Quick question about data model and slicer behavior.
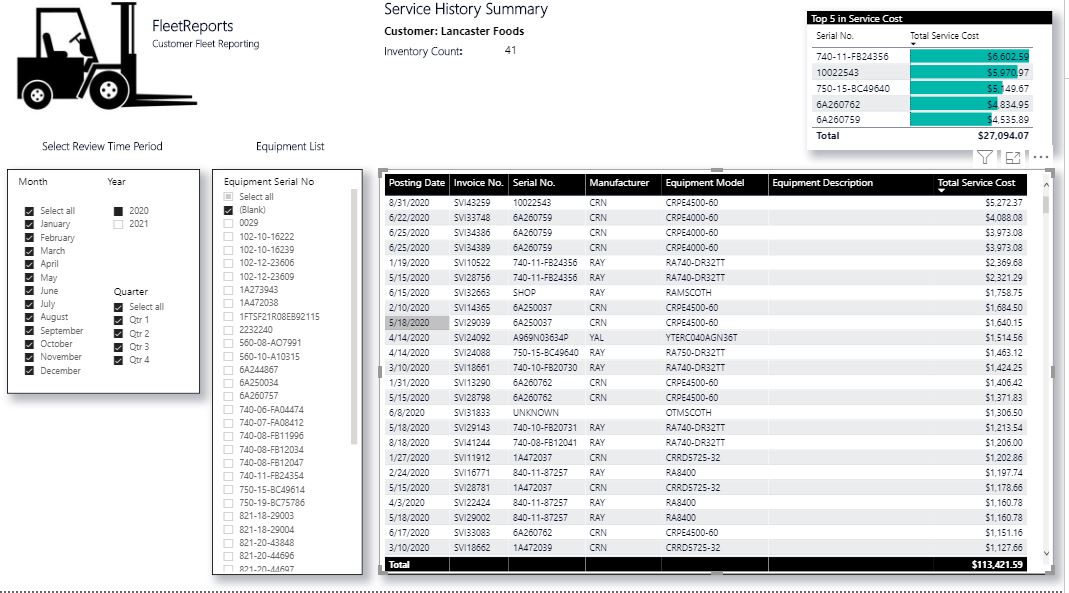
I have a table that is a list of Serial numbers. I have a table that is a list of invoices that contain a serial number as well. The relationship is a one to many that I have set up. But I am trying to understand one thing. In the Equipment list of serial numbers if I build a slicer, all serial numbers are displayed. In the invoice table there are a few invoices that have no serial number (bad data). I noticed that a value of “blank” shows up in the Equipment list slicer. When I break the relationship the “blank” value goes away. Also when I select the “blank” value in the Equipment list slicer visual the invoice visual displays all the invoices and not the one with the blank serial number. Not clear on why this happens. Any help would be appreciated. Attached is pbix file.test.pbix (1.2 MB)
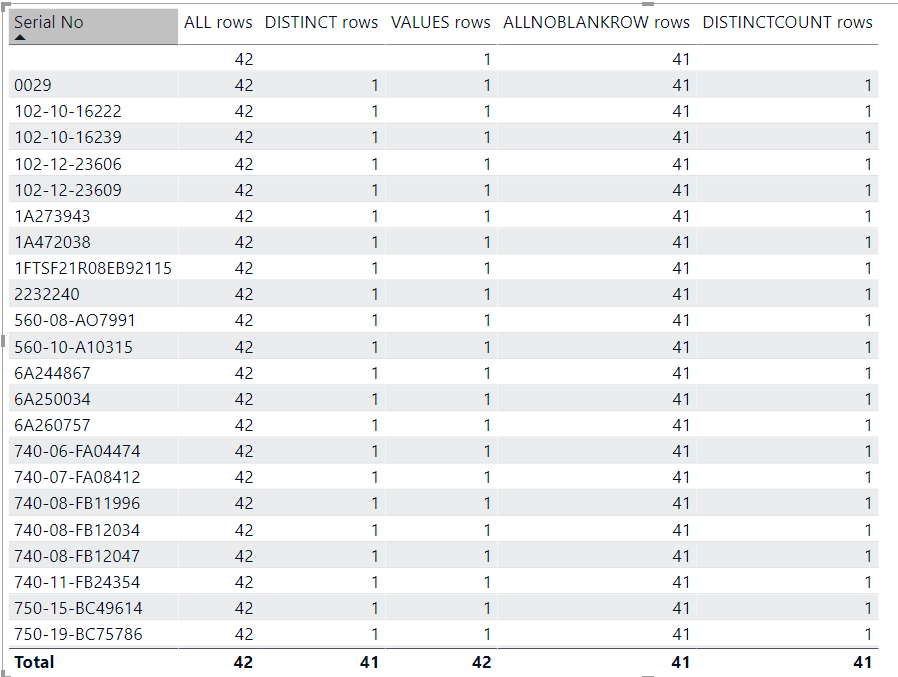
@lomorris In case of missing relationship from the many side a invisible blank row is added to the One/Dimension side so that any row that doesn’t matches from many side with the one side is aggregated under blank(), now there are few functions that makes use of that blank row, such as ALL () and VALUES ()
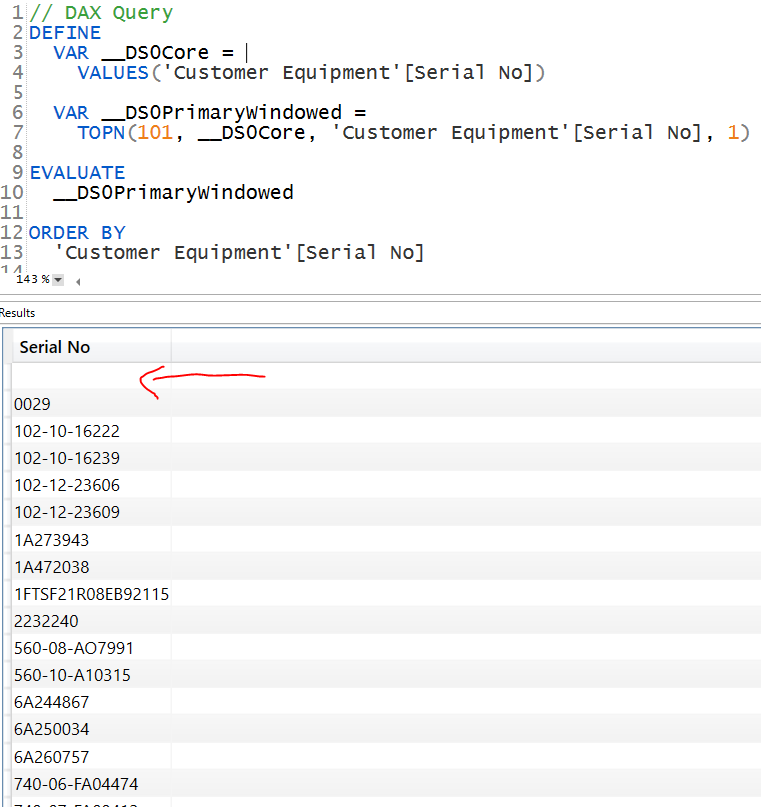
Here is the query generated by that slicer:
DEFINE
VAR __DS0Core =
VALUES('Customer Equipment'[Serial No])
VAR __DS0PrimaryWindowed =
TOPN(101, __DS0Core, 'Customer Equipment'[Serial No], 1)
EVALUATE
__DS0PrimaryWindowed
ORDER BY
'Customer Equipment'[Serial No]
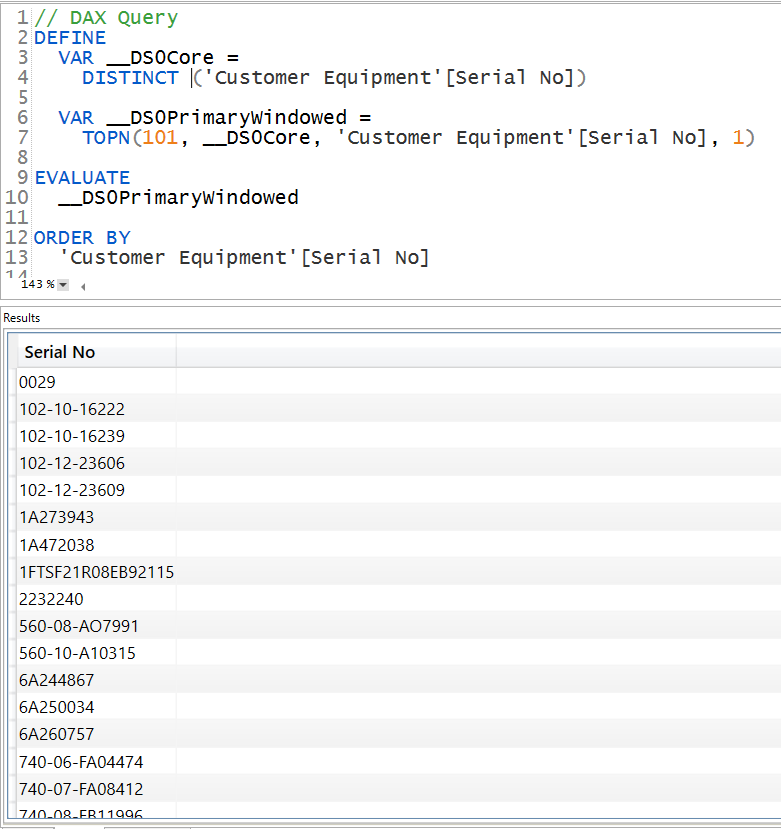
When you break the relationship, engine doesn’t add any invisible blank row to the one side, therefore you don’t see a blank value:
There are 105 Distinct Values in your Cost table (fact) and 41 Distinct Values in your Customer Equipment (Dimension), for those 64 values there is blank row added in your Customer Equipment table.
Thanks, I was able to quickly determine that I had bad data in in this case transactions with missing serial numbers. I can updated the table to correct the values, but ultimately I will have to go back to the data source to get those records updated.