Hi @Sam ,
Thanks for your help
Roberto
splitting multiple columns.pbix (24.0 KB)
Hi @Roberto ,
Is this an accurate representation of your data OR is it intended to represent a Record type value in the last 2 columns?
If that’s how your data is actually structured, you can give this a go. Just copy and paste into a new blank query:
let
ColsToTransform = { "Probabilities", "Knowledge articles" },
Source = Table.FromRows(Json.Document(Binary.Decompress(Binary.FromText("jY9BCoAgEEWvEq4l/jhpzrZWEXQB8xjdPyNE0UXthsfM400IajtWw0RsZVJahfMCzIzR+3fSQyawHWlBPorFtC8gOCONLmFY9uI6TPDC/XYtiSrqEu5g63A3tVVkvkm+asppZqG+5cH4/VAlSeXxBg==", BinaryEncoding.Base64), Compression.Deflate)), let _t = ((type nullable text) meta [Serialized.Text = true]) in type table [Incident = _t, Probabilities = _t, #"Knowledge articles" = _t]),
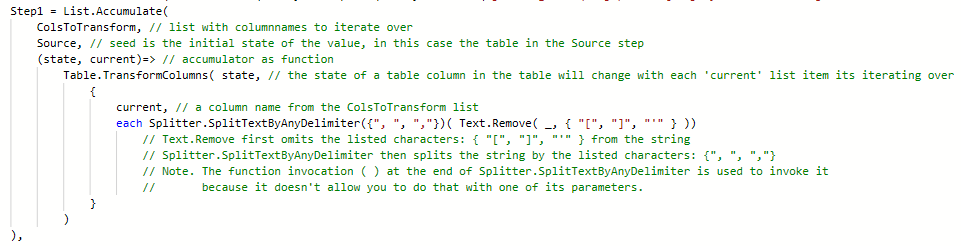
Step1 = List.Accumulate( ColsToTransform, Source, (state, current)=> Table.TransformColumns( state, { current, each Splitter.SplitTextByAnyDelimiter({", ", ","})( Text.Remove( _, { "[", "]", "'" }) )} )),
Step2 = Table.AddColumn(Step1, "NewValue", each Table.FromColumns( { [Probabilities], [Knowledge articles] }, ColsToTransform )),
Step3 = Table.RemoveColumns(Step2, ColsToTransform ),
Step4 = Table.ExpandTableColumn(Step3, "NewValue", ColsToTransform, ColsToTransform)
in
Step4
.
I hope this is helpful
2 Likes
Melissa:
let
ColsToTransform = { "Probabilities", "Knowledge articles" },
Source = Table.FromRows(Json.Document(Binary.Decompress(Binary.FromText("jY9BCoAgEEWvEq4l/jhpzrZWEXQB8xjdPyNE0UXthsfM400IajtWw0RsZVJahfMCzIzR+3fSQyawHWlBPorFtC8gOCONLmFY9uI6TPDC/XYtiSrqEu5g63A3tVVkvkm+asppZqG+5cH4/VAlSeXxBg==", BinaryEncoding.Base64), Compression.Deflate)), let _t = ((type nullable text) meta [Serialized.Text = true]) in type table [Incident = _t, Probabilities = _t, #"Knowledge articles" = _t]),
Step1 = List.Accumulate( ColsToTransform, Source, (state, current)=> Table.TransformColumns( state, { current, each Splitter.SplitTextByAnyDelimiter({", ", ","})( Text.Remove( _, { "[", "]", "'" }) )} )),
Step2 = Table.AddColumn(Step1, "NewValue", each Table.FromColumns( { [Probabilities], [Knowledge articles] }, ColsToTransform )),
Step3 = Table.RemoveColumns(Step2, ColsToTransform ),
Step4 = Table.ExpandTableColumn(Step3, "NewValue", ColsToTransform, ColsToTransform)
in
Step4
Hi @Melissa ,
Thanks so much
Roberto
1 Like
I’ve annotated it below, hope that helps.
You might also want to read Rick de Groot’s post, this also includes a link to his blog.
and this post by Gill Raviv
Following a reader’s request, today we will unleash the power of List.Accumulate. The official documentation on List.Accumulate here was very confusing for me: List.Accumulate(list as list, seed as any, accumulator as function) as any...
Est. reading time: 6 minutes
… maybe a video is helpful as well
2 Likes