@rodwhiteley,
Okay, I think I finally got this one. Number of challenging elements here:
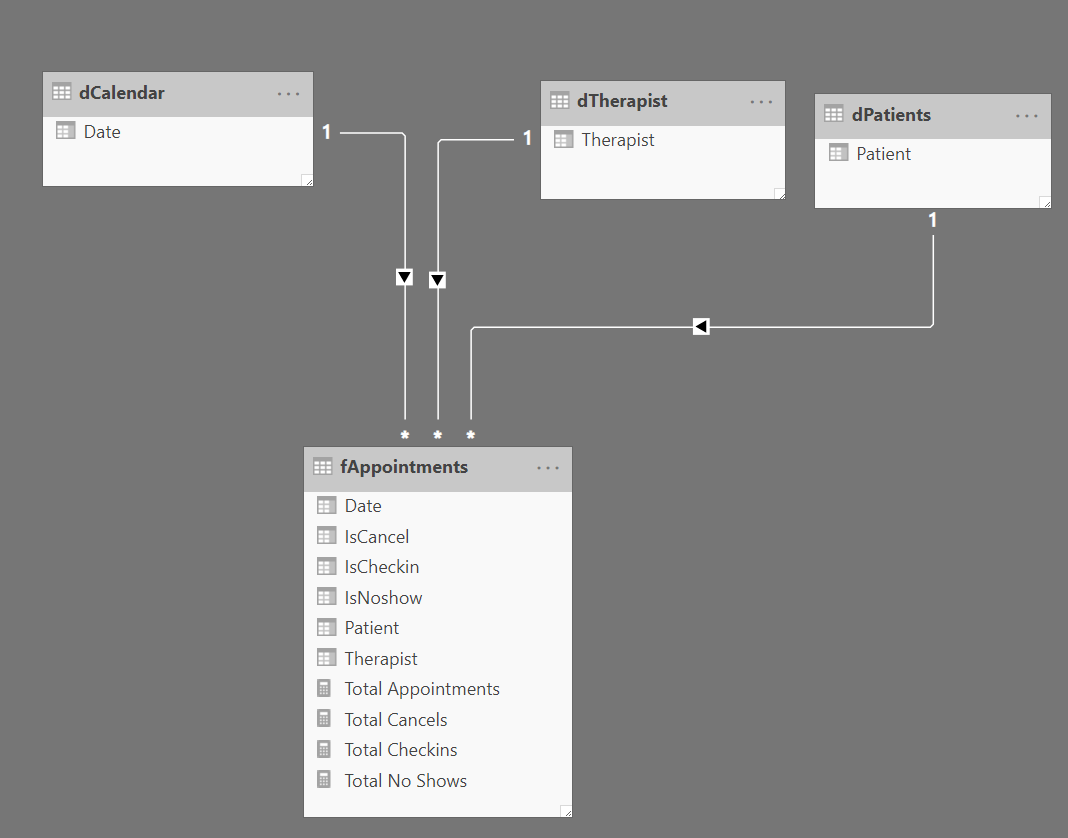
- overriding the patient evaluation context in the matrix (i.e., getting RANKX to rank based on therapist rather than patient, but using patient to filter the fAppointment table down to the proper records to summarize)
- dealing with the large number of ties
- checking the evaluation context for HASONEVALUE (otherwise the measure will always return the therapist with the highest total number of patient visits overall)
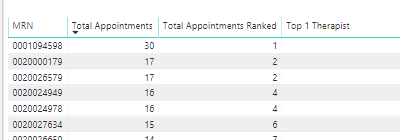
Two basic measures here (though the second one is repeated five times changing the rank criteria from 1 to 5 to form the matrix values/columns). The first is just a standard RANKX, ranking therapists by total appointments:
RANKXTherapist =
RANKX(
ALL( fAppointments[Therapist] ),
[Total Appointments],
, DESC,
Skip
)
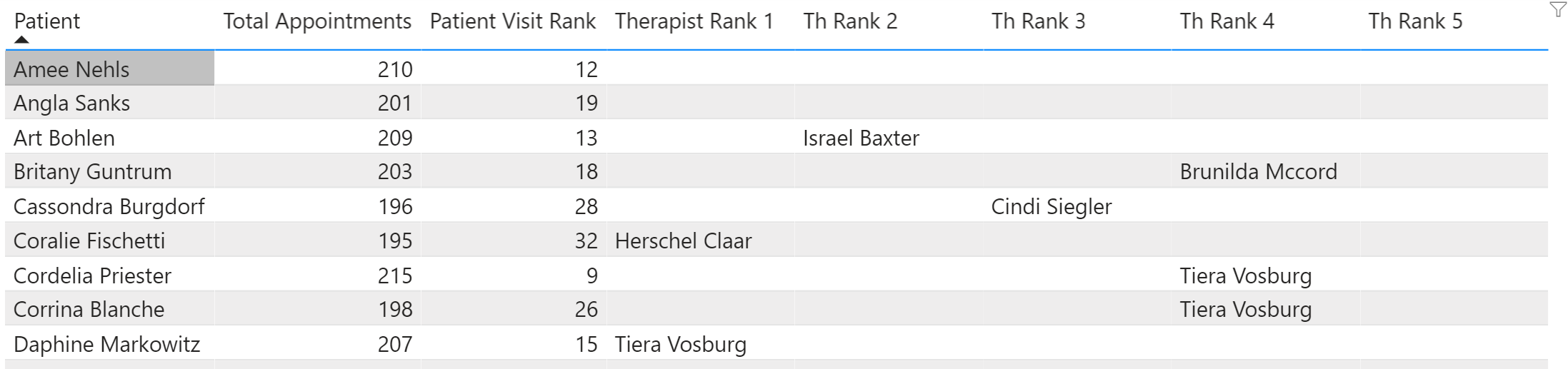
The second one does the heavy lifting, creating a virtual table that overrides the matrix evaluation context for the ranking, handles ties through the alternate condition in SELECTEDVALUE, and does the HASONEVALUE trapping at the end:
Therapist Rank #1 =
VAR SelPatient = SELECTEDVALUE( fAppointments[Patient] )
VAR vTable =
CALCULATETABLE(
ADDCOLUMNS(
SUMMARIZE(
fAppointments,
fAppointments[Therapist]
),
"TotAppt", [Total Appointments],
"TherRank", [RANKXTherapist]
),
FILTER(
fAppointments,
fAppointments[Patient] = SelPatient
)
)
VAR TherAtRank =
CALCULATE(
SELECTEDVALUE(
fAppointments[Therapist],
"Tie"
),
FILTER(
vTable,
[TherRank] = 1
)
)
RETURN
IF(
HASONEVALUE( fAppointments[Patient] ),
TherAtRank,
BLANK()
)
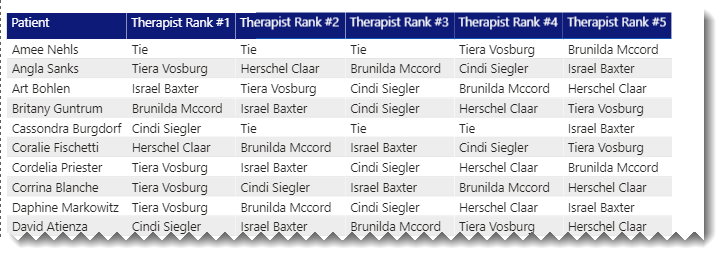
Here’s what it looks like all put together:
I think this gets you what you were looking for, but given the frequency of ties, you may want to consider a secondary criteria to use as a tiebreaker.
I hope this is helpful. Full solution file posted below.
P.S. @pshetty - you are up next. Between a really busy work week, and this one taking longer to crack than I expected, I’m behind on your solution, but will get to it later today. Thanks for being patient, sorry for the delay.