I reworked the data model as follows to conform to a classic star schema ( dimension tables connected to fact table by unidirectional, one-to-many relationships):
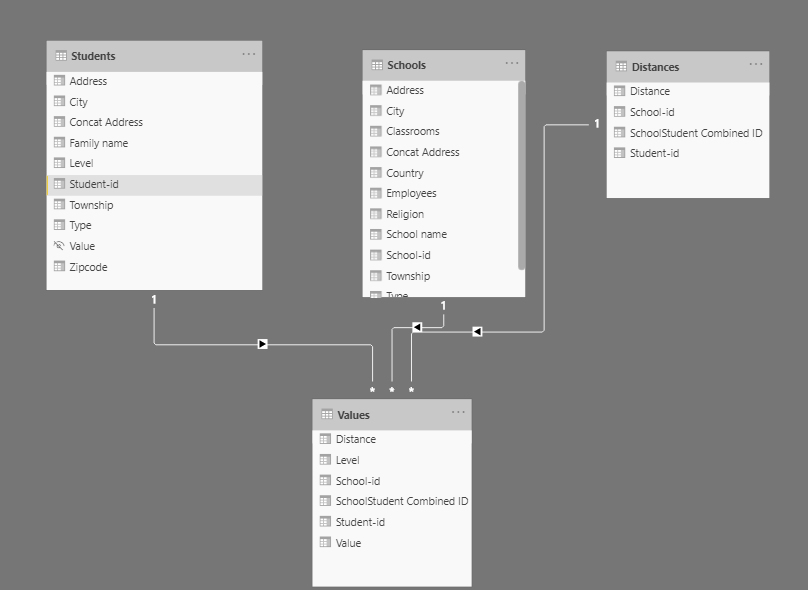
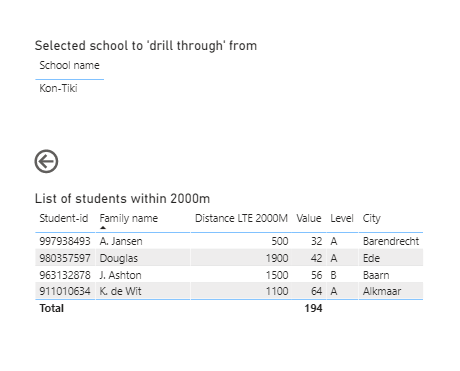
As anticipated, this made the DAX very easy to rework to meet your requirements, and I believe all the tables and drillthroughs are now working properly:
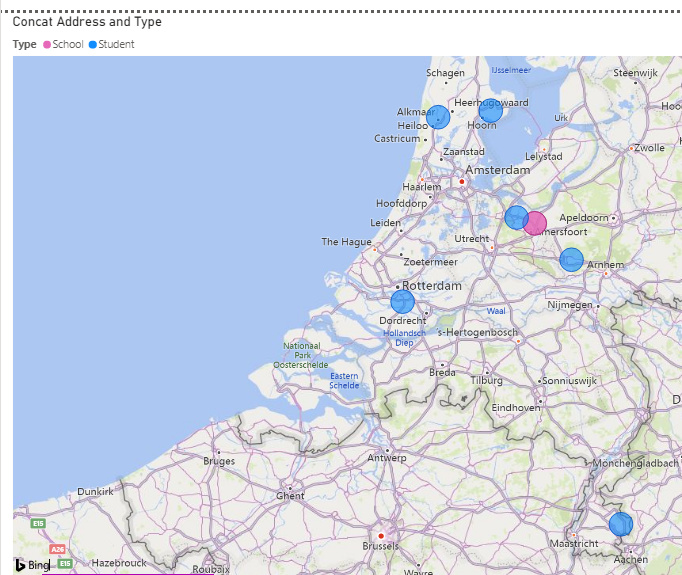
The one thing that still seems funky is that when I map the school and student locations, the two schools seem located right on top of each other, yet the distances from each student to each of the schools are quite different.
Hope this correctly meets your requirements. Full solution file attached.
- Brian
eDNA Forum - School Student Drillthrough Solution.pbix (123.7 KB)