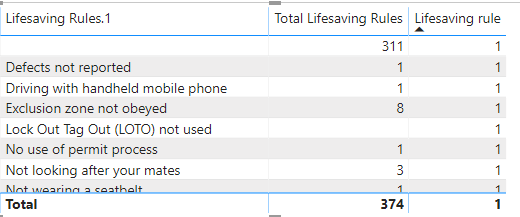
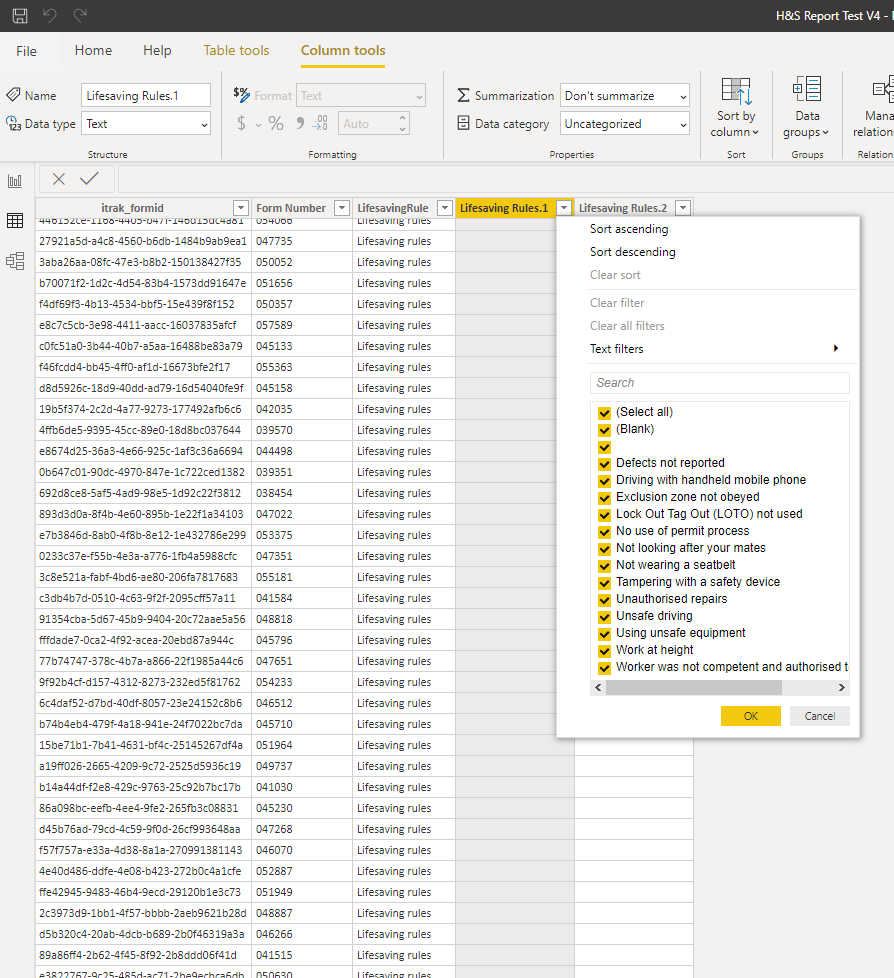
I have used the RANKX function to calculate the ranking of data for a column in my data set my issue is i have a large number of fields in the column that have N/A as the data, i used the replace function to replace N/A with an empty field but it is still counting these fields in the calculation. How can i exclude the empty fields so the ranking calculates based on only the fields that has data in them.
Any help appreciated - thanks
Lifesaving rule = RANKX(ALL(‘Lifesaving Rules’[Lifesaving Rules.1]),[Total Lifesaving Rules],desc)
Try wrapping your RANKX in a CALCULATE function in order to change the filter context, and add filters to exclude the rows where the relevant fields are blank:
Please try to understand context. It says when Lifesaving Rule.1 is blank, dont calculate rank. But in your case, it is not blank. Instead your measure/column(Total Lifesaving Rule) is blank. So, you may adjust formula and try below:
This is why you always get the best answer/support when you provide a PBIX along with your question. When we’re providing DAX solutions based on a general description, we have to guess field or measure, and assume a particular data model which may or may not be correct (often DAX problems are not really DAX problems, but data modeling problems). However, if we can test the solution first even on a sample PBIX file, we can be sure that what we provide you will work for your particular situation/model.
Unfortunately, not really. The best would be if you could post a PBIX with any sensitive information masked, or just representative sample data used in place. In lieu of that, the next best thing would probably be a screenshot of your data model, showing all the relevant field names.
Hi Brian, i have recreated the scenario in the attached pbix file. I was wondering whether the issue is with my total lifesavings rule calculation where i have used count rows so the calculation is counting the rows in that column that has no data, would the solution ne to filter out the blank rows in in the countrows calc?