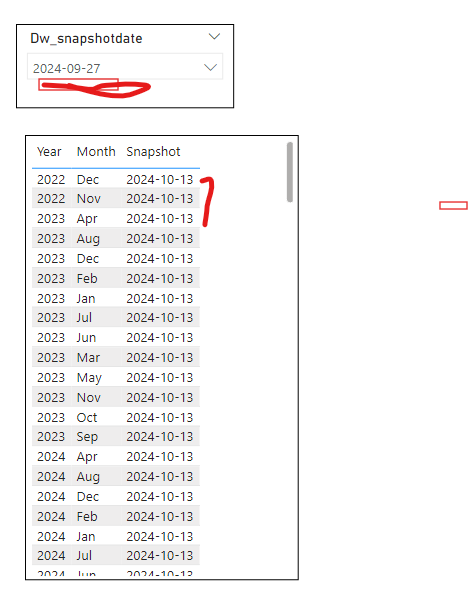
Hi, I am trying to compare different snapshots in a table by allowing users to select the dates on two different filters. but I got stucked on the first step. when I use SELECTEDVALUE as a variable and passes the variable to the calculated table as a filter , the selected value does not affect the calculated table. This is the code
First_Table =
VAR CurrentSnap =
SELECTEDVALUE(Snapshoptdate[Dw_snapshotdate])
VAR TableA =
CALCULATETABLE(
SELECTCOLUMNS(
'R_Yearly_Summary_Measures',
"UCode", 'R_Yearly_Summary_Measures'[Ucode]
),
'R_Yearly_Summary_Measures'[Dw_snapshotdate] = CurrentSnap
)
RETURN
but if i pass the alternative like max(snapshotdate) it takes the value and the tables renders, the issues with this is if another value is selected on the filter it does not affect the table as in the image. please is there a limitation to this approach, or what function am i using wrongly. thanks
Calculated tables are only recalculated if any of the tables they pull data from are refreshed or updated. If the table uses data from DirectQuery, calculated tables aren’t refreshed. In the case with DirectQuery, the table will only reflect the changes after the semantic model is refreshed.
In short dynamic input like from a slicer on a report page does not trigger a refresh and will therefore not alter its already evaluated state.
As @Melissa mentioned, calculated tables are evaluated at model refresh time, meaning slicer selections on the page won’t dynamically affect the contents of a calculated table. As a result, dynamic filtering based on slicers won’t propagate into a calculated table.
The workaround using MAX() worked because it returned the maximum date from the current filter context. However, this approach only provides a single value, meaning it can’t handle comparisons across multiple, independently selected dates or date ranges.
One way you can resolve this is by using two slicers (from the same date table) and controlled interactions between the slicers and separate measures.
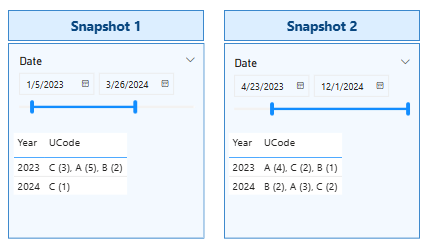
I used some fake data and added two range slicers, both using the same date table. I edited the interactions so Slicer 1, on the left, affects only the Snapshot 1 measure shown below it, and Slicer 2, on the right, affects only the Snapshot 2 measure shown below it. Then I added a matrix with Year on the rows of each and slightly different measures in each one.
The difference between the measures is that each uses the slicer context to filter for the relevant date range independently. Snapshot 1 counts and aggregates UCodes based on the first slicer, while Snapshot 2 does the same using the second slicer. This setup allows for side-by-side comparisons of the aggregated UCode values for two different ranges.
Without knowing what you’re trying to show, I’m just aggregating the fake UCodes with a count of occurrences of each value as “<Ucode> (<count of Ucode>)”.
If you share some sample data and your expected results, you might get better solutions