Hello,
I am trying to transform my data from this:
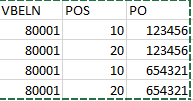
to this:
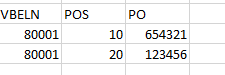
where it does not matter which PO goes with which Position, as long as the POs are unique by VBELN.
I guess I might need something recursive to check if the PO has already been attributed for that VBELN, I have tried but I can’t get there.
Can you please help me figure this out?
Thanks!
Kind regards
Valeria
@valeriabreveglieri What’s the logic behind the table you have derived to?
Hi Anktirsh,
the concat VBELN + POS should be unique
The PO should be unique by VBELN
In practice, when I join my initial VBELN/POS table to the PO table, I am getting duplicate rows for every PO.
I need to make sure that PO is unique by VBELN, which POS attribution is not important as long as PO is unique by VBELN and POS is unique by VBELN.
Thanks!
Kind regards
Valeria
Hi Valeria,
I might not understand this correctly, but if you mark PO and VBELN and then select Remove Duplicates, don’t you get exactly what you want?
Regards,
Matthias
Hi @Matthias !
No this is kind of the recursive exercise on returns you gave us in the workouts.
If I do as you say, this is the result:
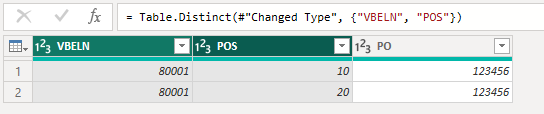
you only get 1 PO number.
Here what I had thought about is something recursive that checks whether the PO number has already been used for a certain VBELN, and in this case, it uses the other. But not being that good with List.Accumulate, I could not get it…
I did do something else though:
I grouped by VBELN and POSNR, and then gave a rank in the nested table to the VBELN/POSNR (So I have 1,2,…). Then I selected the row in the nested table where the rank was equal to the POSNR divided by 10, and this ensures me to have a different PO than the group before.
BUT I am still very interested to see if there are any other ways to do it to learn different approaches 
So not that urgent any longer, but still I’ll take if I can learn better approaches than mine!
Thanks
Kind regards
Valeria
Hello @valeriabreveglieri, thank you for adding your question to the Community Forum that is volunteer in nature, and all efforts are of best effort.
I would like to add the following constructive criticism:
Your original question was limited and did not supply the logic used in deriving the tables as @AntrikshSharma observed, and @Matthias was generous to offer his observations and suggestions.
Did you happen to have a work-in-progress Power BI Desktop file available? It’s best practice to provide as much information as possible when seeking help on the Community Forum, which operates similarly to the Microsoft Community and Reddit forums. This includes being clear in your request, supplying a work-in-progress Power BI Desktop file, using Excel Tables for data files, and properly formatting any code used in your description.
My suggestion was slightly different:
= Table.Distinct(Source, {“VBELN”, “PO”})
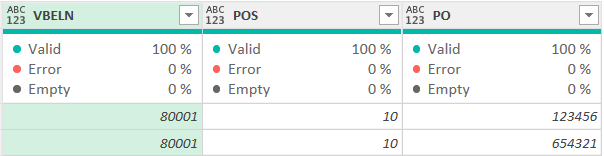
I understood “which POS attribution is not important”, so I thought that it covers the task.
As always, without understanding the task it’s difficult to provide a solution …
1 Like
Hello @Matthias
sorry for not being clear.
The result should be this:
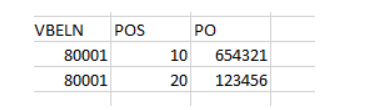
it does not matter which PO goes with which Position, as long as the PO is unique by VBELN
So I need to have 1 distinct position by VBELN (in my case 10 and 20) - and there should be a different PO assigned to each couple VBELN/Position.
My comment was about the fact that I don’t care which PO goes to which position - in the screenshot, it could be that PO 654321 goes to position 20 instead of 10, that’s OK, as long as PO 123456 is then in position 10.
The difficulty is that, when you remove duplicates on VBELN/Position, one single PO is retained, when I need to have 1 PO by VBELN/POS.
I am attaching a PowerBI with the solution on grouping I could find in the meantime - but again, I am very open to see if there are better solutions than mine!!!
Thanks
Kind regards
Valeria
EDNA duplicates ex…pbix (13.1 KB)
Hello @ystroman
thanks for your comments!
now I do have a PowerBI in progress and my shot at the solution - I have attached it to the reply to Matthias, but in the beginning, as I did not know how to solve it, it really was just the raw (mock) data so it was more difficult to explain…
Anyway I hope it’s clear now, and I do have a solution - I am interested to see if there are different ones as I have been really struggling with this, but if not, I will mark the thread as solved soon.
Thanks
Kind regards
Valeria
@Matthias definitely my choice of columns title is very poor!!! “POS” and “PO” !!! It is what it is in real life but I should have made it clearer for the example 
Valeria, how is a third PO 471123 covered?
@Matthias good question! because of the data structure, there will only be as many PO for a given VBELN as the count of POS.
So, if there was a third PO 471123, there would be an additional POS 30 and every PO would be repeated for each POS.
the structure comes from the data join (another query) - only a generic join on VBELN can be done between the PO and VBELN table… the PO table does not have POS.
Hope it’s clear otherwise please let me know!
thanks
kind regards
Valeria