I’m working on a report to visualize data about some videos my team owns. I’m using a SQL query in the query editor to connect to a Redshift database that contains information for thousands of videos. Each video in the database is assigned a unique video ID and each play of a video generates a row in the database.
The problem: The Redshift database stores data about thousands of videos and contains millions of rows. My team is interested in a relatively small subset of videos (about 600 videos right now and we add more every month). Adding each of our video IDs to the SQL query in the query editor and manually updating each month doesn’t scale.
What I want to do: Add a parameter to the SQL query that will import only the rows where the video ID value in the Redshift database = any of the values in the video ID column of my team’s catalog.
What I’ve tried: I created a Catalog query with a column that contains the video IDs for all the videos my team owns. The source of the Catalog query is an Excel file stored on a SharePoint. And I’ve added a parameter to the SQL query to filter on a single value from that Catalog query.
I can set the value in the parameter to 12345 and the SQL query will get the data only for video ID 12345. That works fine. But I can’t figure out how to modify the M code to get the data for the entire catalog.
The question: Is it possible to create a parameter for the SQL query that will pass all the video IDs from the Catalog query?
#(lf)AND action=‘PLAYED_VIDEO’#(lf)AND value=‘“&[any value in the VideoID column of the Catalog query]&”’;")
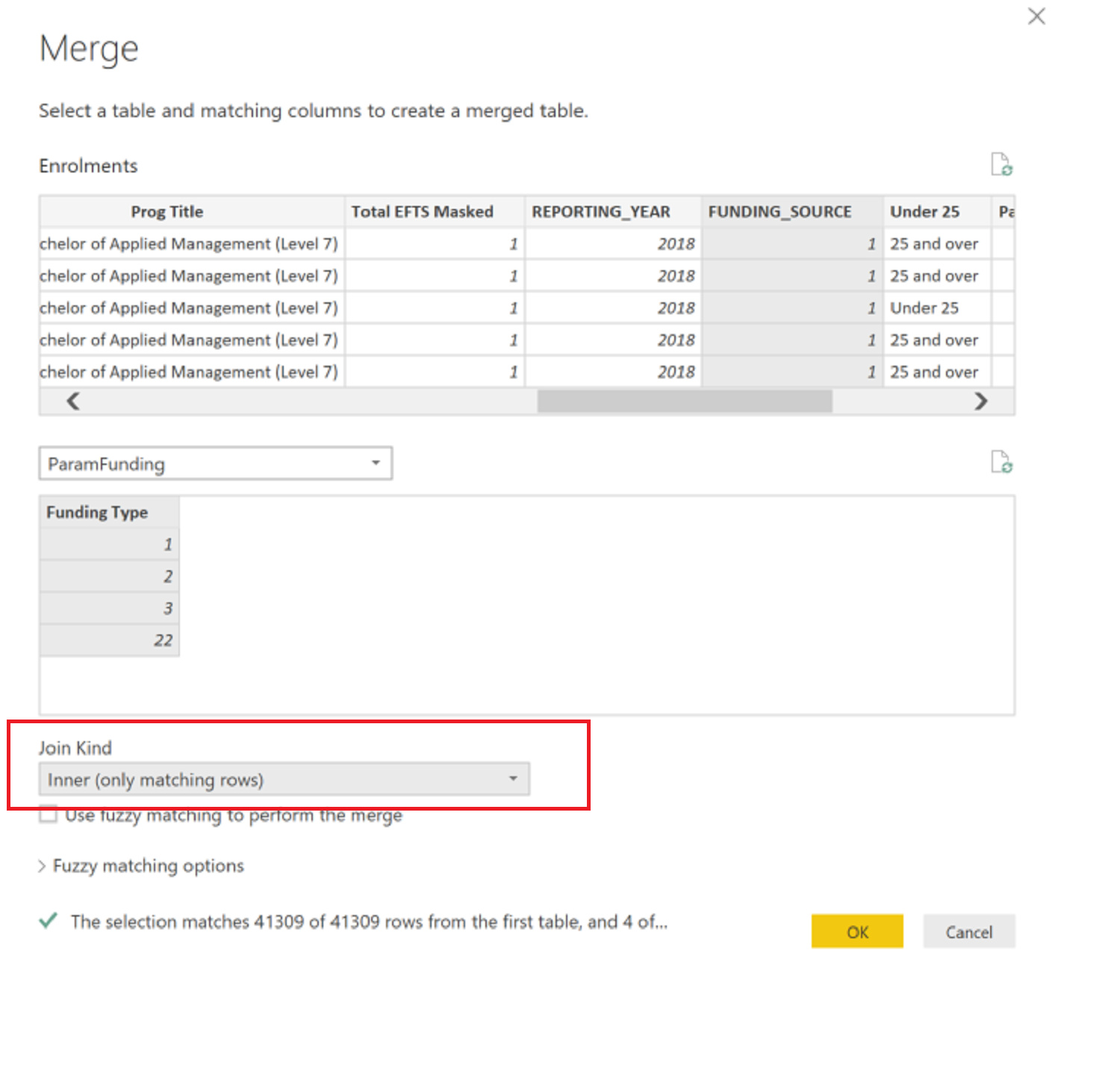
pull in data from your sharepoint excel file as a table in Power BI which will have video id’s that you need to use to filter your master table.
Now Import your master data table with all data and then apply a Merge Query inside Query Editor with Inner Join as the Join Kind (refer attached screenshot below ) and this should filter down your master table down to the video id’s based on your catalogue excel file.
This way every time you update your excel file in Sharepoint, you can just refresh your powerbi Model and it should update your master table automatically
Thank you for taking the time to look at my problem. If I understand your solution correctly, I would still be pulling in millions of extra rows only to remove them with the inner join. My goal with adding the parameter is to avoid pulling in those unnecessary rows.