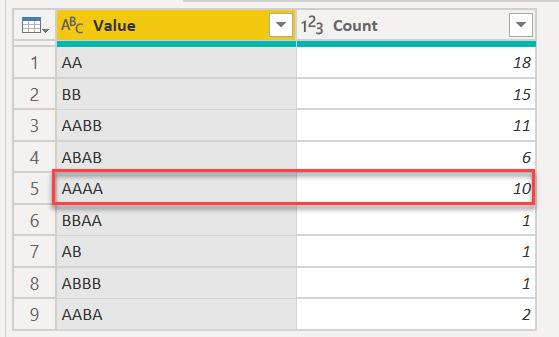
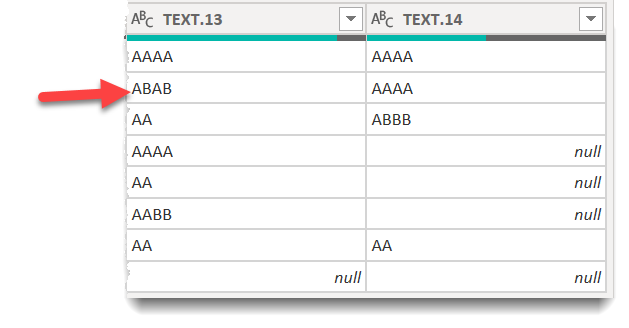
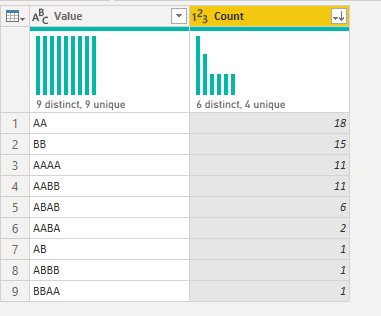
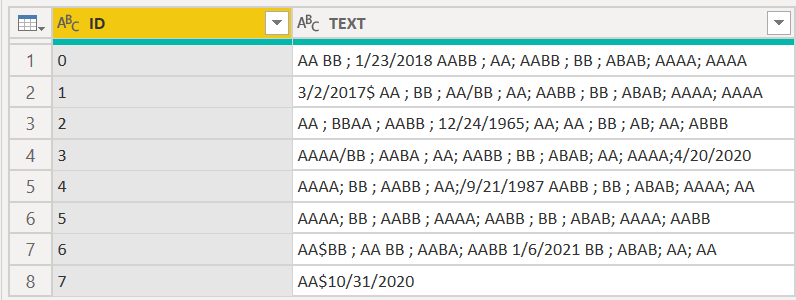
@BrianJ Here is a solution for “with dates”:
let
Source = Table.FromRows(Json.Document(Binary.Decompress(Binary.FromText("lZFdCoQwDISvUoqPQkzrLz4l15De/xo7TVp9WFZYqGjGzsdMe11ximMUCUE1nIEpZUoT70HEBJGzf/qsolVxXcTMqrGMV2QMcFf/NuDv7RH6m5U8Vd1pr+Zj0GfiY1067oE1RUFw0AgBjwOziU8UlZdELdWMKljJj0gN1nBzw90Ve0M6KDES7ttLV5iNsvygvJ+UF4RUCxpnNc7Q3DesU3Cta+3B3y17ks0JPFHmXjmW8gE=", BinaryEncoding.Base64), Compression.Deflate)), let _t = ((type nullable text) meta [Serialized.Text = true]) in type table [ID = _t, TEXT = _t, RESULT = _t]),
#"Removed Columns" = Table.RemoveColumns(Source,{"RESULT"}),
#"Replaced Value" = Table.ReplaceValue(#"Removed Columns"," ; ","^",Replacer.ReplaceText,{"TEXT"}),
#"Replaced Value1" = Table.ReplaceValue(#"Replaced Value","; ","^",Replacer.ReplaceText,{"TEXT"}),
#"Replaced Value2" = Table.ReplaceValue(#"Replaced Value1"," ","^",Replacer.ReplaceText,{"TEXT"}),
#"Replaced Value3" = Table.ReplaceValue(#"Replaced Value2","$","^",Replacer.ReplaceText,{"TEXT"}),
#"Replaced Value4" = Table.ReplaceValue(#"Replaced Value3",";","^",Replacer.ReplaceText,{"TEXT"}),
#"Split Column by Delimiter" = Table.SplitColumn(#"Replaced Value4", "TEXT", Splitter.SplitTextByDelimiter("^", QuoteStyle.Csv), {"TEXT.1", "TEXT.2", "TEXT.3", "TEXT.4", "TEXT.5", "TEXT.6", "TEXT.7", "TEXT.8", "TEXT.9", "TEXT.10", "TEXT.11", "TEXT.12"}),
#"Changed Type" = Table.TransformColumnTypes(#"Split Column by Delimiter",{{"ID", Int64.Type}, {"TEXT.1", type text}, {"TEXT.2", type text}, {"TEXT.3", type text}, {"TEXT.4", type text}, {"TEXT.5", type text}, {"TEXT.6", type text}, {"TEXT.7", type text}, {"TEXT.8", type text}, {"TEXT.9", type text}, {"TEXT.10", type text}, {"TEXT.11", type text}, {"TEXT.12", type text}}),
#"Added Custom" = Table.AddColumn(#"Changed Type", "Custom", each if ( List.Count ( Text.Split([TEXT.1], "/") ) - 1 ) = 1 then Text.Split([TEXT.1], "/"){0} else [TEXT.1]),
#"Added Custom1" = Table.AddColumn(#"Added Custom", "Custom.1", each if ( List.Count ( Text.Split([TEXT.1], "/") ) - 1 ) = 1 then Text.Split([TEXT.1], "/"){1} else null),
#"Added Custom2" = Table.AddColumn(#"Added Custom1", "Custom.2", each if [TEXT.5] = null then null else
if ( List.Count ( Text.Split([TEXT.5], "/") ) - 1 ) = 1 then Text.Split([TEXT.5], "/"){0} else [TEXT.5]),
#"Added Custom3" = Table.AddColumn(#"Added Custom2", "Custom.3", each if [TEXT.5] = null then null else
if ( List.Count ( Text.Split([TEXT.5], "/") ) - 1 ) = 1 then Text.Split([TEXT.5], "/"){1} else null),
#"Removed Columns1" = Table.RemoveColumns(#"Added Custom3",{"TEXT.1", "TEXT.5"}),
#"Unpivoted Other Columns" = Table.UnpivotOtherColumns(#"Removed Columns1", {"ID"}, "Attribute", "Value"),
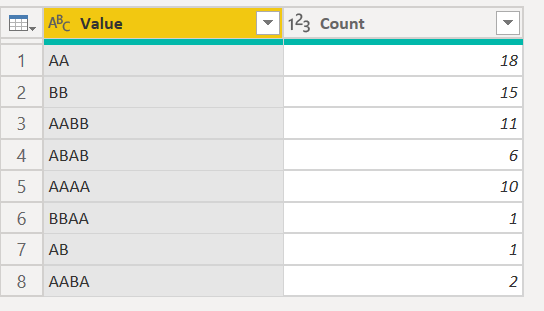
#"Filtered Rows" = Table.SelectRows(#"Unpivoted Other Columns", each ([Value] <> "")),
#"Removed Other Columns" = Table.SelectColumns(#"Filtered Rows",{"Value"}),
#"Grouped Rows" = Table.Group(#"Removed Other Columns", {"Value"}, {{"Count", each Table.RowCount(_), Int64.Type}}),
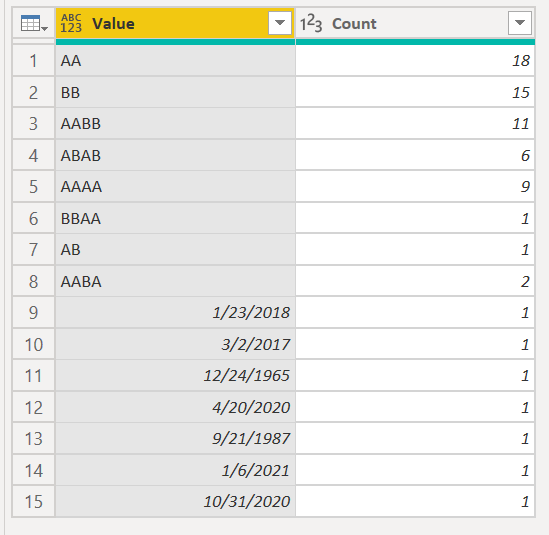
#"Sorted Rows" = Table.Sort(#"Grouped Rows",{{"Count", Order.Descending}}),
#"Added Custom4" = Table.AddColumn(#"Sorted Rows", "Custom", each if Text.StartsWith([Value], "/") then Text.Middle([Value], 1, Text.Length([Value])) else [Value]),
#"Removed Columns2" = Table.RemoveColumns(#"Added Custom4",{"Value"}),
#"Reordered Columns" = Table.ReorderColumns(#"Removed Columns2",{"Custom", "Count"})
in
#"Reordered Columns"
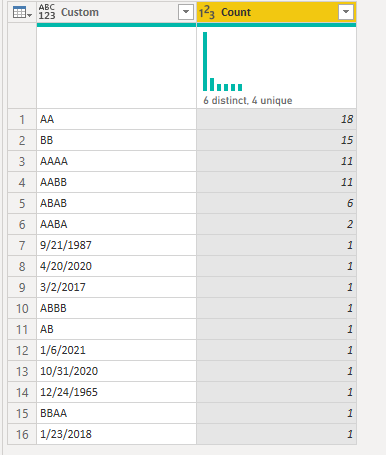
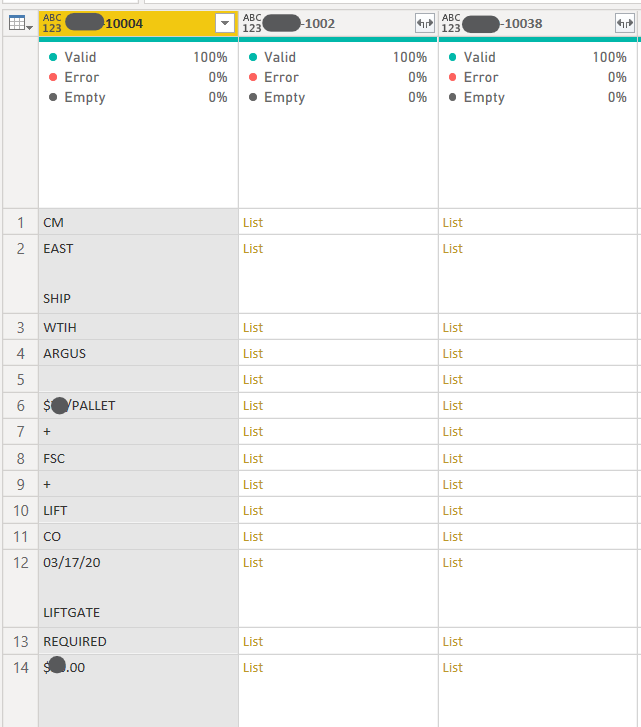
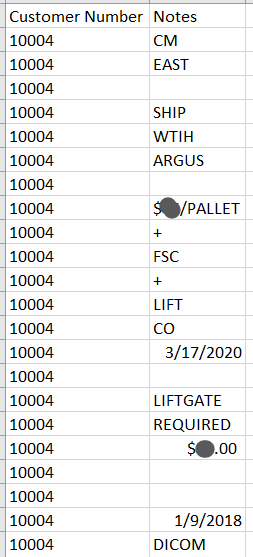
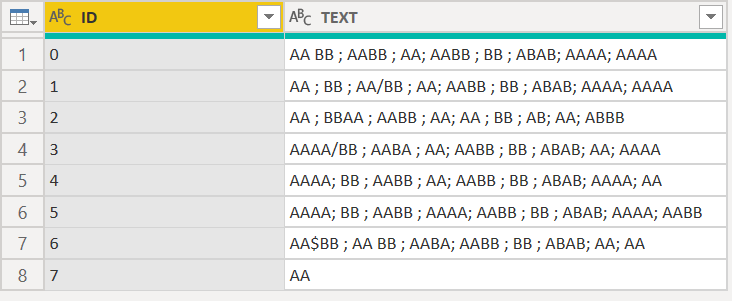

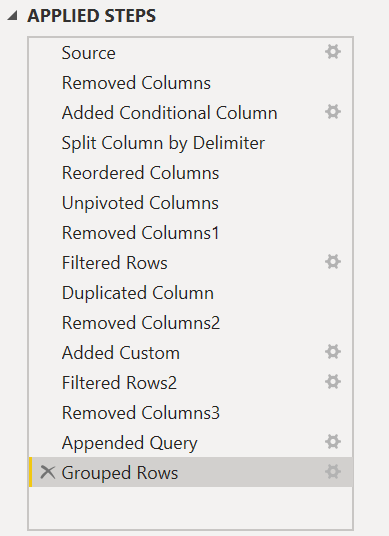

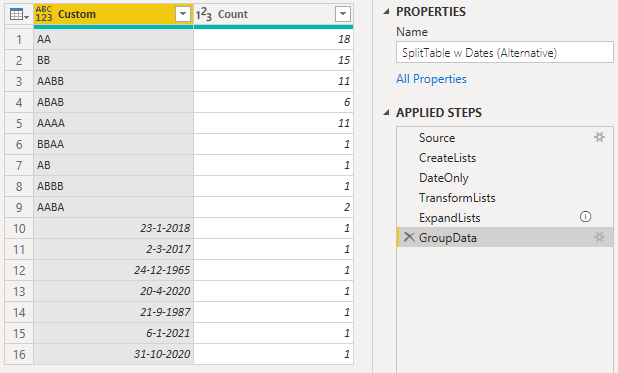


 DAX:
DAX: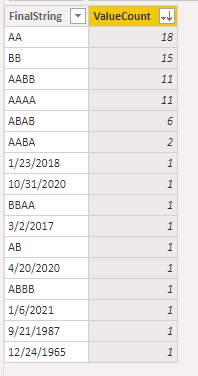

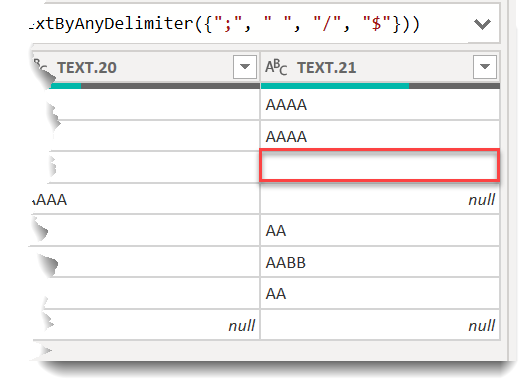
 . I still have to rename the variables and think hard if I can come up with something better.
. I still have to rename the variables and think hard if I can come up with something better.