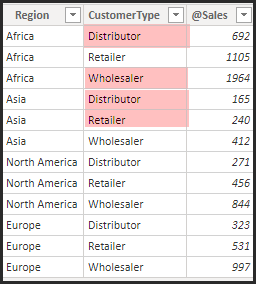
The rows in red are what we could classify as a Invalid Combo, so:
- Africa should only have Retailers.
- Asia should only have Wholesalers.
- North America and Europe can have any Customer Types
I tried creating a simple measure which returns 1 where the invalid combinations are found:
Invalid Combo Check =
var __Region = MIN(Regions[Region])
var __CustomerType = MIN(Customers[CustomerType])
RETURN
IF(__Region = "AFRICA" && __CustomerType IN {"DISTRIBUTOR","WHOLESALER"} , 1,
IF(__Region = "ASIA" && __CustomerType <> "WHOLESALER", 1,
BLANK()
)
)
This works fine in my Matrix:
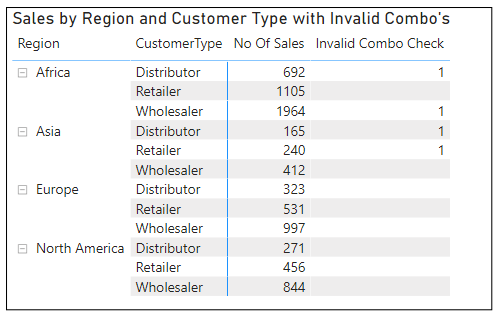
And I can also add the measure into my Sales Detail table, allowing me to report the problem records to the users:

Whilst this appears to work well on this small mock up dataset, it performs very badly on a 5M row fact table as it has to iterate through each row to check the combinations. Also in reality the rule set is much more complicated.
Can this be achieved using a measure?
Many thanks as always,
Mark