So to create a table of unique customers, I have removed Duplicates by the Student ID column. What I am noticing is that because there are multiple years and because some of the columns turn up as blank I lose information on some individuals like their Gender and Age Group. Why the information was not reflected in all academic years is beyond me. This may be something beyond the capabilities of Power BI but how do I remove duplicates but also capture information about the individual from that respective year? Or when removing duplicates does Power BI take the first appearance of the Student ID or the most recent appearance of the Student ID?
If detail change for a particular student then this strategy won’t work, because yes remove duplicates will find the first instance of a student and only keep that row of information.
Question - have you gone through this course yet?
Nearly all the questions you are asking are covered in this course, and getting a really good base knowledge around the model is essential.
1 Like
I havent made it this far yet but I will jump to it.
Hi,
I came across this issue, when removing duplicates from data showing barcode scans of parcels moving through a transportation network and found a solution on the web, presented by Andreas Thehos.
https://www.youtube.com/watch?v=wS2GVXQdCHc 4:28 It is in German language but I trust it will help
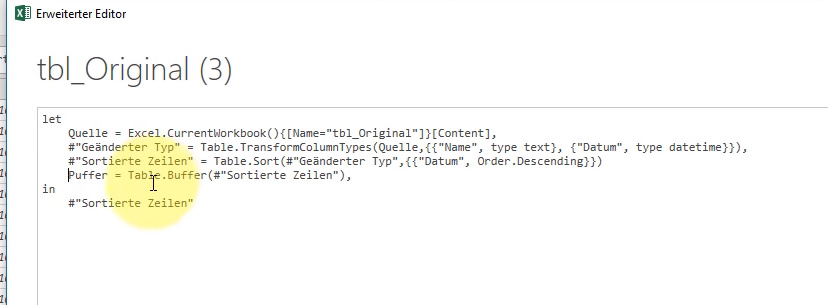
When removing duplicates from records with dates, it is important to first sort descending and then in the query editor add a line that triggers the buffer, otherwise the wrong instance of the records may be removed.
Paul
![]()