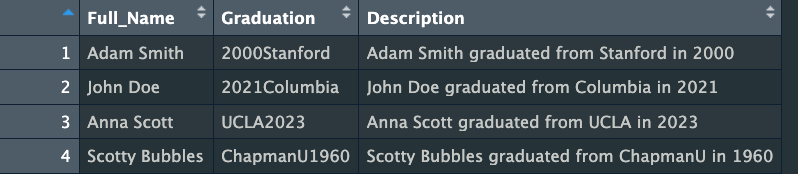
The purpose of this exercise is to extract information from a column containing data of different types (Name of university, year of graduation) and create a new column with a description of the graduate. It is to consist of the following components: Full_Name +“” graduated from " + [School Name] + " in " [Graduation Year]
Base table:
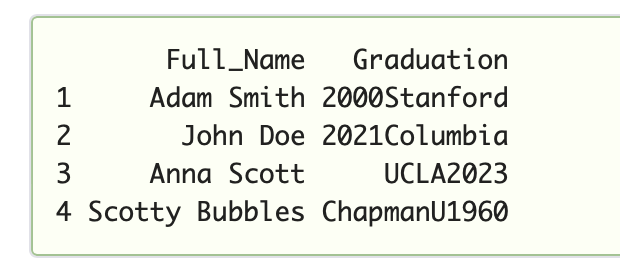
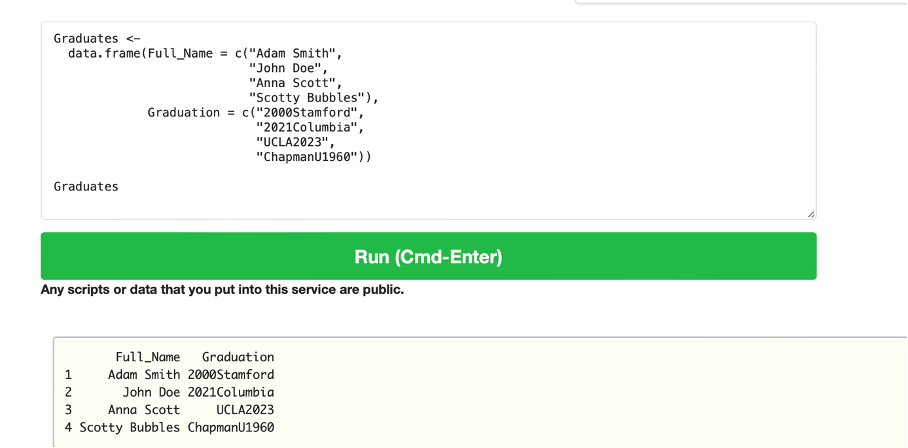
Expected Result:
Source:
Graduates ←
data.frame(Full_Name = c(“Adam Smith”,
“John Doe”,
“Anna Scott”,
“Scotty Bubbles”),
Graduation = c(“2000Stamford”,
“2021Columbia”,
“UCLA2023”,
“ChapmanU1960”))
Tip: Use https://rdrr.io/snippets/ 2, the online R editor, if you don’t have the R environment installed.
Submission
Simply post your code and a screenshot of your results.
Please format your R code and blur it or place it in a hidden section.
This workout will be released on Monday May 01, 2023, and the author’s solution will be posted on Sunday May 07, 2023.
1 Like
@KrzysztofNowak ,
I had a fantastic time with this workout. Challenged myself to solve the ChapmanU problem, i.e. creating a regex to recognize when the extracted string ended with a lowercase followed by an uppercase, and if so to remove the final character.
This ended up sending me down an interesting regex rabbit hole. I’m sure there are more efficient ways to do this, but here’s what I came up with.
Click for R code
library(tidyverse)
library(markdown)
df2 <-data.frame(
Full_Name = c("Adam Smith","John Doe","Anna Scott","Scotty Bubbles"),
Graduation = c("2000Stanford","2021Columbia","UCLA2023","ChapmanU1960")
)
GradYear <- as.numeric(str_extract(df2$Graduation, "\\d+"))
TempGrad <- str_extract_all(df2$Graduation, "[:alpha:]+")
### Check if last two letters are a lowercase letter followed by an uppercase letter
### If that's true, removes the last letter of the string
check_string <- function(x) {
Temp2 <- str_sub(x, -2)
if (str_detect(Temp2, "[a-z][A-Z]")) {
x <- str_sub(x, end = -2)
}
return(x)
}
df2$Graduation <- lapply(TempGrad, check_string)
df2$Description <- paste(df2$Full_Name, "graduated from", df2$Graduation, "in", GradYear, sep = " ")
knitr::kable(head(df2))
Thanks for a great learning exercise!
– Brian
1 Like
Thank you for your participation Brian.
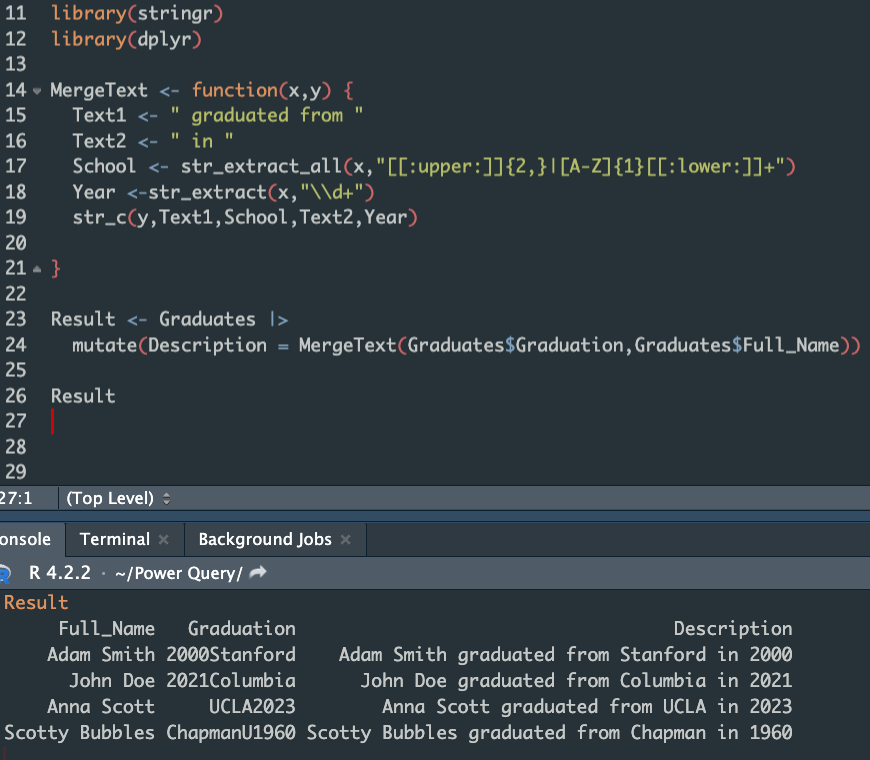
I decided to take on the same challenge and solve the problem with a larger regular expression
Result:
- In the body of my function, I define 2 static expressions as Text1 and Text2
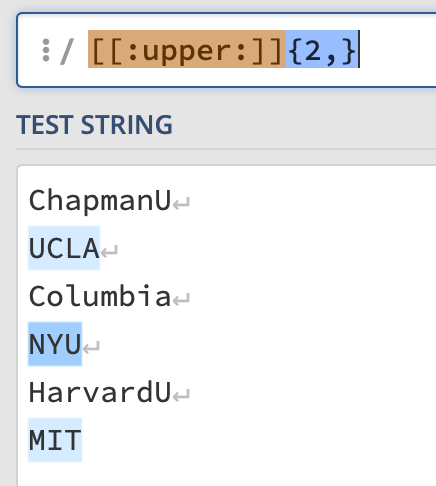
2.The “School” component is a regular expression that uses the “|” (or) operator.
The first possibility is an uppercase letter followed by a quantifier denoting a set of at least two such characters. This should capture all acronyms of schools, e.g. UCLA,MIT.
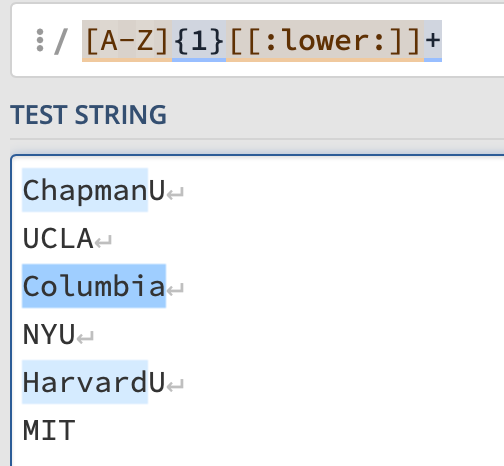
The second possibility means names that begin with a single capital letter (“{1}”). It can be followed by any number of lowercase letters (“+”) . That’s why the last capital letters in ChapmanU and HarvardU are not marked.
Pattern for “Year” component means any number of digit.
In the end all components are used as argument of str_c function.
Additional tip: If You don’t want to use external regex validation, check str_view_all() function:
Lets take a quick look at documentation of str_c and str_extract_all

1 Like
@KrzysztofNowak ,
Fantastic breakdown of the regex-based solution! Thank you for the detailed explanation – that’s a lot more robust solution than the one I provided.