I would like to ask for some help with a DAX measure that is supposed to be used for a drill through.
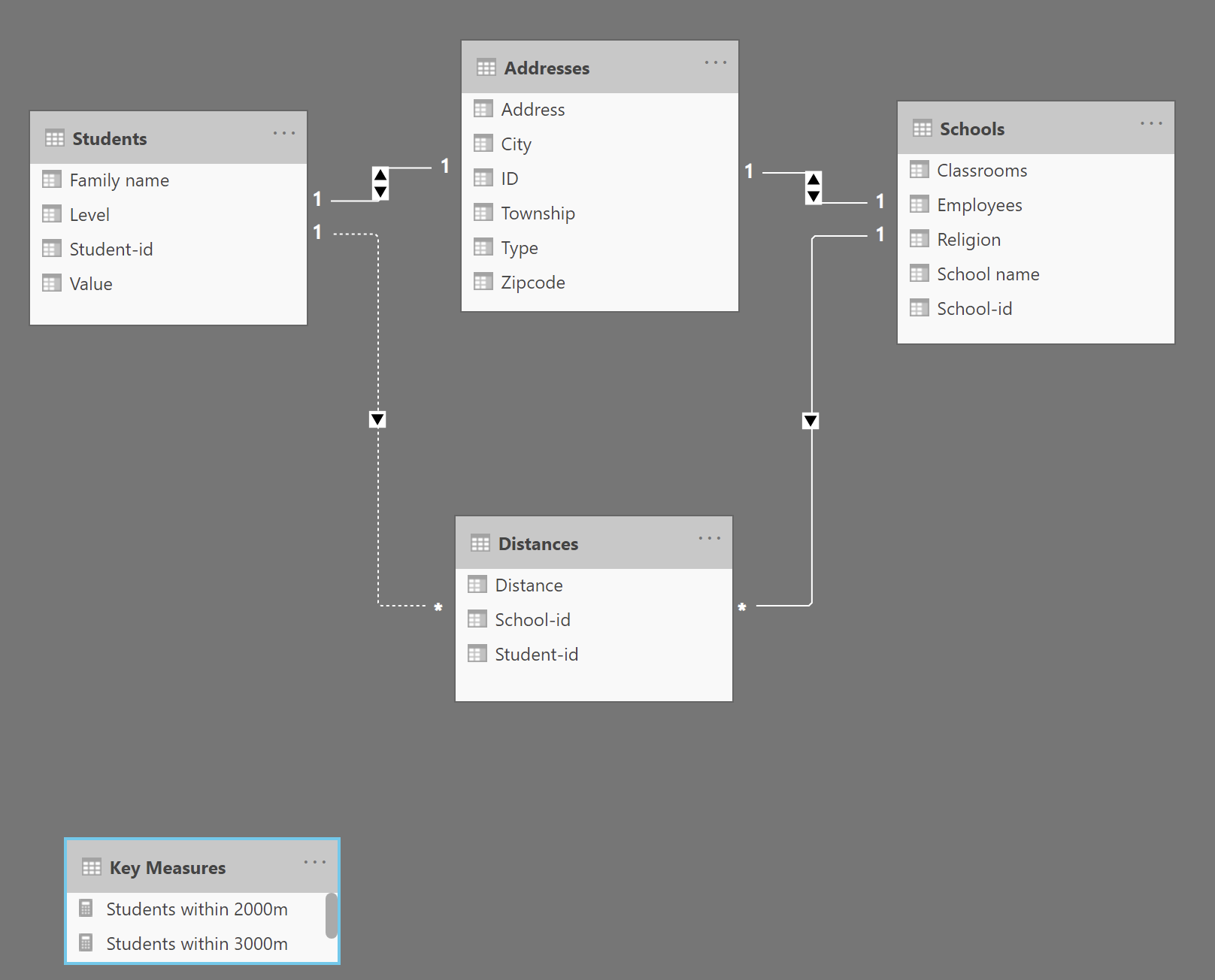
My data model consists of a table for all schools, a table for all students, a table with all addresses of both students and schools and a table with the geographical distance between each school and all of the students.
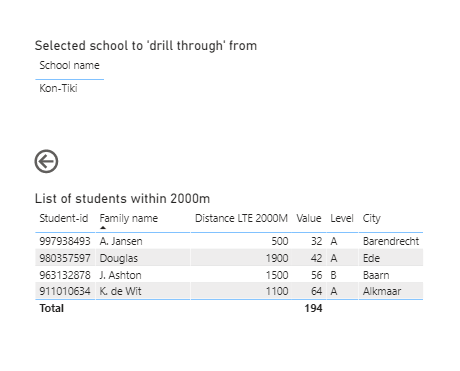
And the idea is to present an table with all schools in it and the number of students living within 2000m and the sum of the value of all students living within 3000m, with the option to drill through on both items in order to see the list of students who meet that criteria.
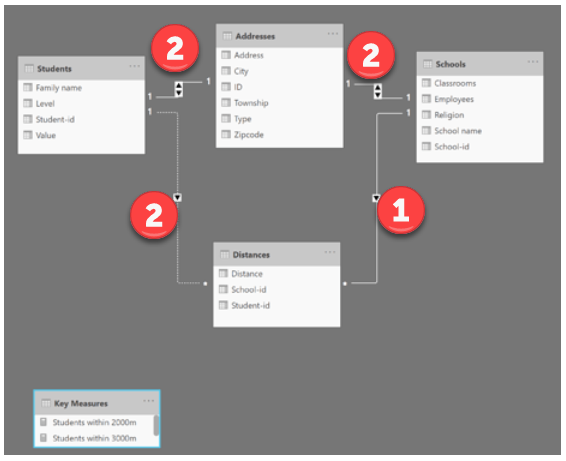
This is what the tables and data model looks like:
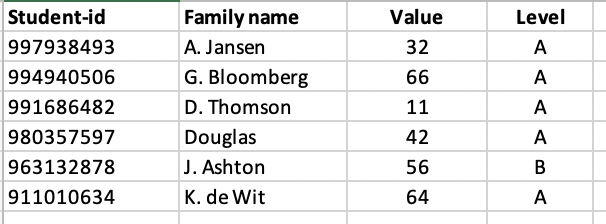
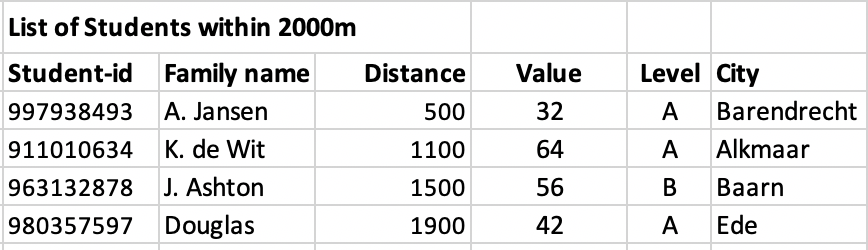
Students:
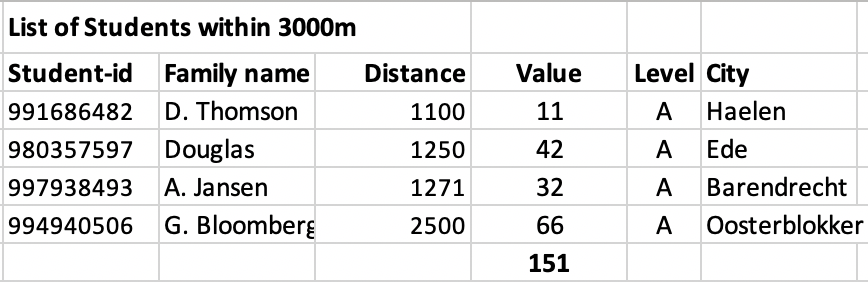
The question is to develop a DAX measure for the Number of students that have a distances less than 2000m from each school and a DAX measure for the Total Value for all Students that have a distance less than 3000m from each school.
In the attached pbix-file I defined a DAX measure for the Number of students within 2000m of each school. The Dax-measure for the total value seems to inappropriate. And also the drill through pages are not working properly.
Thanks for a great explanation of the problem, as well as posting your PBIX file - that all makes it much easier for us to provide prompt and quality support.
From first glance, I can already tell that the first major problem here is your data model. Because of the way you’ve set up the bidirectional relationships and the table entities, every relationship has an alternative path, which violates the desired data model design, and creates ambiguous paths which can cause unpredictable and incorrect results, even if the DAX itself looks correct. For example, getting from the Schools to the Distances Table can be done directly via path #1, or indirectly via path #2. In addition, you have distances in the role of Fact Table, but distance is clearly a dimension of a different table. Let me take some time to rework the data model and review the DAX. I think with the proper data model this should all fall into place relatively quickly.
Thanks for the initial hopeful response. I am not sure if I follow you on the issue of fact and dimension for the distance table. This distance table is generated by calculating the distance between each school and student. And even the distances between each of the schools. Although I left these out for simplicity.
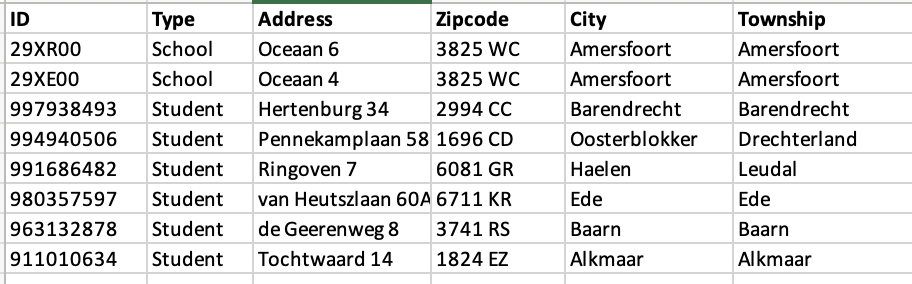
I guess that the seperate address table with a 1 : 1 relationship with both the students table and the schools table causes some question marks. The reason why I designed the data model like this, has to do with the fact that I like to show both the students addresses and the school addresses in one map visual. This requires all addresses to be in a single table.
Hopefully you can work it out without redefining the tables themselves.
Dimension tables represent “things” (e.g., students, schools, customers, locations, products, etc.), the aspects of which remain fairly stable over time
Fact tables represent “actions” (e.g., grades/scores being achieved, claims being processed, sales being made, persons being hired), the aspects of which change constantly
How distance is calculated is not really a key factor in the modeling stage. The more relevant aspect is does it change regularly over time (no) and how does it relate to the other entities in the model?
If you haven’t already, I would very strongly recommend you go through the following course start to finish, which is an outstanding primer on the fundamentals of developing a strong data model to serve as a foundation for your DAX and visualizations.
The map will be no problem to create under a revised data model. However, if you have other specific requirements, please let me know and I will take those into account in building the revised data model.
In this case, values (which I assume are akin to scores/grades) are the main component of the fact table. These are what change over time, and schools, students and distance (either separately or as part of the other dimension tables) are dimensions of value.
Should have something back to you later this evening and we can discuss further.
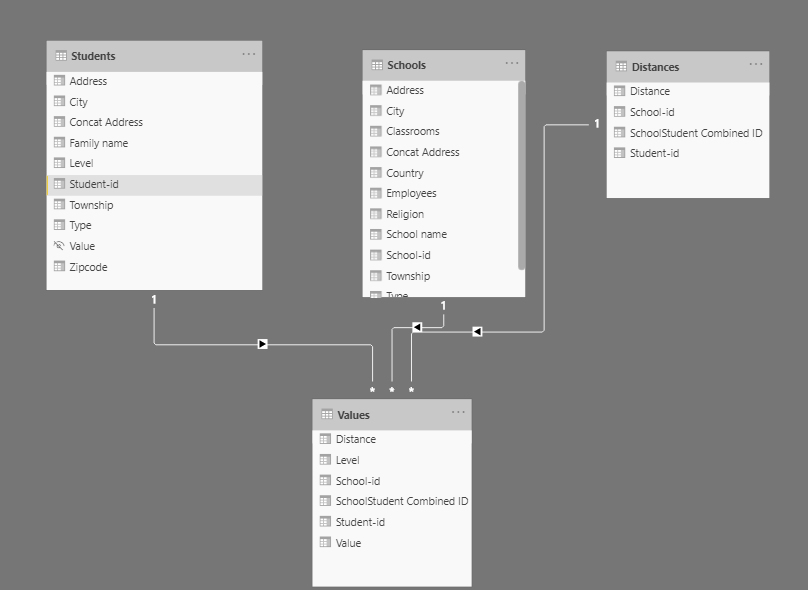
I reworked the data model as follows to conform to a classic star schema ( dimension tables connected to fact table by unidirectional, one-to-many relationships):
As anticipated, this made the DAX very easy to rework to meet your requirements, and I believe all the tables and drillthroughs are now working properly:
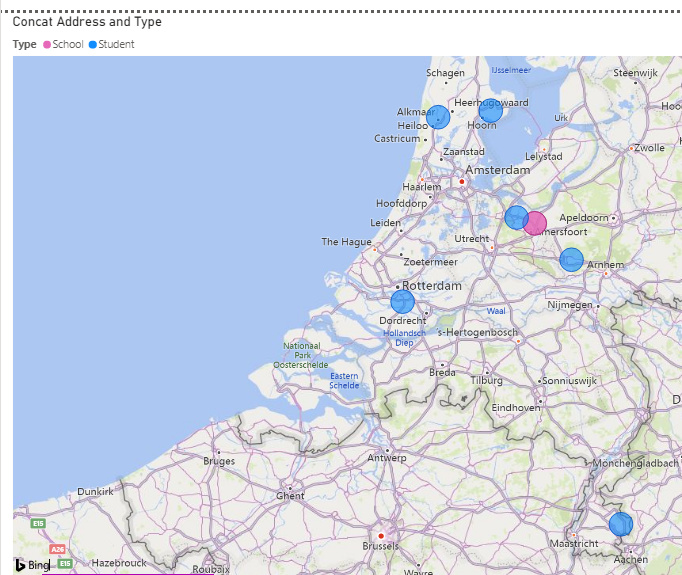
The one thing that still seems funky is that when I map the school and student locations, the two schools seem located right on top of each other, yet the distances from each student to each of the schools are quite different.
Thanks for working this out so thoroughly. We might have to speak a little more about the data model as you confused me a bit, although there might be also a misinterpretation of some data. I recognise and agree fully with your view on Fact tables and Dimension tables. But I developed this stylised data model as the original data model contains a few more tables not relevant to the question and it is completely in Dutch. Therefore I took out the relevant tables and translated it all in English. In reality the data model deals with schools and supplying companies instead of students. In fact the data model is like a Yellow Pages containing rather static information. Therefore there are no actions or transactions in the model.
For the sake of our discussion we can just forget about the Level and we can consider Value as the seize of the students head or something else which is as static as there home address (as long as it is a numerical value that can be summarised). In the original data model Value represents the capacity of the supplying company which is exactly as static as their address. I had hoped to simplify the question by having it represented by schools and students instead of having to explain much about the meaning and relationship between the schools and the supplying companies.
The original data model consists of 8.000 schools and almost 30.000 supplying companies. That’s why I combined all addresses deliberately into a single table in Power Query as I don’t want to burden the performance of my report with making a union in DAX between such large tables. But as far as this drill through question goes, I can live with you suggestion to bring back the addresses to the original tables.
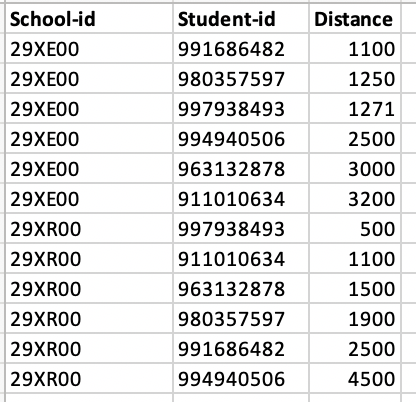
My problem sits with the two distances tables. If we forget about the column Level and rethink the column Value as a static aspect of each student and bring it back to the Student table, I am left with two almost identical tables.
Perhaps the meaning of the distances is a bit more relevant. In my original data model I calculated the distance between each possible combination of both schools and supplying companies up to a distance of max. 5000m. So I took all 38.000 addresses and cross joined them with each other, calculated the geographical distance and filtered the rows with a distance less than 5000m. This results in a table with some 700.000 rows. This means that I calculated the distance between each possible combination of a school or supplier and any other school or supplier. For the simplicity of the question I brought this back to just the distances between a few schools and some students. (And I just copied some random distances, therefore the funky outcome in your map )
This means that in my original distance table in the column School, each School-id will occur multiple times and in the column Students, each Student-id will occur multiple times. Therefore I recognised a 1 to many relationship between the School table and the Distance table and also a 1 to many relationship between the Students table and the Distance table.
Regarding this additional background information, and the wish to neglect the column Level and bring back the column Value to the students table, my question is if we still need two identical tables holding the distance information? In my original data model this would imply duplication a table with some 700.000 rows!
Can you adjust the report so that you adjust the table Values for the columns Level and Value and integrate it wil the Table Distances?
Thanks very much for the additional info/clarifications. I have called for reinforcements on this one - @Paul is going to take a look at where we are currently on this and respond, since he is an expert on both GIS analysis and transport issues (and I am 0 for 2 on those topics).
Hi Sebastiaan,
Brian asked me to jump in given the Dutch connection
We are both somewhat lost in your question, what do you mean by “drill through” here. In the previous post you referred to distance and we wonder, is it still the distance calculation that you are after?
In that case, did you consider to calculate the distance with a measure, thus avoiding building tables. Your measure would only calculate in the context of the filtering that you apply in a visual.
If you have not yet worked out the distance measure pattern let me now and I post it.
Thanks very much for taking the baton on this one.
Per the “Dutch connection”, one of the things I had to fiddle with for a while was the Dutch address format. The students mapped OK right off the bat, but the schools kept showing up on Cape Cod, MA for some reason until I concatenated the entire address and added “NED” at the end. Still have no idea why that happened, but I finally got the schools located on the correct continent…
My pleasure @Brian, I always pre-geocode my data, otherwise you cannot rely on the accuracy, because you cannot see what has happened in the geocoding process. Adding an ISO code for country will help if you have not got lat/lon.
Bas,
After the two posts on this subject and our pc, only now I fully understand your requirements and the complexity of explaining the model. @BrianJ did a great job, but lacked the context of the actual problem setting and model.
In this situation, your original pbix showing a few of the relationships (1 to 1) is correct, use SUMX and USERELATIONSHIP to harvest the value via the inactive relationship.
For the distance I would like to refer to:
both the calculation and the visualisation of a “from” and “to” point are explained.
You will have to test whether your PQ methodology for the distance calculation is overkill or not. In my view, in this specific case, I would use a DAX measure to calculate the distance “on the spot”, given that subsequently a calculation will take place in the context of the filtering visual.
Now, on opening the pbix, PQ is working overtime to calculate distances you do not need and given the millions of possible combinations it will take very long.
I try to elaborate a bit further on the measures you created in your solution. But to do so, I need a bit more explanation about the DAX formula’s you created. Please allow me to ask some question about your code.
In the measure Num Students within 2000m you use CALCULATE and DISTINCTCOUNTNOBLANK where I came up with “COUNTX ( FILTER (Distances, Disctances[Distance] <= 2000….”. Can you explain why CALCULATE and why you choose DISTINCTCOUNTNOBLANK?
In some other measures you also refer to DISTINCT. Is that standard approach or is there a reason to expect multiple or blank values on Students or Distances, etc.?
I find the measure "Distance LTE 2000m’ difficult to understand. The purpose of the measure is to filter those students who have a distance less that 2000m to the selected school. First of all I don’t understand why you use SELECTEDVALUE. If the user lands on this drill through page by right-clicking a particular school, there’s already a filter that’s being kept for that particular school. So if the drill through page consists of a table relating to all schools , only the school in the filter will remain? Or not?
And can you explain how this CALCULATE formula works? Does it work like this: If the distance for the selected school is within 2000m, than the returning value is that particular distance, else return blank and only consider schools where the name equals the selected school? It somehow feels like it’s ‘overdone’ as the school is already selected and we only have to filter all students with a distance less than 2000m for the school that’s already being filtered on.
It’s great to know that you are making progress with your query @Sebastiaan. Just a friendly reminder, if your original question has been answered within the forum it is important to mark your thread as ‘solved’. If you have a follow question or concern related to this topic please start a new topic. More details can be found here - Asking Questions On The Enterprise DNA Support Forum.



 )
)


