Hey gang,
Does an Sql data base drastically improve the speed of a power bi refresh over and above data in Excel?
Chris
Hey gang,
Does an Sql data base drastically improve the speed of a power bi refresh over and above data in Excel?
Chris
I know very little about SLQ, but I recall reading an article from Chris Webb where refresh on a large flat file took nearly 7 times longer in his testing then refresh from an optimized dimensional model. I also know you can test this if you have SQL Profiler installed using the external tools capability in DAX Studio.
But I’ll send up the Bat Signal to EDNA Experts @Greg and @hafizsultan , both of whom know a ton about SQL.
Hi @cms418.
For small datasets, it’s likely that there wouldn’t be a noticeable difference in loading performance, unless the speed of the network connections differ and/or the loading of the database server itself is high. For large datasets, however, I would choose a SQL Server database data source over an Excel data source every time.
Another “feature” of Excel (at least back in the mid-2010s, not sure if it still applies…) is that it considers only the first 7 rows of a spreadsheet to determine the column data type, and given that Excel cells can contain anything, it is incumbent upon the the spreadsheet author to have only a single, consistent data type per column. A SQL Server data source will always have a defined data type for every column, so consistency is ensured.
At the end of the day, however, the typical consultant’s answer “… it depends …” is the best I can give. The specific scenario (e.g., what is the data set area [rows x columns], network access speed, database server loading, etc.) will need to be tested to discover the best solution for each application.
Greg
(P.S.: I’ll pencil-in a test for the near future where I make up and load both a small and large dataset from both Excel and SQL Server and see what the differences in loading performance are, and I’ll add my findings to this post when available.)
Thanks that would be great!
I’m your humble opinion, what’s the line of small vs large in a data set?
Hi @cms418. Again, “… it depends …”. As a rule of thumb, I probably would say any dataset with a fact table under 10K rows would be “small”, while those over 100K would be “large”, but, again, in the end, testing on the specific infrastructure would be way forward.
Greg
@cms418 Yeah, it does, add some indexes on your columns and you have got your own columnar database. When data is connected to Excel and Text file you will notice that almost all the steps go back to the source to re-fetch the data but that doesn’t happen very frequently in SQL, also with databases you get native query options so if you plan your transformation steps correctly you can compute most of the transformation in the database itself even though you made the transformation in Power Query.
I load data into databases even for 20K rows because multiple steps like List.Min / List.Distinct makes Power Query engine to load data again and again and then it can get boring to wait every now and then.
Hi @cms418, did the response provided by the users and experts help you solve your query? If not, how far did you get and what kind of help you need further? If yes, kindly mark as solution the answer that solved your query. Thanks!
Waiting for a response when further testing is done. Please keep thread alive
Hello @cms418, a gentle follow up if the solution of the experts and users above helped your inquiry?
Hi @cms418.
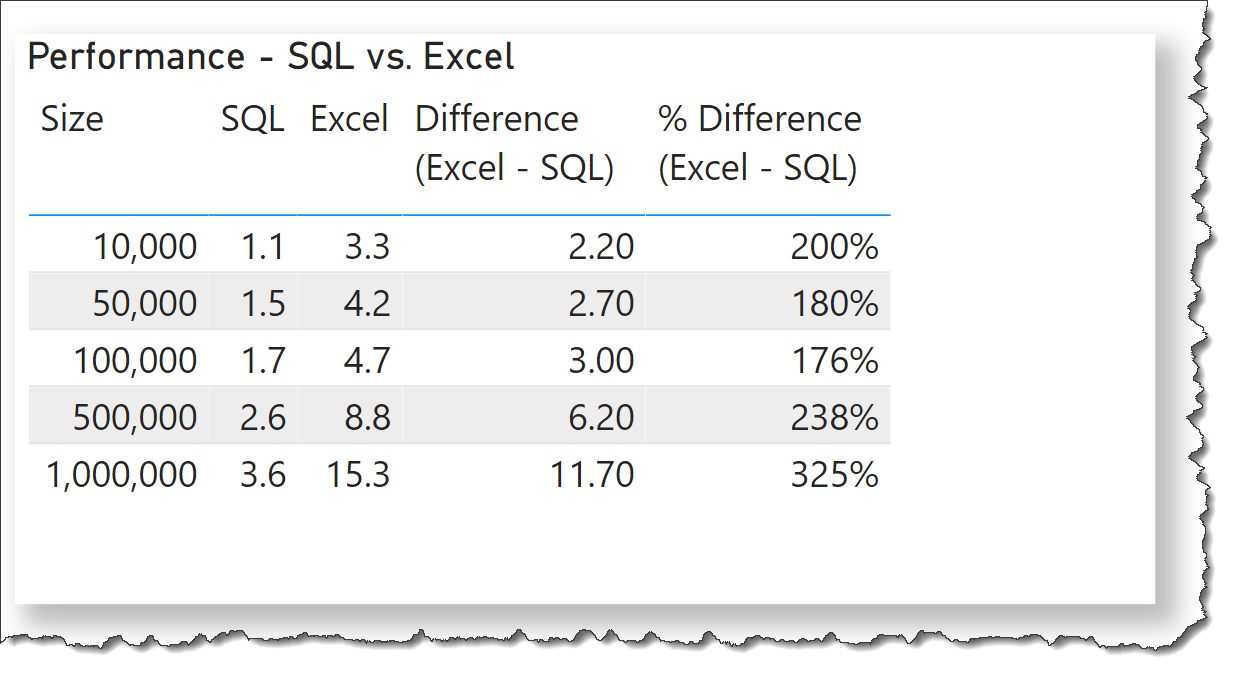
I threw together a quick comparison of SQL vs. Excel on a test machine and found, as expected, SQL is faster in all cases, especially so as the dataset size gets larger. I used the exact same data and number of rows for each source, and using crude stopwatch timings, found the following:
I’m a very light user of Excel, but from what I understand (or at least with my default configuration), an Excel spreadsheet is limited to just over a million rows as well.
Hope this helps.
Greg
Yes, using a SQL database will generally improve the speed of a Power BI refresh compared to using Excel, especially as the dataset size increases. SQL databases are specifically designed to handle large volumes of data more efficiently and provide optimized query performance, whereas Excel is not built for managing very large datasets and can experience slowdowns related to processing speed and memory usage.
SQL databases are capable of optimizing complex queries, reducing the time needed to retrieve data. They store data in a structured format that Power BI can query and load more quickly than Excel. In addition, SQL databases support indexing and more efficient joins, which Excel cannot match. Another advantage is that SQL databases can handle multiple users querying and updating data at the same time, while Excel tends to slow down when shared across many users.