Level of Difficulty:

Objective: This workout provides practice in creating functions that incorporate string manipulation, statistics, and data cleaning.
1. Given the following string, input_string, write a Python function that takes a string and removes all stop words (e.g. “the”, “a”, “an”) from it.
input_string = "The quick brown fox jumps over the lazy dog"
2. Given the following string, input_string, write a Python function that takes a string and performs stemming on it to reduce all words to their base form (e.g. “running” to “run”).
input_string = "I am running on the beach and feeling amazing"
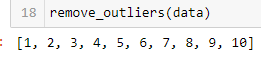
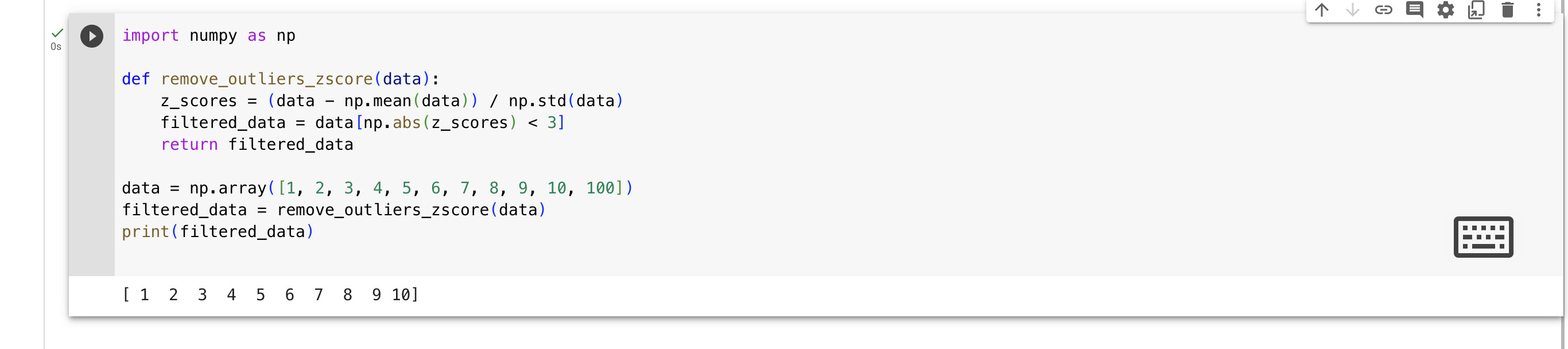
3.Given the following numpy array, data, write a Python program to remove outliers using the Z-score method.
data = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 100])
Simply post your code and a screenshot of your results.
Please format your Python code and blur it or place it in a hidden section.
This workout will be released on Monday May 8, 2023, and the author’s solution will be posted on Sunday May 14, 2023.