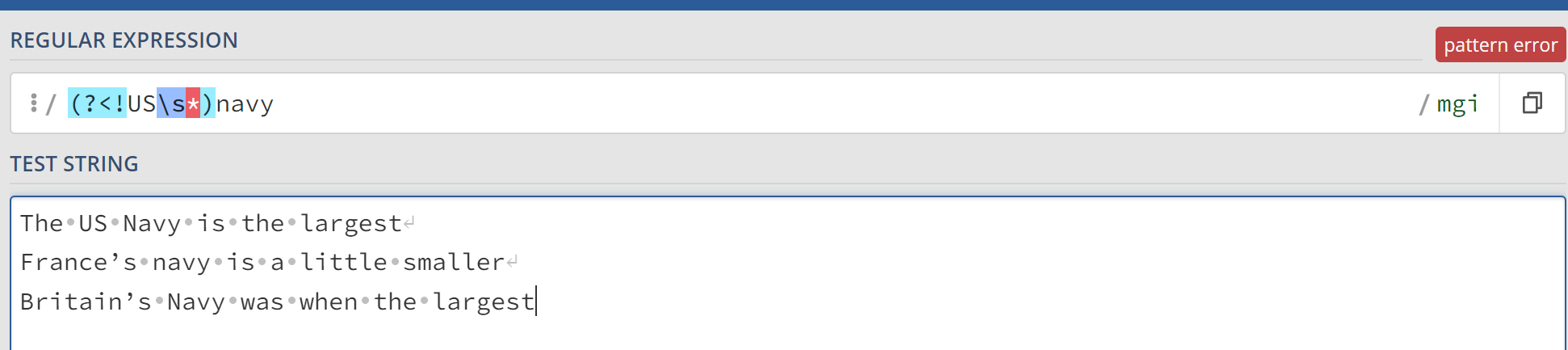
One thing that drove me bonkers on Problem 4 was why the * quantifier after \s throws an error? Seems to me it should specify zero or more whitespaces after US…
import re
#task2
string_task2 = """
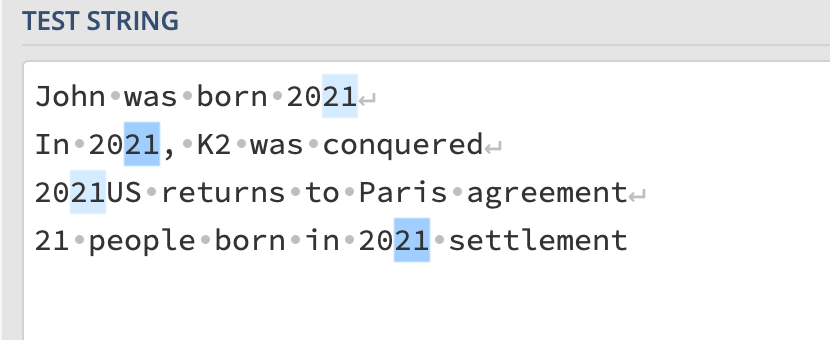
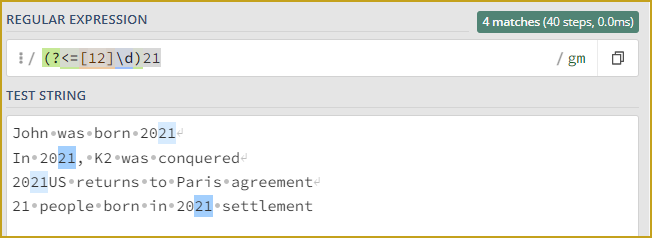
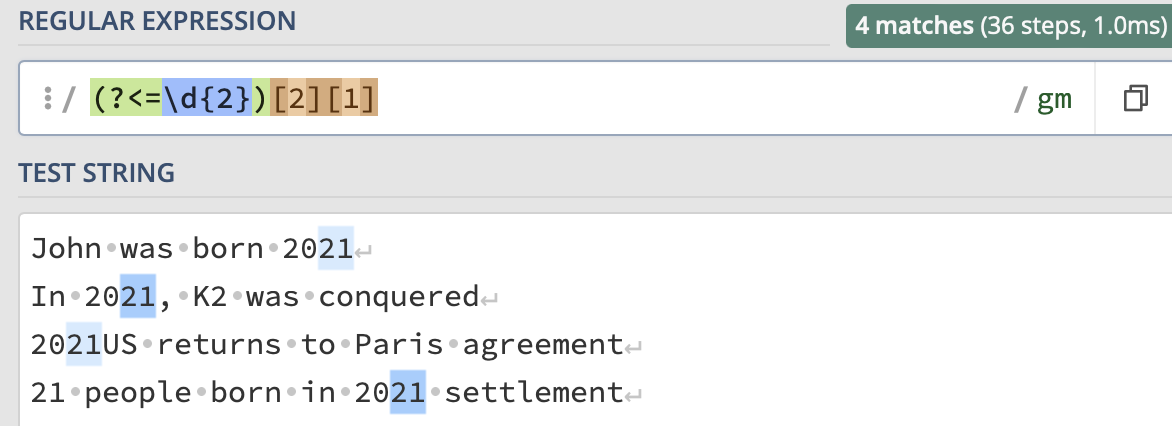
John was born 2021
In 2021, K2 was conquered
2021US returns to Paris agreement
21 people born in 2021 settlement
"""
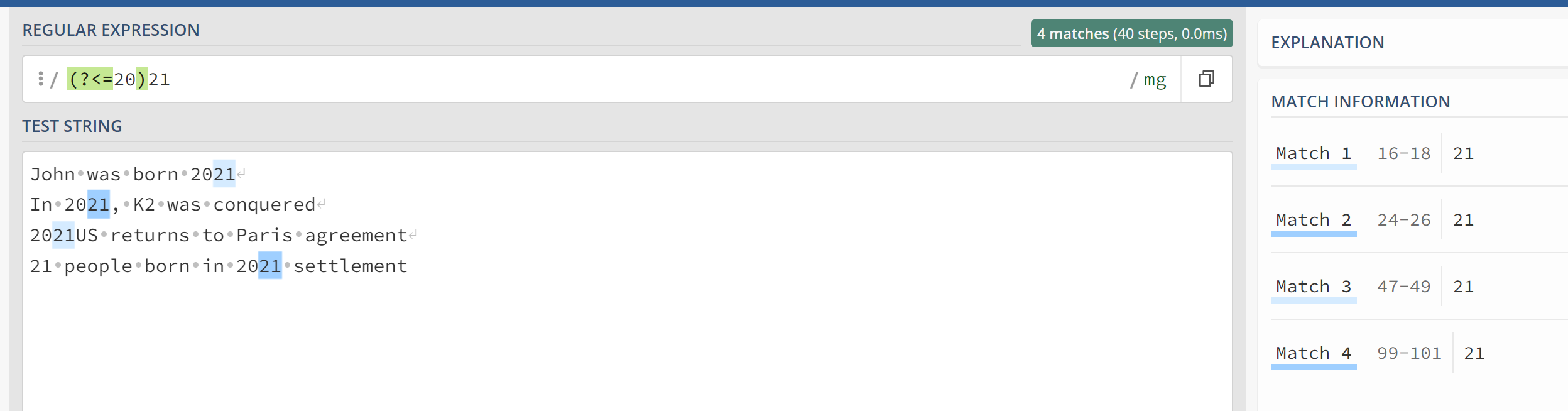
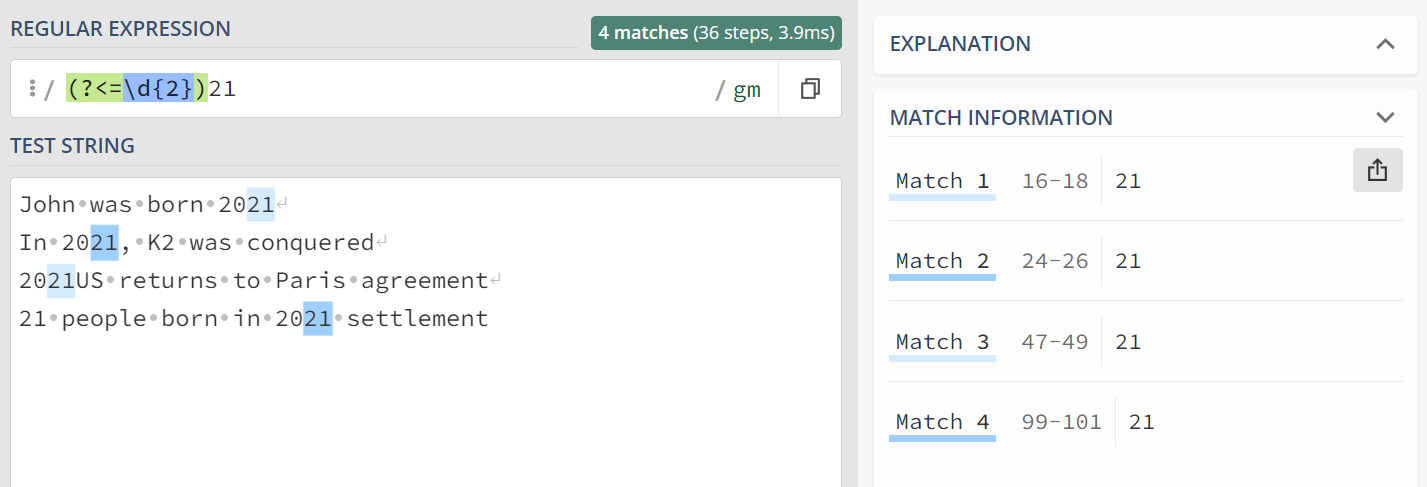
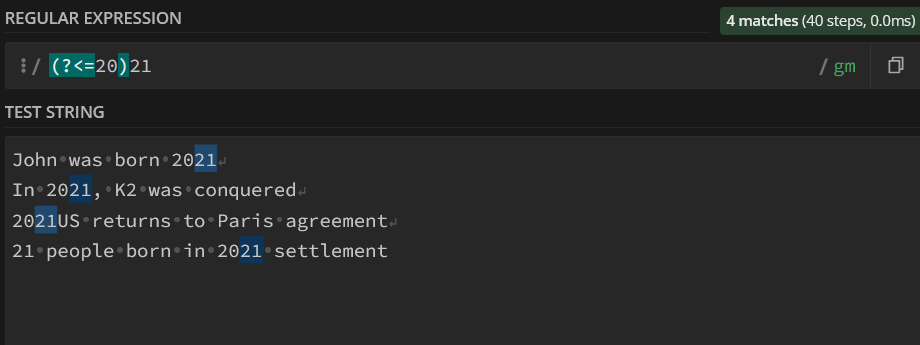
regexp_task2 = r"[1-2][0-9](21)"
matches_task2 = re.findall(regexp_task2,string_task2,re.MULTILINE)
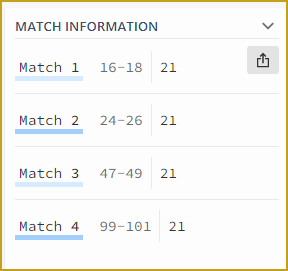
print("Number of 21 part of a year : " + str(len(matches_task2)))
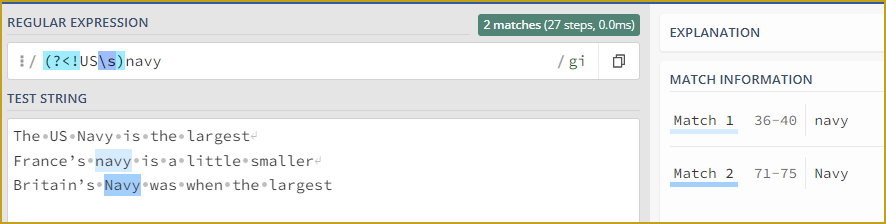
import re
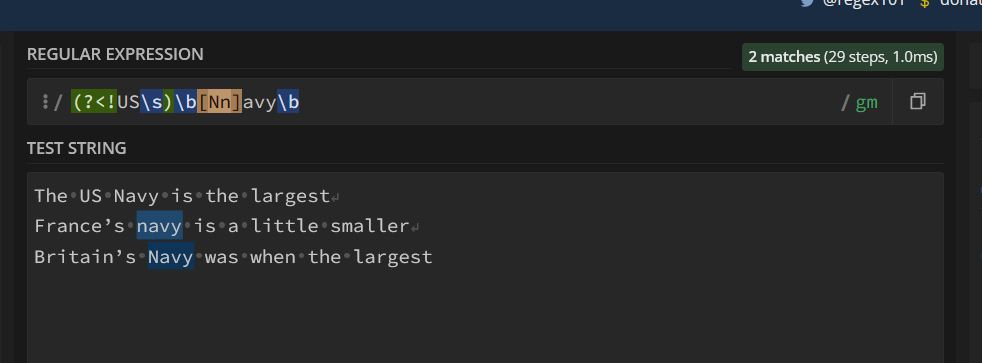
string_task4 = """
The US Navy is the largest
France’s navy is a little smaller
Britain’s Navy was when the largest
"""
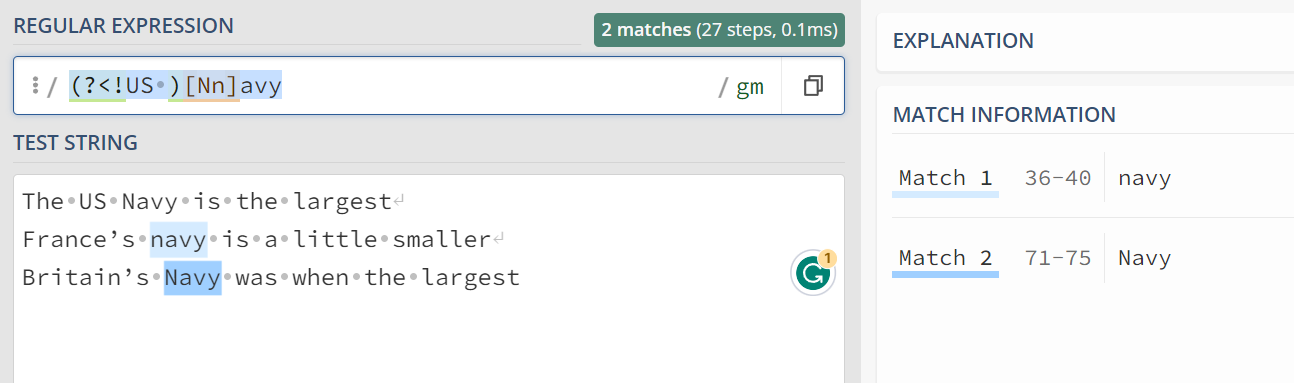
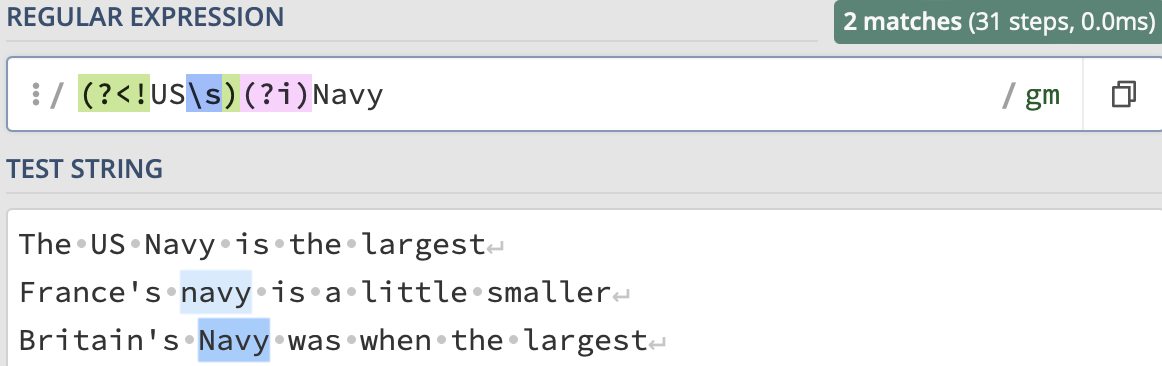
regexp_task4 = r"(?<!US\s)\b(Navy|navy)\b"
matches_task4 = re.findall(regexp_task4,string_task4)
print( matches_task4 )
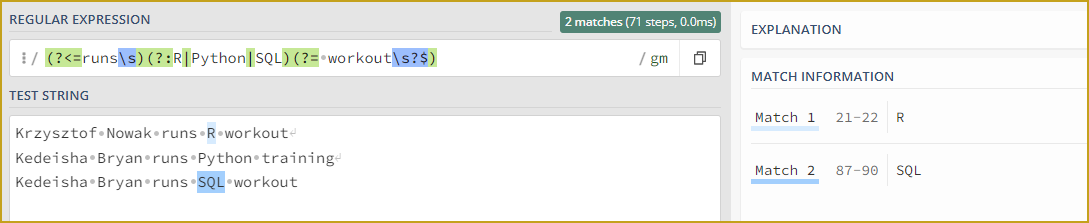
+: Matches one or more occurrences of the preceding pattern.
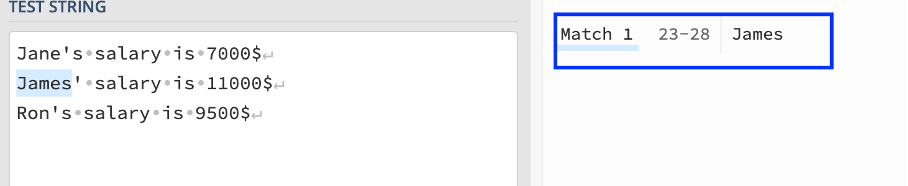
These sections make up the name. We did not use any tool that would refer to “’ 's”.
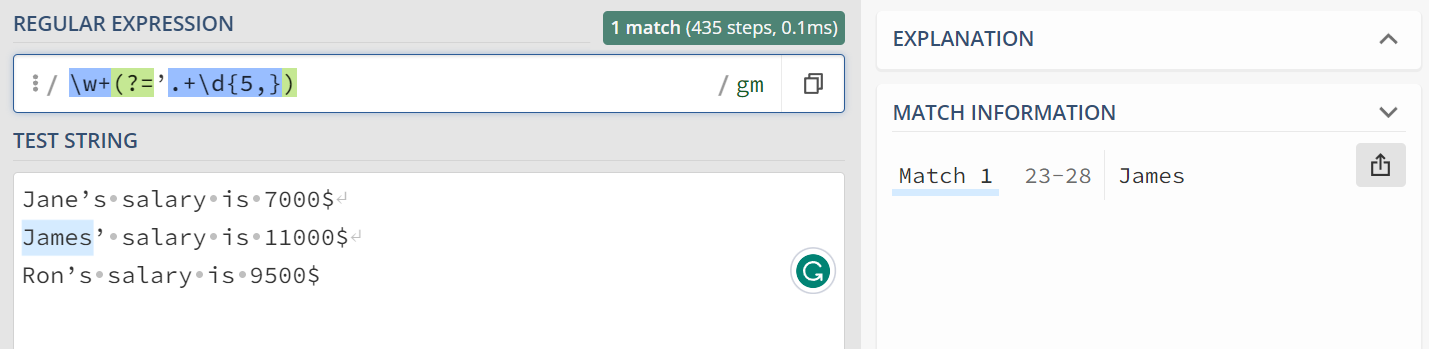
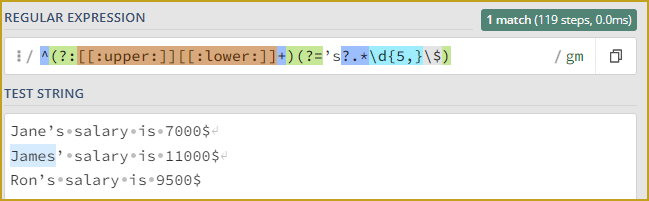
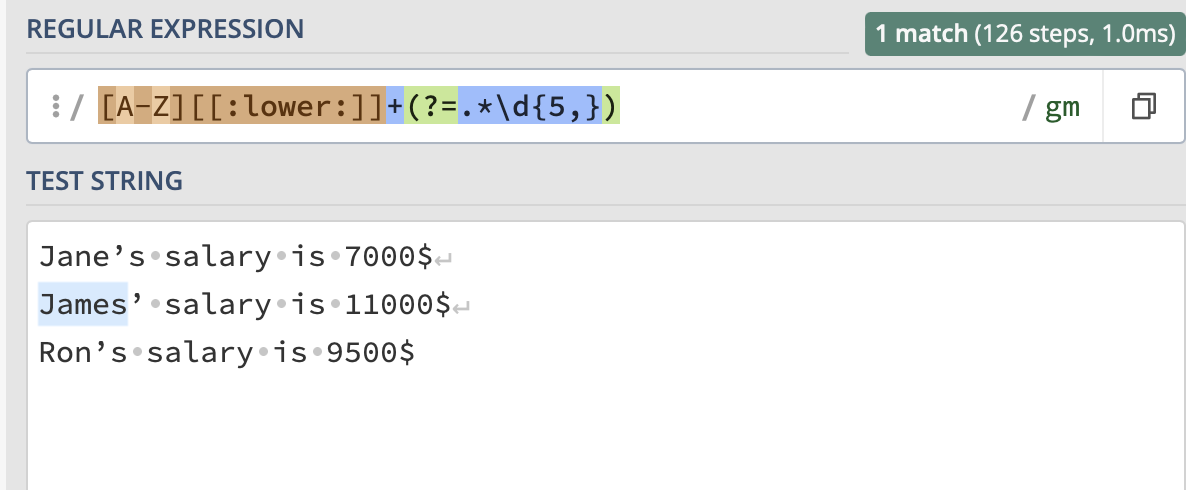
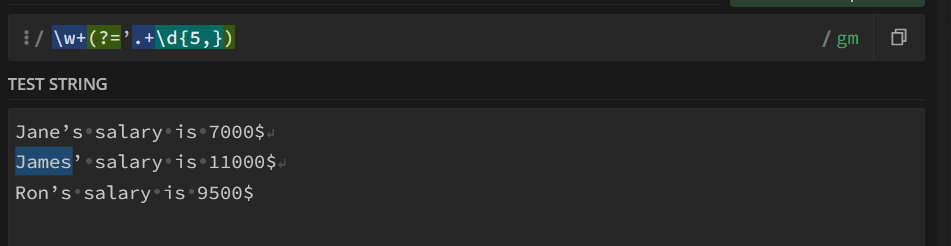
(?=.*\d{5,}): Positive lookahead (look into regex101.com Quick reference for this concept) assertion that checks if the string contains at least five consecutive digits. In case of James, “11000” satisfies this condition.
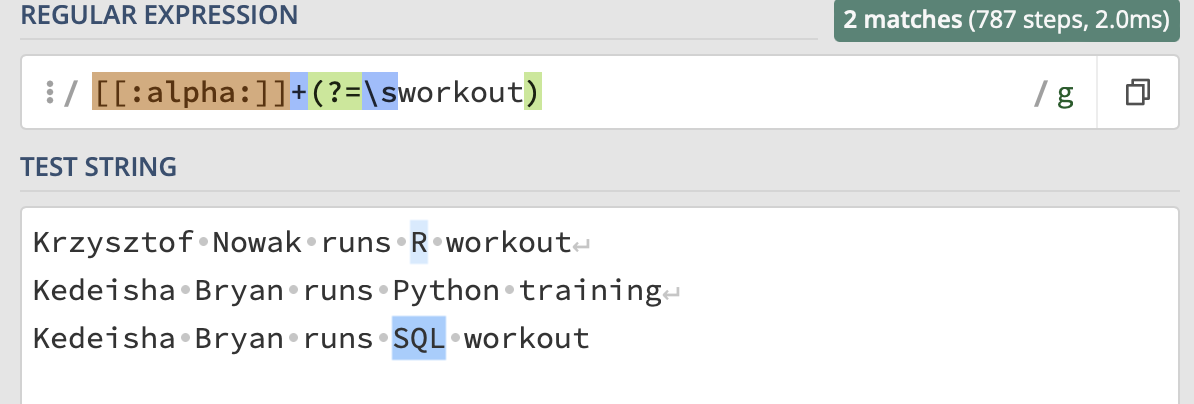
[[:alpha:]]+: Matches one or more alphabetical characters.
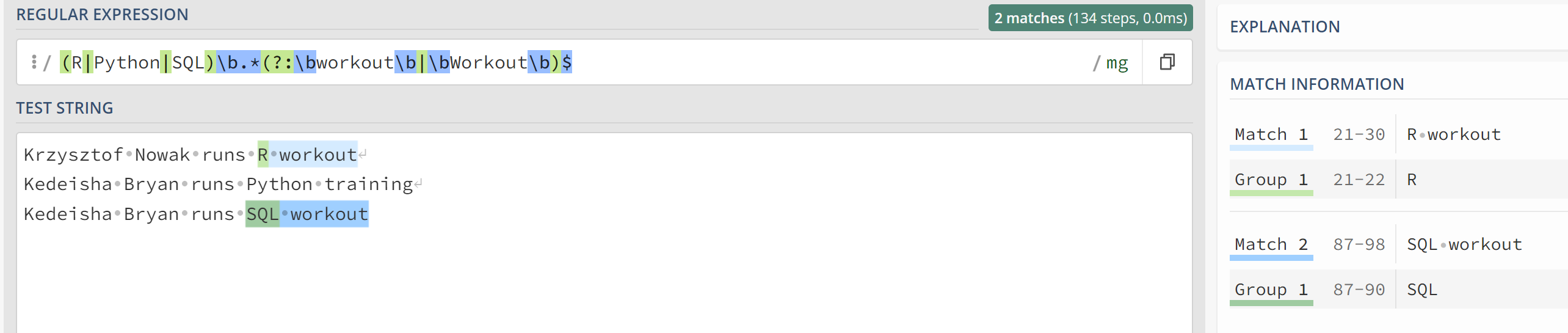
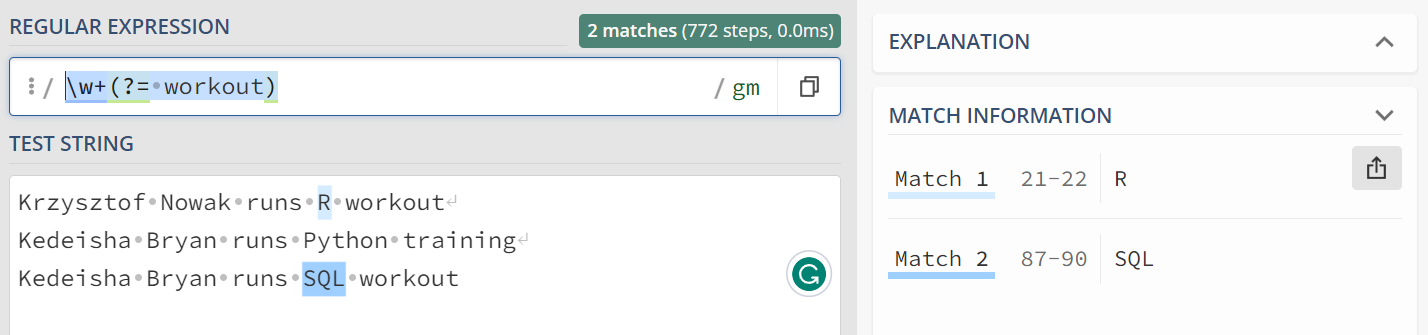
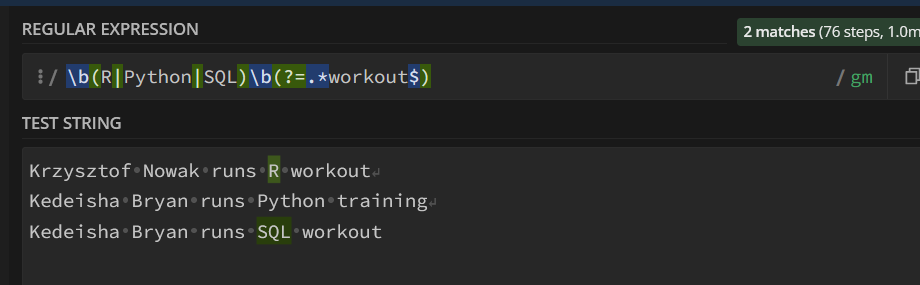
2.(?=\sworkout): Positive lookahead assertion that checks if the characters following the matched alphabetical characters are a space followed by the word “workout”
(?<!US\s): Negative lookbehind assertion that checks if the preceding characters are not "US " (the letters “US” followed by a space). This ensures that the word “Navy” is not preceded by "US ".
(?i): Case-insensitive matching. It allows matching “Navy” regardless of its case (upper or lower).
Navy: Matches the word “Navy” as it is.
Your solutions are ok, but a bit more like grouping. I encourage you to look into concepts that will help to cut very specific parts of the text omitting their surroundings.Nice Python skill!
Hello @alex-badiu , thank you for submission. All looks great. For task 1 I would just choose range opened on the right side so that it includes salaries greater than 5 digits {5,}