SUMMARIZECOLUMNS cannot be used in a measure if that measure has filter context, which pretty much everything does. For example (using the Contoso Database) we want to summarize sales by calendar year and country. Using SUMMARIZECOLUMNS we can write:
Sample Summarize =
SUMX(
SUMMARIZECOLUMNS(
'Date'[Calendar Year]
,Customer[Country]
,"Sales"
, SUMX( Sales, Sales[Quantity] * Sales[Unit Price])
)
,[Sales]
)
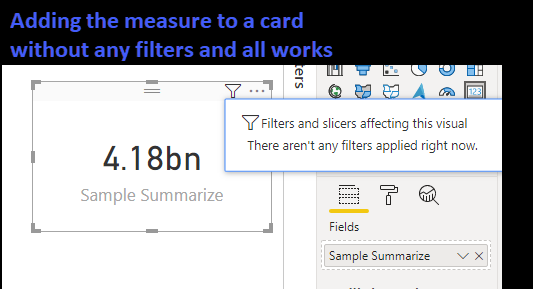
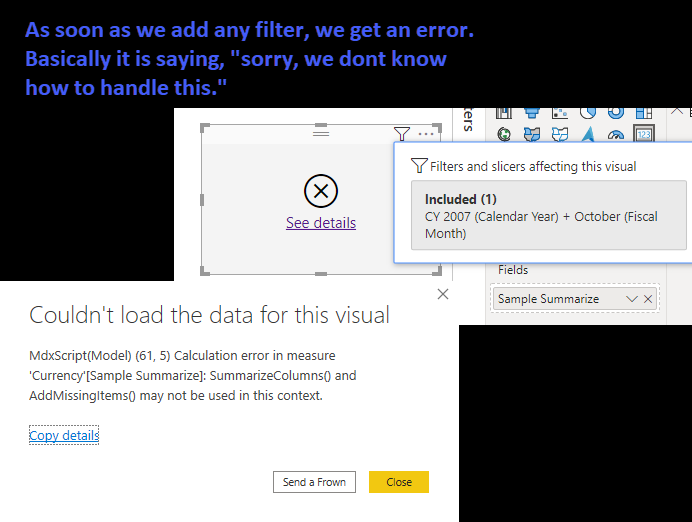
But as soon as we apply a filter:
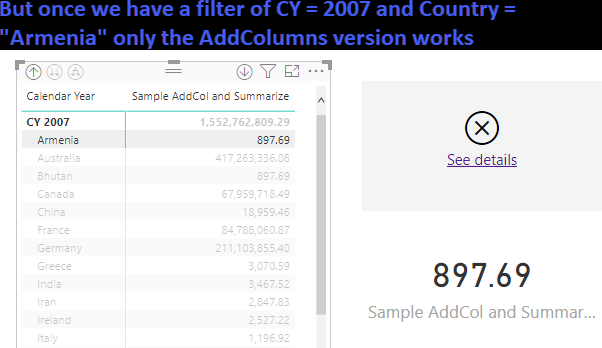
But when we use AddColumns and summarize:
Sample AddCol and Summarize =
SUMX(
ADDCOLUMNS(
SUMMARIZE(
Sales
,'Date'[Calendar Year]
,Customer[Country]
)
,"Sales"
, CALCULATE( SUMX( Sales, Sales[Quantity] * Sales[Unit Price]))
)
,[Sales]
)
There are a few reasons why you want to use the AddColumns/Summarize pattern rather than just adding a column in Summarize itself. Usually they will produce the same result, but there can be times where SUMMARIZE just has output that makes no sense. But the main issue is that SUMMARIZE will result in poorer performance and that has to do with the fact it will scan your tables to summarize and then basically scan them again to add each calculated column. So if you have 3 calculated columns that is three scans plus the original one to group them. AddCol/Summarize has a much more effiecient query plan and performance is much better.
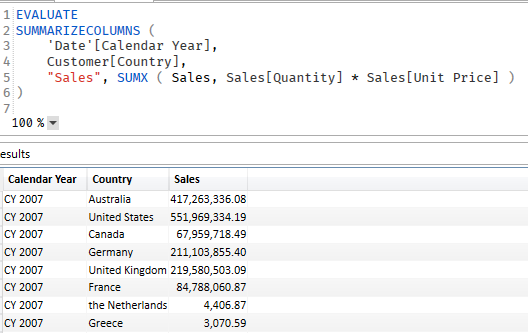
If you ever exported the performance data from PBI into DAX Studio you will see that PBI uses SUMMARIZECOLUMNS a lot in the queries it is producing. It is more efficient than AddCol/Sum. but really is only good for querying and not so much for measures. Works as you would expect when querying:
Hope that helps clear it up.