Hi all,
Hoping someone can help me with my RANKX Dax. Sam has many great videos on Ranking, but I just seem to be going around in circles with this one!
Please see attached mock up, where I have tried to simplify my and demonstrate my problem.
We have 2 Brands, Asda and Tesco. Within each one, there are Sites, such as Asda Basingstoke. And within each Site there are Sales Persons, such as John.
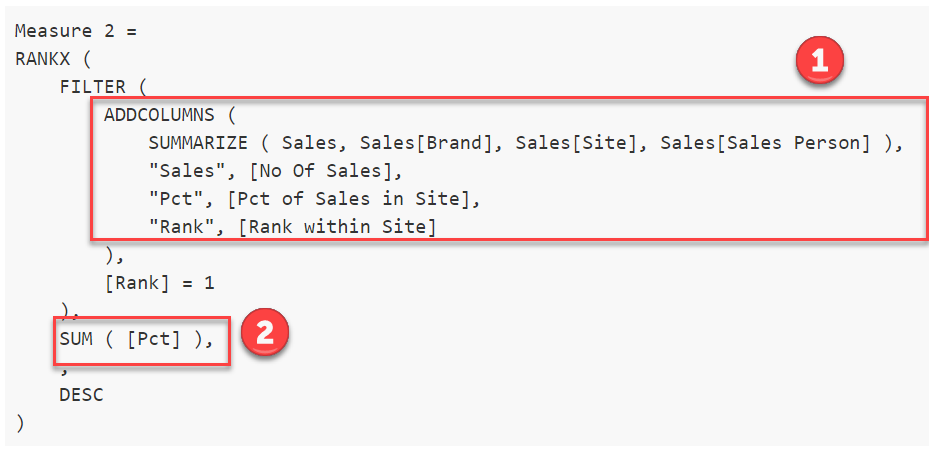
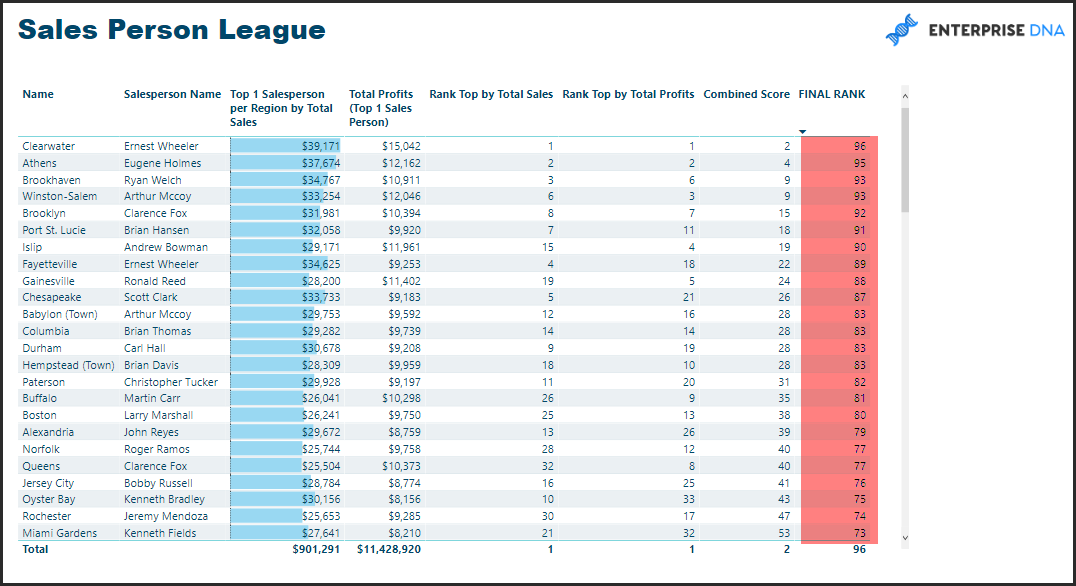
My ultimate goal is to return a table showing the top 1 Sales Persons per site, along with their rank within their Brand and their rank among all of the top sales people.
I have started with measures, Percentage of Sales in Site / Brand / All, which compare the Sales Persons individual sales, with that of all sales in the site, brand or all:
Percentage of Sales in Site =
var __SalesBySite = CALCULATE([No Of Sales], ALL(Sales[Sales Person]))
RETURN
DIVIDE([No Of Sales], __SalesBySite, 0)
.
Pct of Sales in Brand =
var __SalesByBrand = CALCULATE([No Of Sales], ALL(Sales[Sales Person]), ALL(Sales[Site]))
RETURN
DIVIDE([No Of Sales], __SalesByBrand, 0)
.
Pct of Sales in ALL =
var __SalesByAll = CALCULATE([No Of Sales], ALL(Sales[Sales Person]), ALL(Sales[Site]), ALL(Sales[Brand]))
RETURN
DIVIDE([No Of Sales], __SalesByAll, 0)
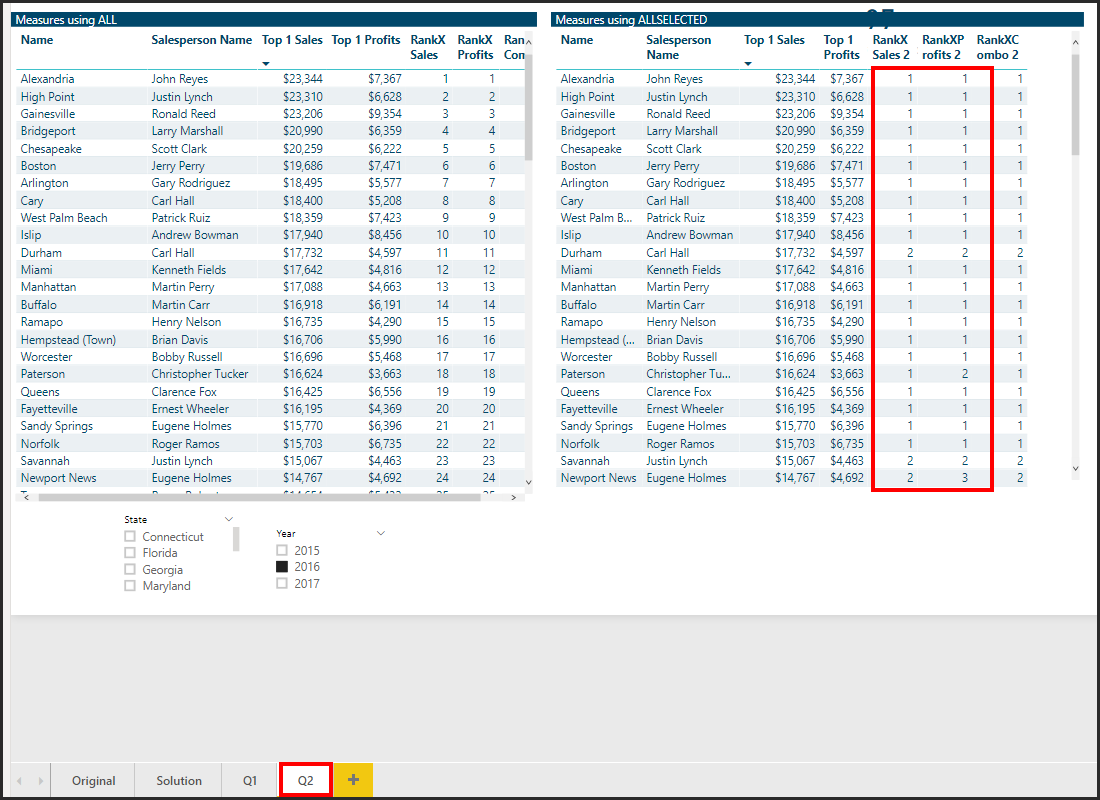
I have then created ranking measure over each, eg ‘Rank within Site’, which correctly ranks the Sales Persons within their site, based on their percentage of sales.
Rank within Site =
RANKX(ALL(Sales[Sales Person]), [Percentage of Sales in Site], , DESC)
This gives me my first table with all looking ok. Lisa is the top sales person at Tesco Chester, whereas Jodie is the top sale person across all 3 measures:
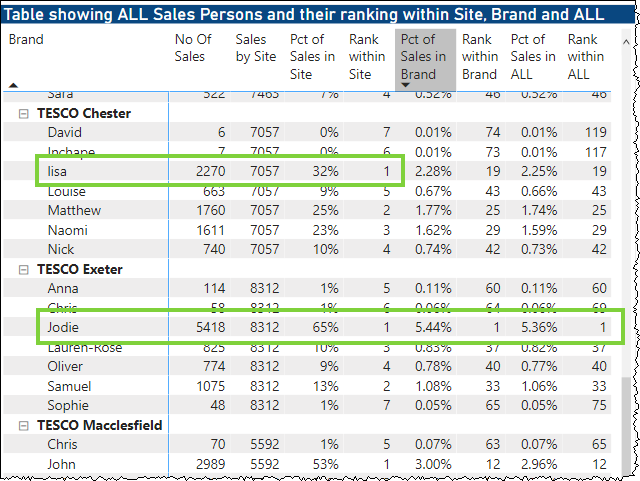
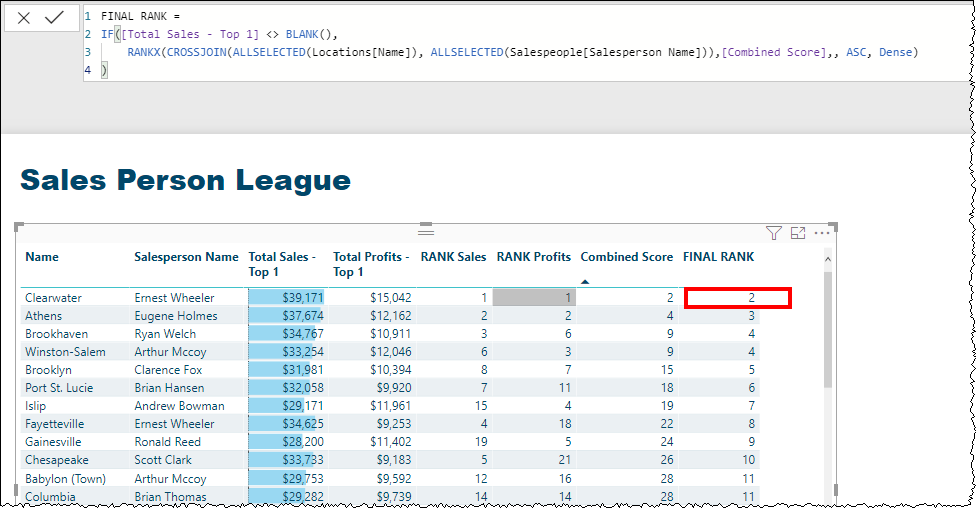
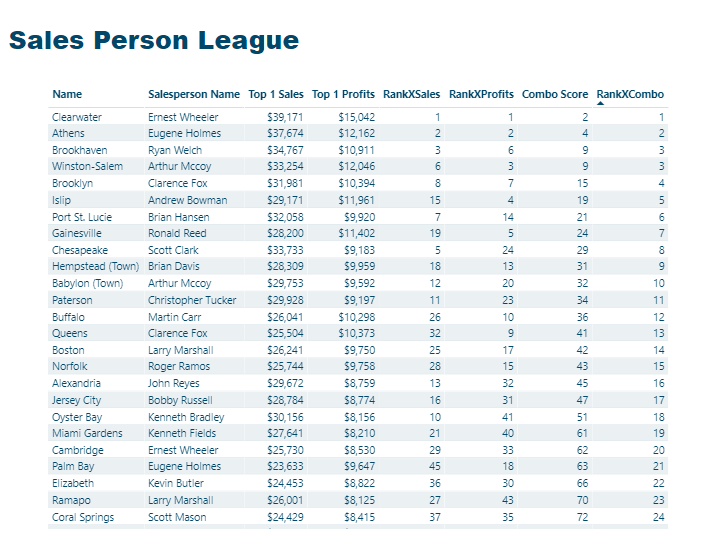
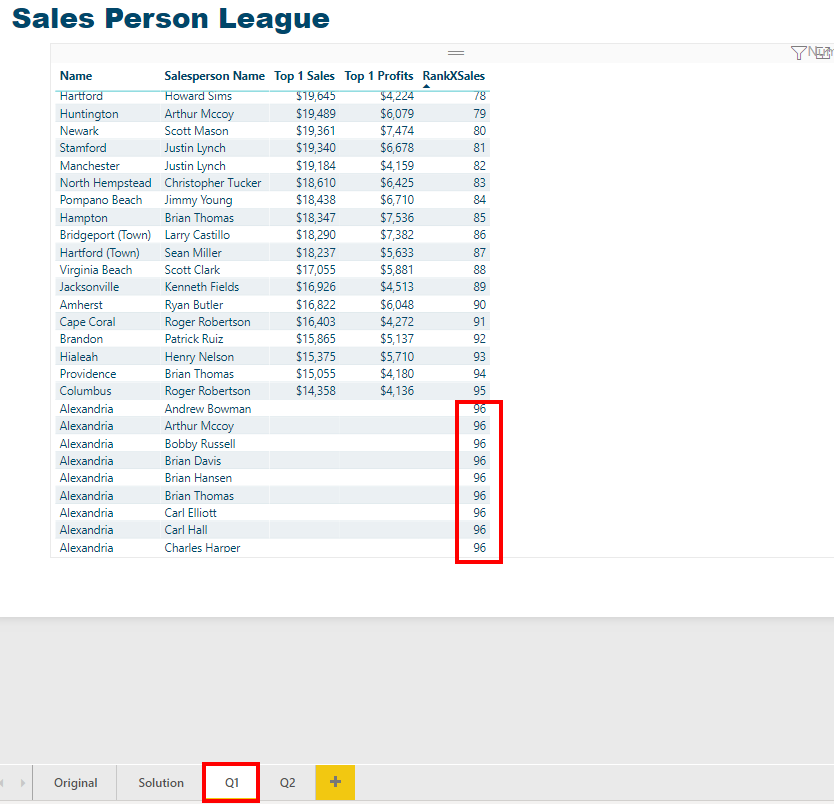
I then want to create my final table, just returning the top sales persons from each site. I have initially done this by filtering the Matrix, where Rank within Site = 1. However I am sure there is a better way to do this using DAX and TOPN?
But the result is not quite as desired:
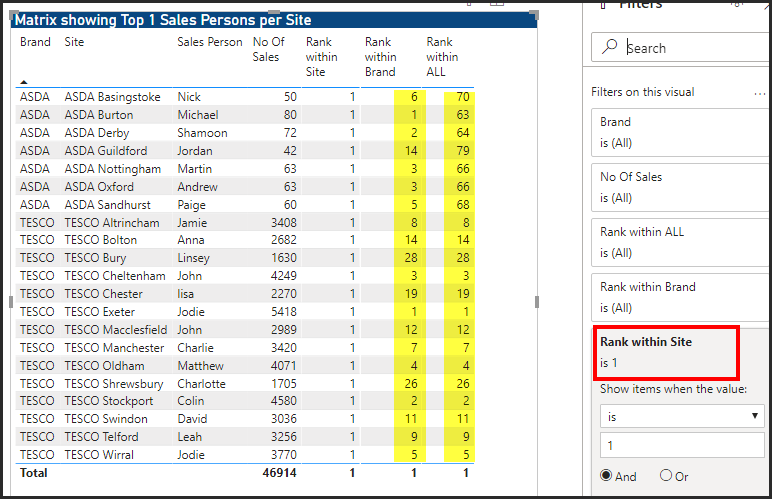
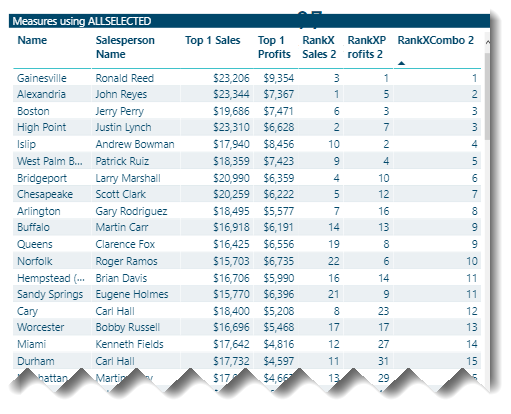
My ranks within Brand and within ALL are still based on all Sales Persons, whereas I want this to matrix to only consider the Top 21 Sales Persons, so no rank value should be greater than 21.
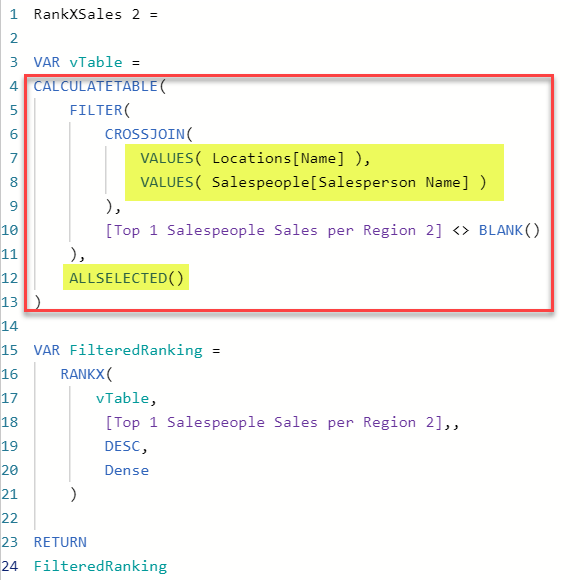
I think I therefore need to modify by Rank withon Brand and All measures, so that they calculate over this summarised dataset and not over all, I am just struggling with this concept!
Hopefully the above is relatively clear, any help appreciated as always!
Thanks
Mark