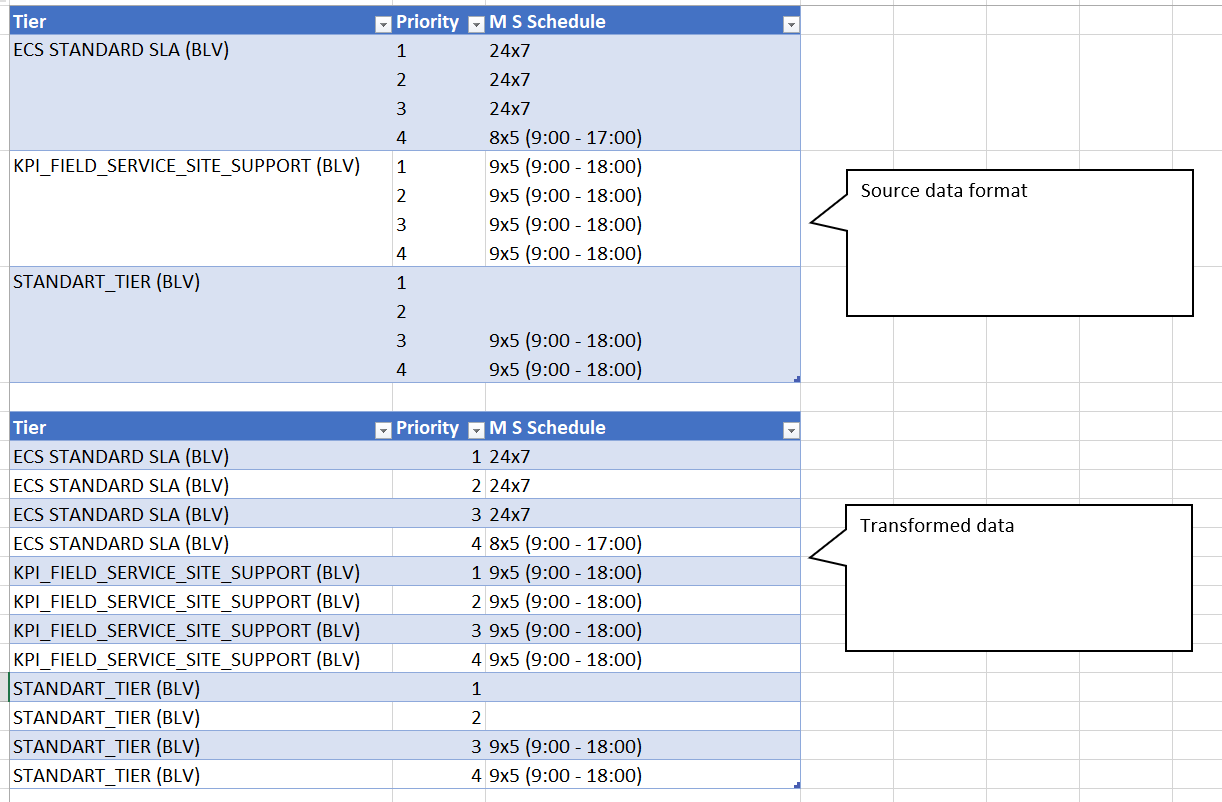
Hi @Roberto,
See if this works for you.
Copy and paste this M code into a new blank query
let
Source = Table.FromRows(Json.Document(Binary.Decompress(Binary.FromText("i45WcnUOVggOcfRzcQxyUQj2cVTQcPIJ01TSUTKMKYrJMwIRxiDCBChkZFJhDhRDIi0qTBU0LK0MDBR0FQzNgbSmUqxOtJJ3gGe8m6erj0t8sGtQmKeza3ywZwiQCA0I8A8KwWeFJbKBFiADY/LIFwM7Buq7kPgQT9cgfHbH5BFvbiwA", BinaryEncoding.Base64), Compression.Deflate)), let _t = ((type nullable text) meta [Serialized.Text = true]) in type table [Tier = _t, Priority = _t, #"M S Schedule" = _t]),
GetValues = Table.AddColumn(Source, "Temp", each List.Zip( { List.Transform(Text.Split([Priority], "#(lf)"), Text.Clean), List.Transform(Text.Split([M S Schedule], "#(lf)"), Text.Clean) }))[[Tier], [Temp]],
ExpandLists = Table.ExpandListColumn(GetValues, "Temp"),
ExtractValues = Table.TransformColumns(ExpandLists, {"Temp", each Text.Combine(List.Transform(_, Text.From), "|"), type text}),
SplitColumn = Table.SplitColumn(ExtractValues, "Temp", Splitter.SplitTextByDelimiter("|", QuoteStyle.Csv), {"Priority", "M S Schedule"})
in
SplitColumn
.
This is the key part
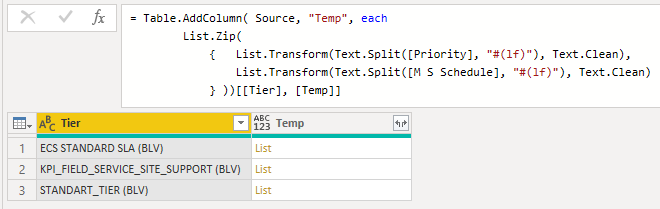
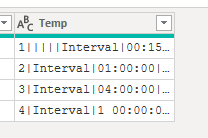
Splitting the text on line feeds, that returns a list, these values needed some cleaning so added the List.Transform in combination with Text.Clean.
Because there’s an equal number of values in both columns, I’m bringing them together based on their position with List.Zip so I’m left with a single list of lists.
And finally using projection to only keep the [Tier] and [Temp] column.
Here’s your sample file.
split multirows cells.pbix (20.7 KB)
I hope this is helpful.