Good day,
I have a problem, that would be appreciated if you could help me to sort out.
I done a mock up example that I attach here the Xls and PBI file for reference
I would like to pick the Top N on a selection made on a Crossjoint, and few other minor issues.
Here below the detail.
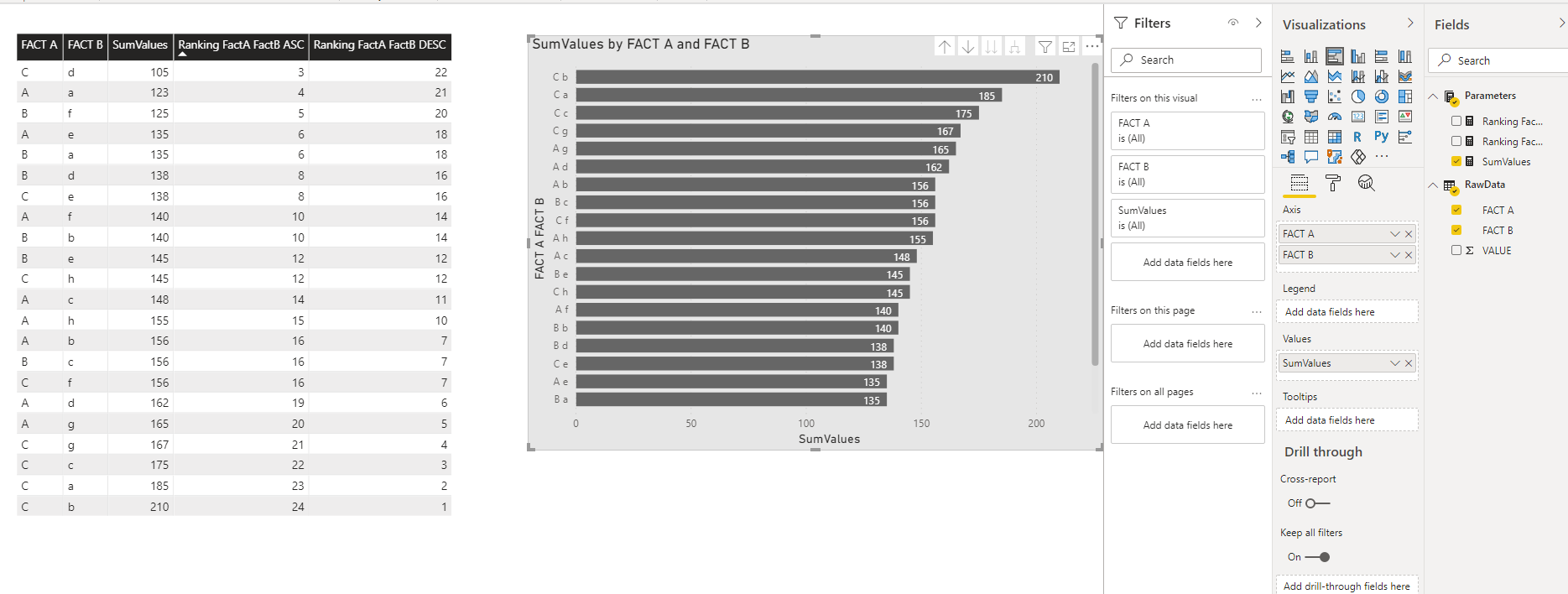
The table, see the figure below has 3 columns (Fact A, Fact B, Value).
Ranking Issue
In Power BI I prepare two visualization a table with Fact A, Fact B, the Sum of values and the relative descending and ascending ranking, using the parameters:
Ranking FactA FactB ASC =
RANKX(
CROSSJOIN( ALL( RawData[FACT A] ), ALL( RawData[FACT B]) ) ,
[SumValues], , ASC
)
Ranking FactA FactB DESC =
RANKX(
CROSSJOIN( ALL( RawData[FACT A] ), ALL( RawData[FACT B]) ) ,
[SumValues], , DESC
)
Where
SumValues = SUM (RawData[VALUE] )
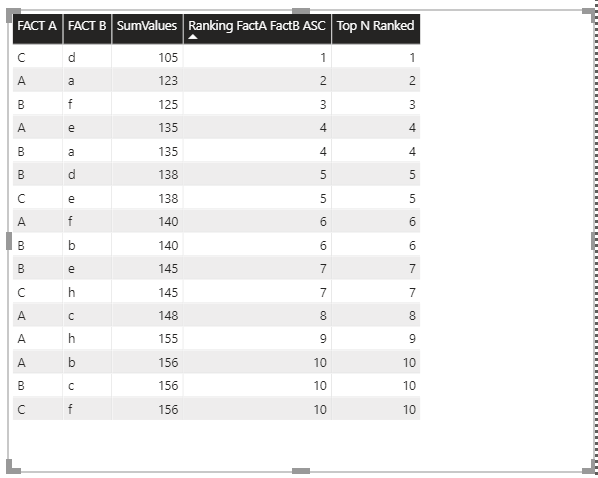
So far so good, as per snapshot I got the ranking, correct for the Descending option while the ascending for the lowest value (highest for descending) rank as 3 instead of 1. See Snapshot
TopN on Crossjoin
Now let arrive to the point I am stuck with.
As per the previous table and the histogram below I graphed the combination of Fact A and Fact B in ascending or descending order, but I would like to show only the Top 5.
I know I should use the DAX function TOPN, but how when should work on a Crossjoin sub data set?
Looking forward for your support.
Regards,
Luca
RAW DATA TABLE: TopOnCrossjoin-RawData.xlsx (10.0 KB)
PARAMETERS:
Ranking FactA FactB ASC =
RANKX(
CROSSJOIN( ALL( RawData[FACT A] ), ALL( RawData[FACT B]) ) ,
[SumValues], , ASC
)
Ranking FactA FactB DESC=
RANKX(
CROSSJOIN( ALL( RawData[FACT A] ), ALL( RawData[FACT B]) ) ,
[SumValues], , DESC
)
Where
SumValues = SUM (RawData[VALUE] )
TABLE & HISTOGRAM VISUALIZATION: