Dear All,
I am really confused that how to do following tasks:
1- Not easily able to do tasks such as finding Standard Deviation etc.
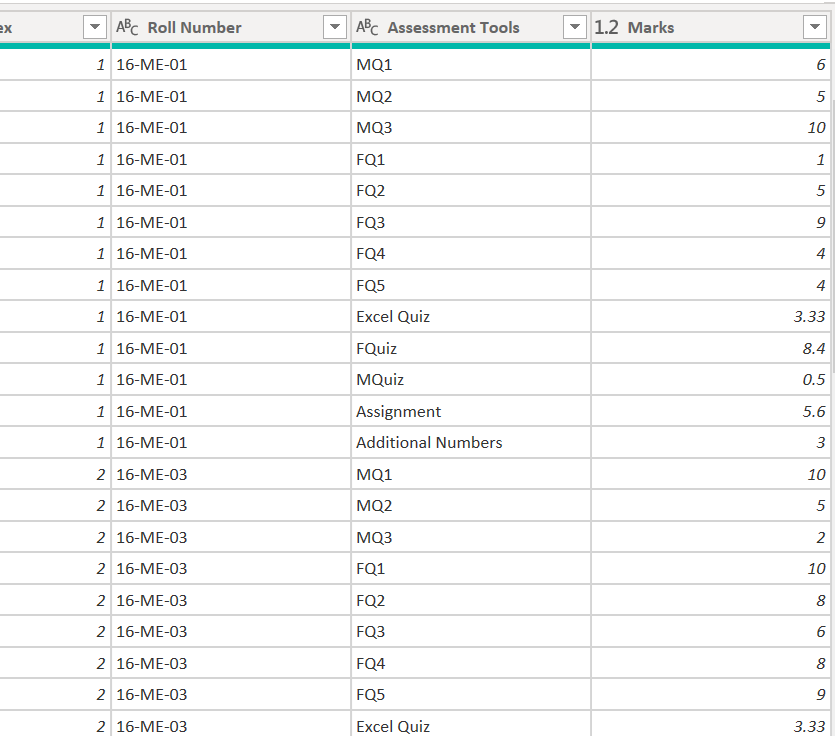
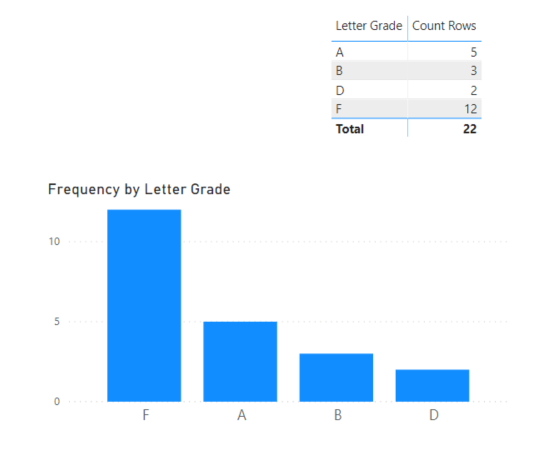
2- Histograms and data rank categorization need calculated columns by row distinct value to assign grades to the students.
Should I use such duplicate table or not? I am really surprised that how it’s so difficult to do some simple tasks in unpivoted fact table? I might be totally wrong. Please guide me.
@qasimjan1018
Thanks. I have seen and made the Histogram by using Flat Table Calculated Column ranking categories. But I have to trade-off on various Visuals syncing.
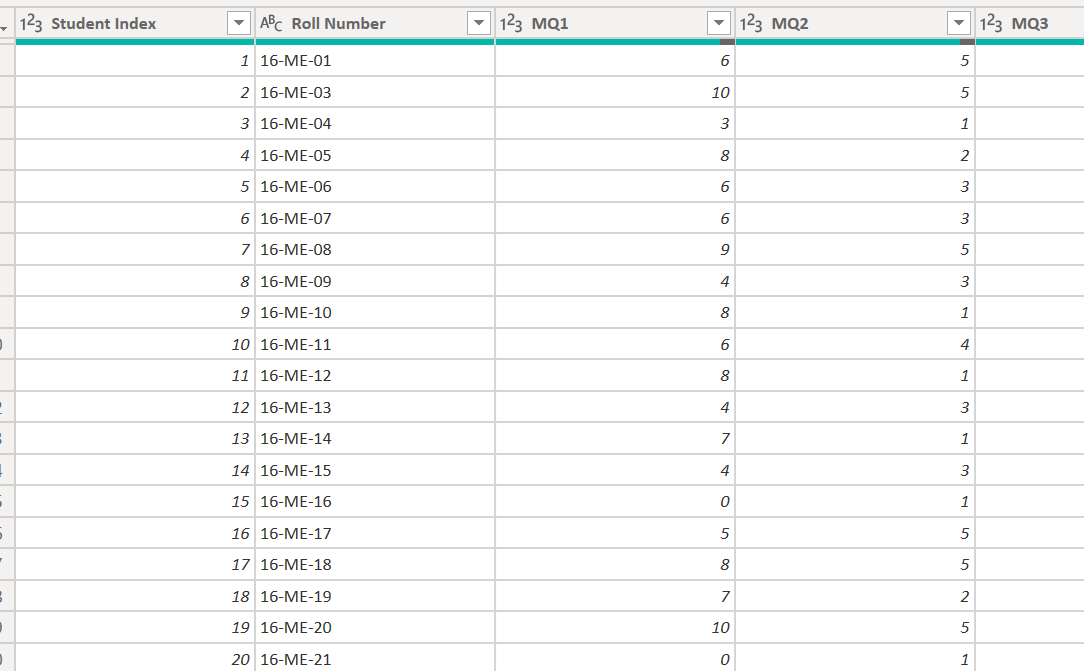
I think your calculations will set up well with just the first table. You’ll obviously need a full data model, with student and assessment tools dimension tables, but the long and thin structure provides tremendous power when you add the appropriate context. For example, means and standard deviations can be done through just applying AVERAGE or STDEV.S to your Marks column, and then putting it in context in visual:
It also sets up very nicely if you want to filter on a specific assessment tool:
Standard Dev FQ4 =
CALCULATE(
STDEV.S(Data[Marks]),
FILTER(
Data,
Data[Assessment Tools] = "FQ4"
)
)
Through the application of filters, context and in more complex cases virtual tables, this structure is incredibly powerful and I think should allow you to do what you need without a second fact table.
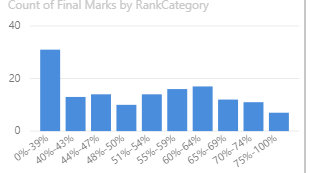
The long and thin structure also supports well the creation of histograms. Here I used a SWITCH( TRUE() ) construct to categorize scores into letter grades, and then a COUNTROWS measure to tally the number of scores in each grade:
I am really thankful to you for your prompt and invaluable support. I’m, nearly, completion of the model.
I am facing the issue to calculate the Overall Standard Deviation. I think it should be between 15-18 based on students score. But my poor DAX always gives around 2.5 to 4 (I think it is not taking the student’s Total marks due to filtering the any of Assessment Tool .
Moreover, I have written many dozens DAX Measures and always tried to escape from Calculated Columns. In some cases, it’s really hard to think the DAX due to very limited knowledge.
Further, Currently, I used the Measure to grade the students rather adding calculated column in ‘Final Result’ Fact Table. So, CountRows doesn’t seem the option.
Regards,
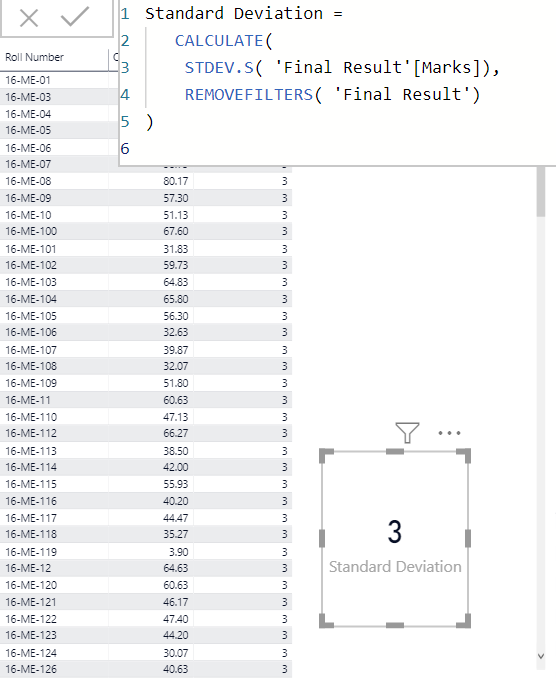
This should work for you. It calculates the sample standard deviation, removing all filters applied to the data table. Note that ALL can be used anywhere REMOVEFILTERS is, with exactly the same result (although the converse is not true). I just prefer REMOVEFILTERS because I think it’s more descriptive.
Std Dev Sample REMOVEFILTERS =
CALCULATE(
STDEV.S( Data[Marks] ),
REMOVEFILTERS( Data )
)
(Note: I wasn’t sure from your question, but if you want to calculate standard deviation by student, use ALLEXCEPT (instead of REMOVEFILTERS) to remove all filters except for the one on Roll Number.
You are definitely right to tip in favor of measures over calculated columns. However, calculated columns do have a very useful place in the DAX toolbox. I typically use calculated columns (or alternatively Power Query custom columns) when the attribute is: a) something I might want to slice on; and something that is not likely to be dynamic within the course of a given report session (since calculated columns only recalculate upon load or refresh). However, in this case, grade nicely meets these criteria, and the calculated grade column also simplifies the histogram creation (although that can also be done via measures, though the DAX is a bit more complicated).
If you haven’t already, I would strongly recommend going back through this course. @sam.mckay has recently completely redone it, and it does a fantastic job explaining all of the concepts you are wrestling with.
Good luck finishing your model, and just give a shout if you have any other problems.
Per @sam.mckay’s policies for the forum, all forum business must be conducted publicly. This is because, in addition to answering individual questions, the goal of the forum is to serve as a knowledge base for all members.
Is there a way you can mask any of the sensitive data and/or just post a representative subset of the data?
I have prepared three related tables. I want to get overall Std Deviation of Final Result Table as I always get Std. Deviation regarding any of Assessment Tool. Final Result.xlsx (36.2 KB)
Hope @BrianJ doesnt mind, but could you provide a final output of what you are looking for? I’m thinking you want to use STEVX instead of the plain stddev. But just a guess here
In a scenario where you have a thousand scores, with a min score of zero and a max score of 10, the largest possible standard deviation is 5. (500 zeroes and 500 10s).
I wasn’t sure exactly what result you are looking for, so I calculated the overall standard deviations, standard deviations by student, and by assessment tool. Same measures – just applying different context.
I hope this is helpful. If this still doesn’t answer your question, as Nick indicated, you’ll need to provide a mockup of the results you’re looking for.
@BrianJ
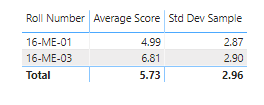
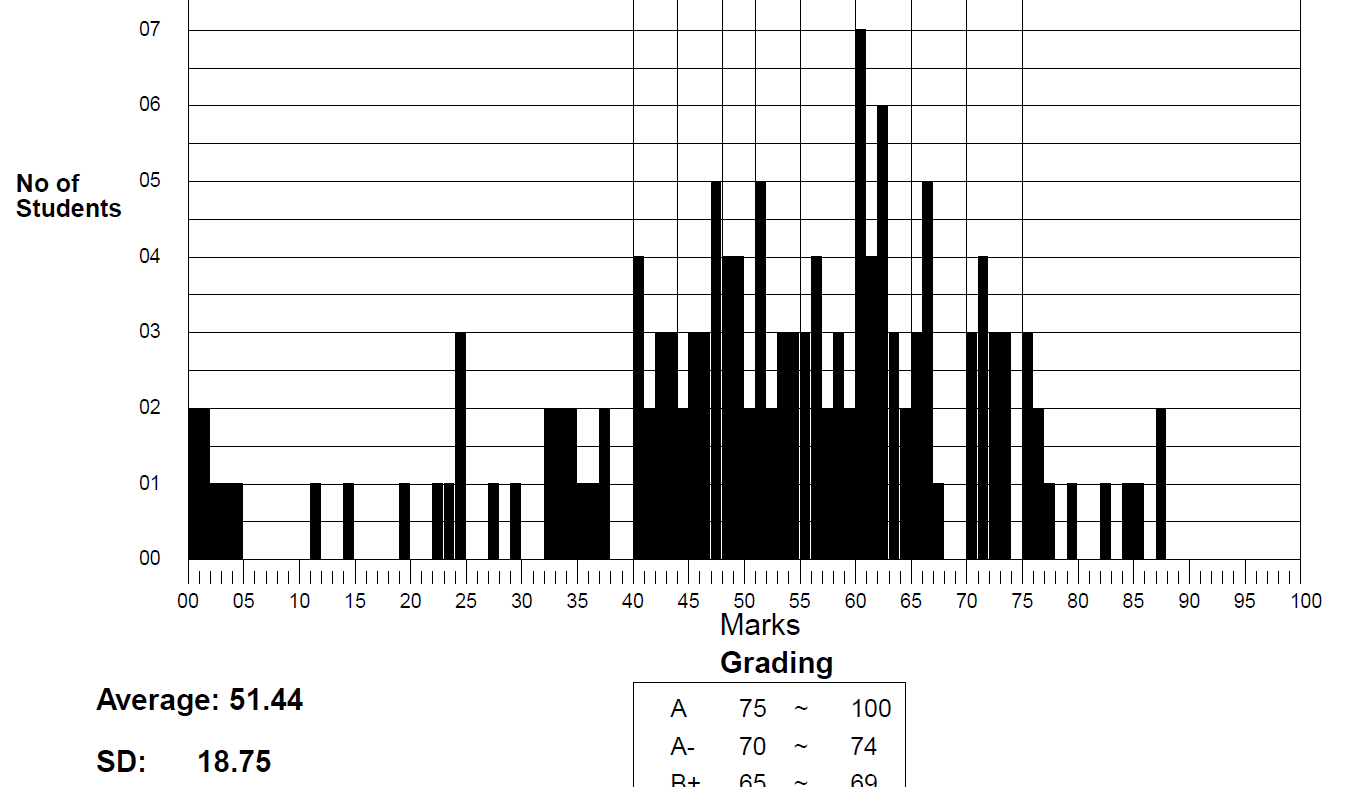
I tried to reproduce the same result in another app. Please have a look at the standard deviation, It’s overall measure for whole class for their total marks.
OK, that’s extremely helpful! I had misinterpreted your requirement, looking at the standard deviation of the mean scores, rather than the standard deviation of the total scores by student. Here are our results now:
Created a virtual table variable (vTable), using ADDCOLUMNS, SUMMARIZE and our [Total Marks] measure to calculate the total marks by student roll number in a virtual column called TotMarks.
Applied an iterating function (AVERAGEX, STDEVX.P and STDEVX.S to the TotMarks column in vTtable.
All the measures are basically the same, except for the iterating function they use. Here’s the STDEVX.S measure:
Std Dev Sample of Totals by Student =
VAR vTable =
ADDCOLUMNS(
SUMMARIZE(
'Student Section',
'Student Section'[Roll Number]
),
"TotMarks", [Total Marks]
)
VAR StDevTot =
STDEVX.S(
vTable,
[TotMarks]
)
RETURN
StDevTot
I hope this is helpful. Full solution file attached.
Thank you very much. It’s so intuitive and amazing. you have wonderful and amazing skill. Should I also develop Grade Tables by using this virtual table technique instead of Calculated Column so I could be able to produce the axis for Histogram?
No, virtual tables are phenomenally powerful for use within measures, but are of very little utility when it comes to visuals, since there’s no easy way to output them - most visuals demand either a physical column or a scalar measure.
If you don’t mind using custom visuals, Microsoft has a pretty nice histogram visual that makes this task relatively straightforward.
Step 1: create a calculated column in your Final Results table of total score by student:
Total Marks by Student =
CALCULATE(
[Total Marks],
ALLEXCEPT(
'Final Result',
'Final Result'[Roll Number]
)
)
Step 2: Create a physical summary table of student roll number and the total score calculated column from Step 1 above:
Summary Student Totals =
SUMMARIZE(
'Final Result',
'Final Result'[Roll Number],
'Final Result'[Total Marks by Student]
)
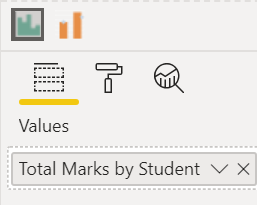
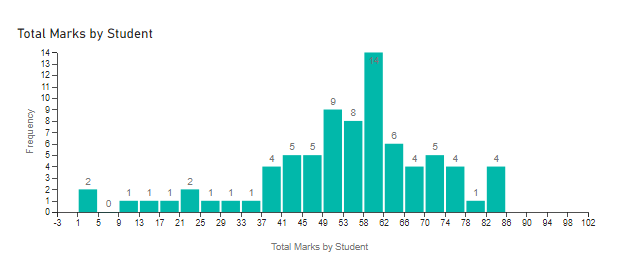
Step 3: Just drop the columns created in Step 2 into the appropriate wells in the custom visual:
And there’s the histogram. You can then play with the number of bins, axis formatting, etc.
To the contributors of this post, thank you for all your inputs on this topic we are now tagging it as Solved. To help us learn more about your experience in the forum, please take a moment to answer this short forum survey. We appreciate all your help and suggestions. Thanks!