My actual scenario is very complex and involves data that I cannot share, so I will try to boil this down to a simplified presentation of the issue that is at the heart of it all…
I have a measure that is normalizing a series of values using a 0-10 scale. In the attached PBIX file, the measure look something like this:
Normalized Value from Table Column using ALLSELECTED =
VAR MinValue = CALCULATE(MIN('Random Numbers'[Value]), ALLSELECTED('Random Numbers'))
VAR MaxValue = CALCULATE(MAX('Random Numbers'[Value]), ALLSELECTED('Random Numbers'))
VAR CurrentValue = MAX('Random Numbers'[Value])
VAR NormalizedValue = DIVIDE(CurrentValue - MinValue, MaxValue - MinValue, 0)
RETURN
NormalizedValue * 10
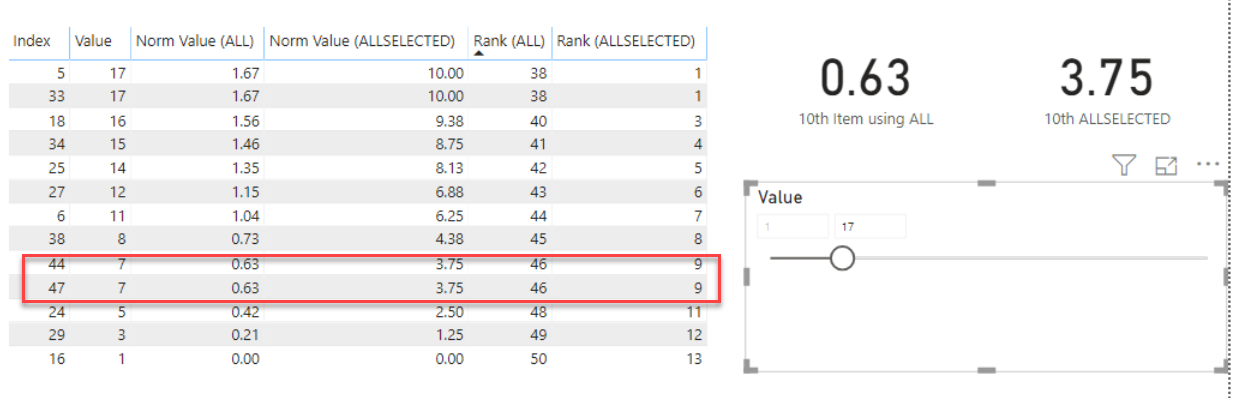
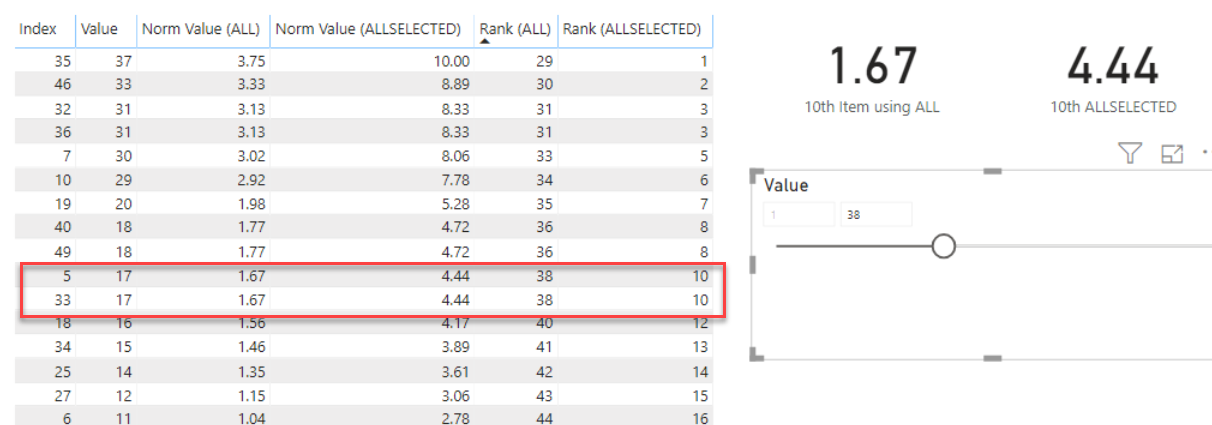
The measure works as designed in that anytime the selected rows change, the normalized values are recalculated based on only those rows that are selected.
Where I’m running into problems is with another measure that is supposed to show me the value of calculated by the measure above for 10th row of the selected rows when sorted in descending order by the normalized values (or “0” if there are less than 10 rows selected).
10th Item using ALLSELECTED =
VAR Top10 = TOPN(10, ALLSELECTED('Random Numbers'), [Normalized Value from Table Column using ALLSELECTED], DESC)
RETURN
IF(COUNTROWS(Top10) < 10, 0, MINX(Top10, [Normalized Value from Table Column using ALLSELECTED]))
The value returned by this measure is always “0”. If I’m understanding the situation correctly, this is because the context for ALLSELECTED() is the single table row that is being evaluated by the MINX() formula as it iterates through the rows of the table being passed to it. My problem is that I need that 10th value, and I don’t know how else to go about getting it. I tried changing ALLSELECTED() to ALL() in the first measure above (the one that normalizes the series), but then the value returned by the second measure (the one returning the value of the 10th row) always returns the same value regardless of which rows are selected because it’s calculating its result based on the context of the entire table.
Any ideas on how to fix this would be greatly appreciated. I have attached a sample PBIX file that shows the difference between using ALL() and ALLSELECTED(). If it’s not self-explanatory enough, let me know, and I’ll try to provide additional explanation.
Thanks in advance!
Test Case 3.pbix (43.0 KB)
 Kudos to Sam and folks like yourself on the forum. Enterprise DNA has been my primary learning resource on my PowerBI journey.
Kudos to Sam and folks like yourself on the forum. Enterprise DNA has been my primary learning resource on my PowerBI journey.