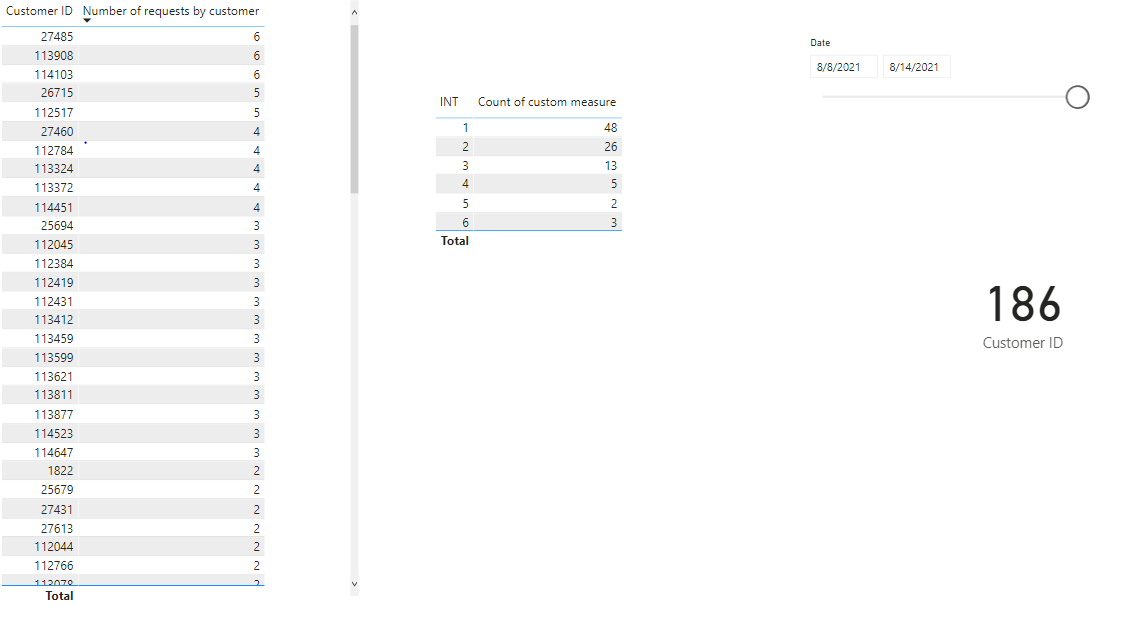
Hello all,
I am working on benefits investigation data where I wanted to calculate number of investigations per account which is driven by date slicer
I wrote the following DAX to calculate number of requests by customers:-
Number of requests by customer =
COUNTROWS (
FILTER (
ALLSELECTED (‘Data’ ),
‘Data’[Customer ID] = SELECTEDVALUE ( Data[Customer ID] )
)
)
Then I went further to count how many customer had put how many requests, for example 10 requests were put in by 4 customers so on and so forth. I obtained this results by creating reference table and pushed the above dax result to match that table as below:-
Count of custom measure =
VAR _int =
SELECTEDVALUE (‘Table1’[INT])
VAR tab =
SUMMARIZE (
DISTINCT ( ‘Data’[Customer ID] ),
‘Data’[Customer ID] ,
“Count”, COUNTROWS (
FILTER (
ALLSELECTED ( ‘Table1’ ),
‘Data’[Customer ID] = EARLIER ( ‘Data’[Customer ID] )
)
)
)
VAR newtab =
ADDCOLUMNS (
tab,
“Result”,
COUNTROWS (
FILTER (
ALLSELECTED (‘Data’),
‘Data’[Customer ID] = EARLIER (‘Data’[Customer ID] )
)
)
)
RETURN
COUNTROWS ( FILTER ( newtab, [Result] = _int ) )
I got the following output:-
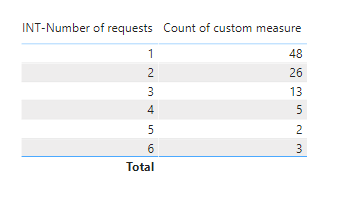
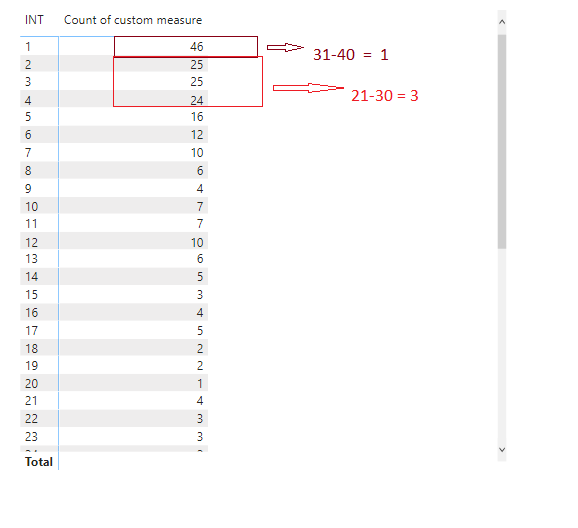
Now I want to group the output of “Count of custom measure” in ranges
ranges will be 1-20, 21-30,31-40.50+ as following
I tried achieving this by adding Groups column to my reference table but it did not work. Please guide me through this problem. I am attaching my pbix file.
Thank You
test.pbix (279.3 KB)
Hi @PranjaliK,
Welcome to the forum!
Currently you are working with a flat file, I’ve added a Customers dimension table (currently this has a M:M relationship due to the fact that it contains blanks). Since you also have a Date column I recommend you add a Date dimension as well, you can find an extensive date table here.
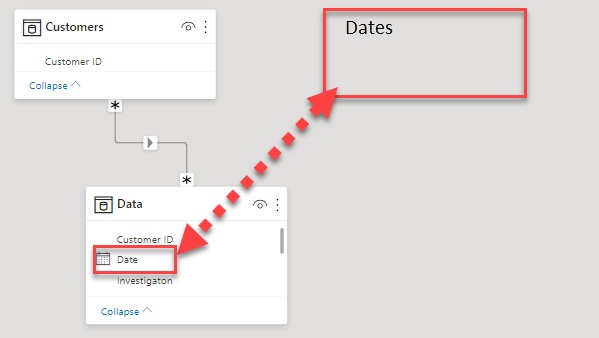
.
Next I created some measures:
Number of requests by customer v2 =
COUNTROWS (
FILTER (
ALLSELECTED ('Data' ),
'Data'[Customer ID] IN VALUES( Customers[Customer ID] )
)
)
.
Count of custom measure v2 =
VAR vTable =
ADDCOLUMNS(
VALUES( Customers[Customer ID] ),
"No Requests", [Number of requests by customer v2]
)
RETURN
COUNTROWS(
FILTER( vTable,
COUNTROWS(
FILTER(
Table1,
[No Requests] = [INT]
)
) >0
)
)
.
Next I added a supporting table to your model.
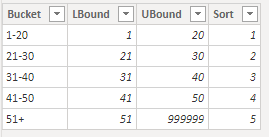
and this final measure
Grouping measure v2 =
VAR vTable =
ADDCOLUMNS(
VALUES( Table1[INT] ),
"QTY", [Count of custom measure v2]
)
RETURN
COUNTROWS(
FILTER( vTable,
COUNTROWS(
FILTER(
Segments,
[QTY] >= Segments[LBound] &&
[QTY] <= Segments[UBound]
)
) >0
)
)
.
With this result
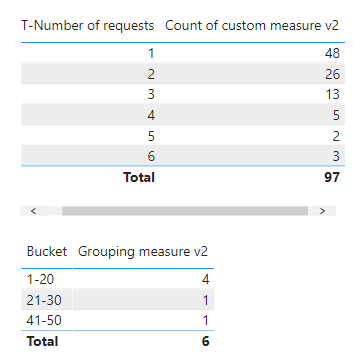
Here’s your sample file.
test (6).pbix (296.7 KB)
I hope this is helpful
1 Like
Hi @Melissa,
I remember tutorial of EDNA where Sam refers to use separate Date table. I will keep that in mind.
After looking at your DAX, I felt I went the long way. This is something new that I learnt today.
Thank You!
Glad I could help 
All the best.
Hi @Melissa ,
I did not understand why did you use >0 in DAX queries above.?
Thank You.
Hi @PranjaliK,
You want to count the number of values that fall in each bucket. So, with the vTable you’re going to iterate through every T-Number of requests and work out the Count of custom. This goes through the [INT] values virtually and returns 1 row for whatever evaluates to true (>0).
More related content can be found here:
I hope this is helpful
1 Like
Thank You for this info @Melissa .