Hi all,
Ive been trying to understand the difference between SUMMARIZE and ADDCOLUMNS (while watching the e-dna courses) when using inside a measure (not a calculated column). I also read this artice over at SQLBI where they rather use SUMMARIZECOLUMNS instead which made me more confused.
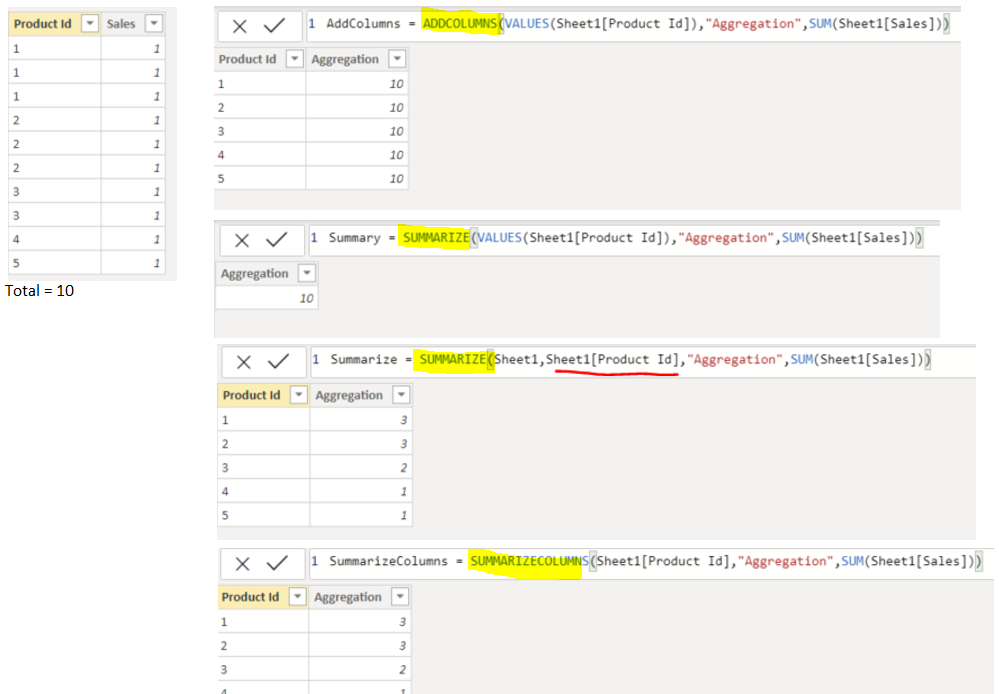
So here are two identical dax-codes besides the fact that the first is using Addcolumns( and the other one is using Summarize(
In a nutshell summarize +Addcolumn combo is identical in terms of functionality as Summarize. The only thing that differentiate them is the calculation time. In other words, you can create a calculated column within a Summarize function too (I usually use Summarize to create virtual tables) but when you execute it on the report canvas it will take long time. Now if you create same calculated column using addcolumn and summarize duo the time to complete the operation will be very less.
Also, summarizecolumn in nothing but syntax sugaring of Addcolumn and summarize duo. Whenever you write a funtion using summarizecolumn behind the hood it will always behave like summarize+Addcolumn duo.
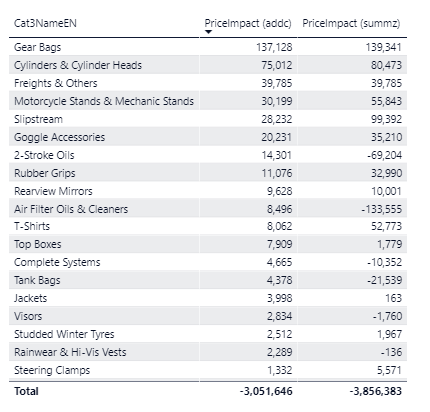
and when I try to use the code/functions within a SUMX() they give me different results when I slice on DimProduct Category3 and that is what confuses me
Hi @Tibbie,
As you already mentioned, there are some best practices when using these functions:
Summarize is used for grouping fields from dimension, but not for aggregating data. Summarize has additional parametar for providing columns for grouping.
AddColumns is used to add aggregations to data created by Summarize function
SummarizeColumns is newer function that does formula from above. It is optimized for both grouping and creating aggregations, plus it has parameters for filtering
In my experience, if you are not sure what data is being generated in the back-end, i prefer testing it as creating new table. Attached examples of how these functions work and what are results:
Hi @nemanja.andic,
Oh okey, i forgot the table name then! Thanks for clearing that out!
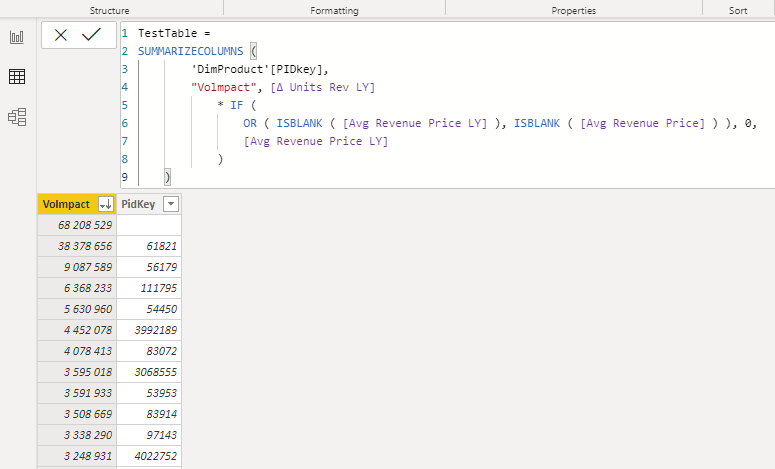
So the result i was looking for was this without VALUES as your third and forth example. SUMMARIZE (DimProduct, 'DimProduct'[PIDkey]
instead of SUMMARIZE ( VALUES('DimProduct'[PIDkey])
but how do your wrap your forth example (since Summarizecolumn is supposed to be the most effective function performance wise) in a SUMX() ?
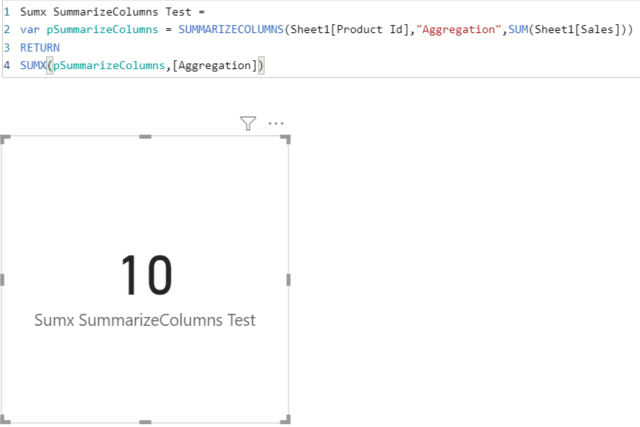
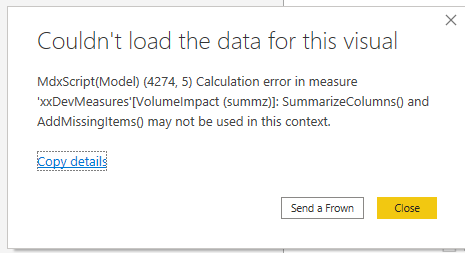
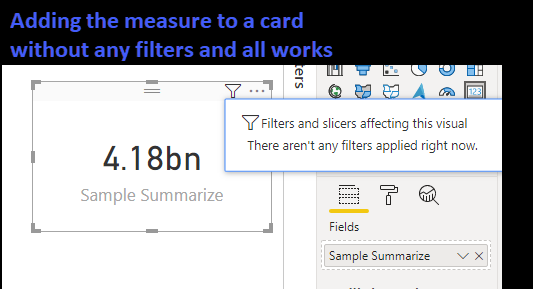
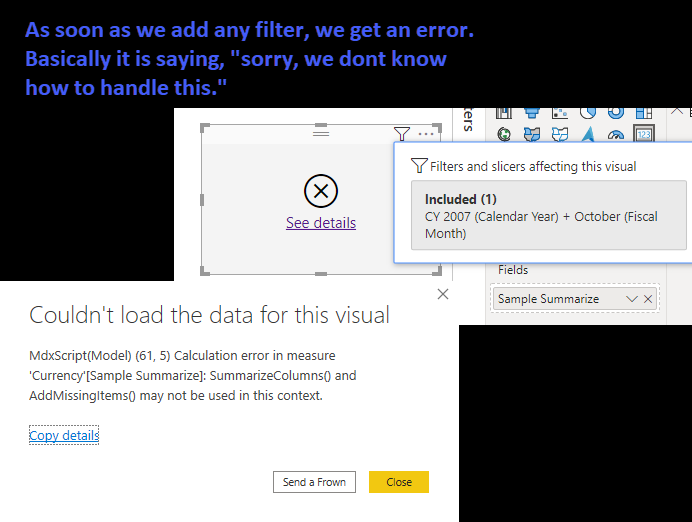
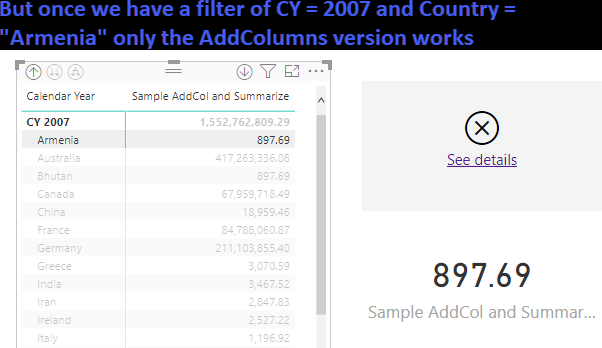
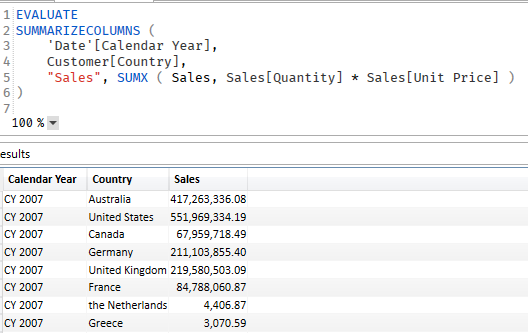
SUMMARIZECOLUMNS cannot be used in a measure if that measure has filter context, which pretty much everything does. For example (using the Contoso Database) we want to summarize sales by calendar year and country. Using SUMMARIZECOLUMNS we can write:
There are a few reasons why you want to use the AddColumns/Summarize pattern rather than just adding a column in Summarize itself. Usually they will produce the same result, but there can be times where SUMMARIZE just has output that makes no sense. But the main issue is that SUMMARIZE will result in poorer performance and that has to do with the fact it will scan your tables to summarize and then basically scan them again to add each calculated column. So if you have 3 calculated columns that is three scans plus the original one to group them. AddCol/Summarize has a much more effiecient query plan and performance is much better.
If you ever exported the performance data from PBI into DAX Studio you will see that PBI uses SUMMARIZECOLUMNS a lot in the queries it is producing. It is more efficient than AddCol/Sum. but really is only good for querying and not so much for measures. Works as you would expect when querying:
Thanks for this explanation, which I’m still trying to digest (being a beginner). This kind of complexity is a huge impediment to learning DAX and using PowerBI for the beginner. I’m working through the Mastering DAX E-DNA course and this issue is not mentioned in the section on Summarize. Is there a good source on best practices for summarizing columns in a measure where there will be filter contexts, as well as any other gotchas?
Thank you @Dhrubojit_Goswami.
That piece indicates that Summarize should not be used - at all. I read it earlier but the whole discussion of the clustering is beyond my PowerBI understanding. Is there any chance do you suppose that PowerBI might make use of SQL at some point? A lot of other data analysis tools do.
Thank you @AntrikshSharma. This would make a good E-DNA tutorial for those transitioning from SQL to DAX. I couldn’t find part 2 - could you link to it please?
@mpchean No idea, maybe because Power BI is targeted towards Excel and Business Analysts who don’t have to learn SQL, but funny thing is they ended up creating 2 complex languages instead lol.