Unlike @Sue and @BrianJ, I don’t have a rubber duck or, tortoise to help me out in the thought process. However, I got a rubber orange that keeps me motivated.
Started by keeping only the data needed for building the requested table
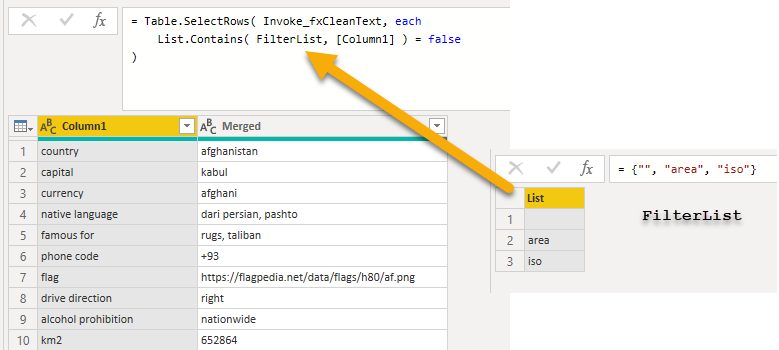
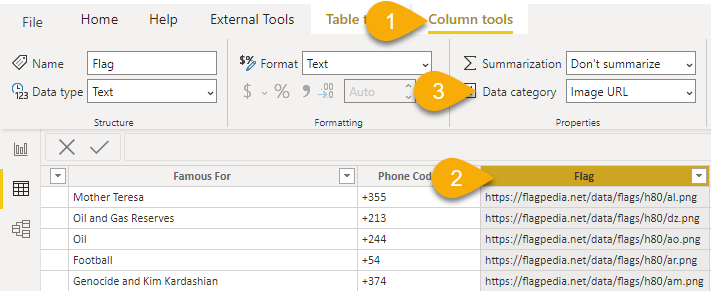
I cleansed the data https:// By looking at the site structure I realized that only the last characters change. used this finding to reconstruct the site address and clean undesired characters from the other rows in the same time
Did the cleansing needed for columns 1: Trim, Capitalize word, replaced undesired characters, renamed alpha_2
And here is my entry for this challenge - I’m going to have to check out everyone else’s comments to see how it compares, but I was able to use a couple of small tricks. Most of it was completed using the buttons in the UI, but there were a couple of small tricks I added.
One of my favorite tricks is this part:
Summary
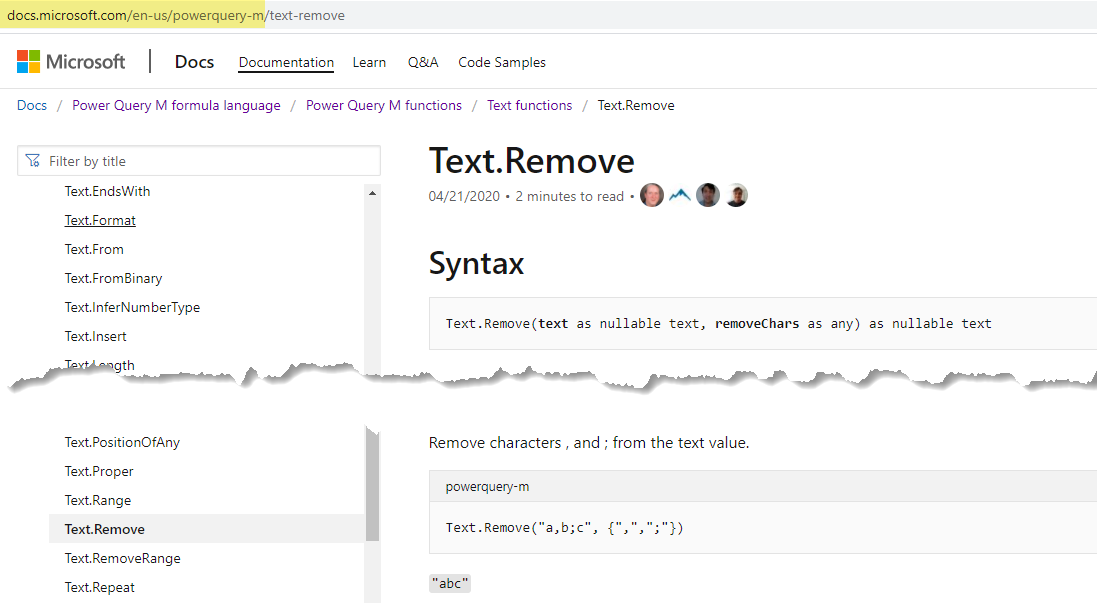
To remove the extra characters in the value field, I created a step that was added to my code in the advanced editor, just after the let statement: CharsToRemove = List.Transform({34, 91, 93}, each Character.FromNumber(_)),
And a few steps later, I used this to remove the characters of " [ ] from the text #“Cleaned Text” = Table.TransformColumns(#“Add Merged”,{{“Column1”, Text.Clean, type text}, {“Column2”, Text.Clean, type text}, {“Column3”, Text.Clean, type text}}),
here is where you can go to get the DEC codes to use for this type of trick: https://ascii.cl/htmlcodes.htm
Honestly it’s a real pleasure analyzing all submissions. Seeing the different mixes of UI and M code, being applied - just inspiring. It illustrates how many possibilities PQ offers to generate the same result.
Here is my solution for POTW Challenge # 2. Thank you @Melissa for coming up with such a great challenge. Now looking forward to your solution .
I just used the user interface for the solution.
Wow this has been amazing and so much fun! Thank you eDNA community!
You guys are turning this new initiative into a huge success.
In the YouTube Solution video I discussed the general approach I have taken in solving this problem. All specific details on my submission you can find in this post.
I hope you enjoy reading . Get ready… here I go.
What to do when you get stuck?
Start “Rubberducking” - verbally articulating your general strategy before diving into coding.
Search within the Documentation. M is a functional language and the MS Docs can be a big help in finding functions, examining their syntax and review examples by copy and pasting them into a new blank Query.
I’ve got it bookmarked and second to the Forum it’s the site I visit most.
However if you rather have direct access via your External Tools menu, see the post below.
.
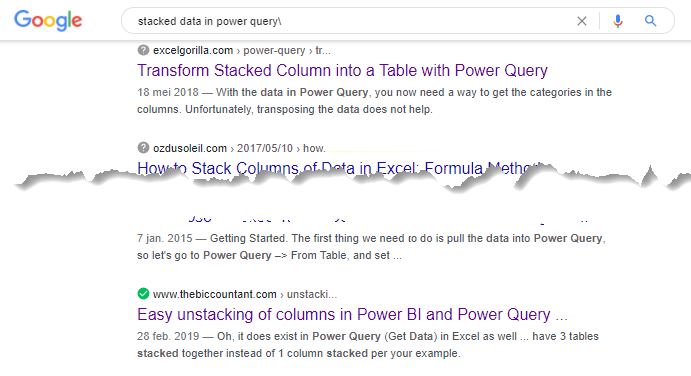
Personally I’ve learned a lot by just Googling… one of the major parts in this challenge revolved around Pivoting Stacked data. Now there are a couple of ways to do this of course but what if you’ve never seen this ‘pattern’ before? Knowing (or guessing ) that this format is known as Stacked can help you with some research.
.
See how many hits you get when you ask Google for anything on: “stacked data in power query”
On to my solution.
I tent to design my queries using UI as much as I can and when the query kind of does what it needs to do then I’ll go into the Advanced Editor examine the code and see if I can modify/change it.
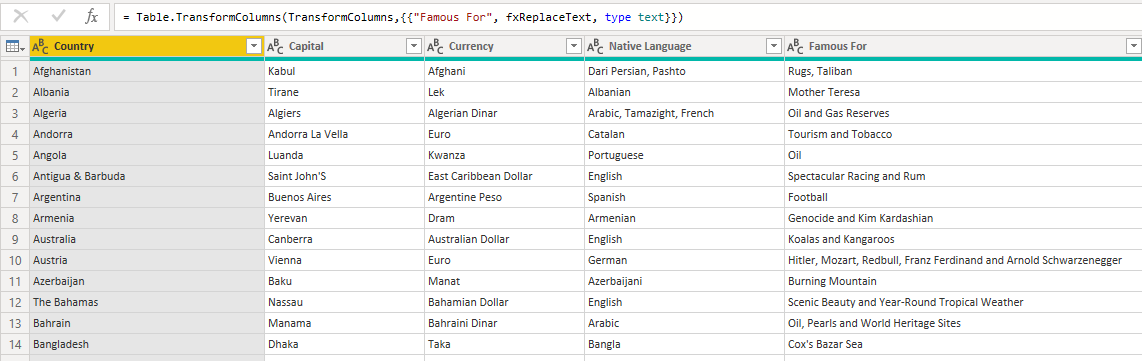
In my view, this data offered a lot of opportunities to experiment with some actual M coding. You can find all of my notes on that in the Countries (full UI) with Comments query.
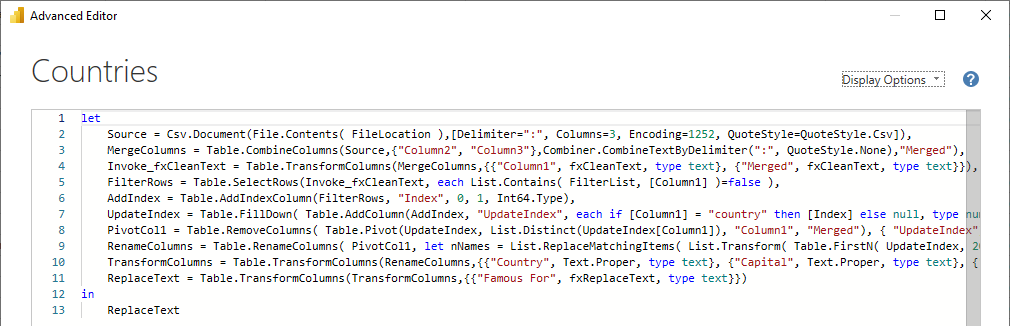
Starting from line 4 where I invoked a custom Text Cleaning function (for anyone interested in that a YouTube video will become available some time next week). This is the M code for the fxCleanText function.
(myText as text) as text =>
let
ToRemove = {""""} & Text.ToList(":[]}"),
CleanText = Text.Remove(myText, ToRemove),
TrimText = Text.TrimEnd(Text.Trim(CleanText), ","),
FixLink = Text.Replace(TrimText, "//", "://"),
ReplaceValue = Text.Replace(FixLink, "_", " ")
in
ReplaceValue
.
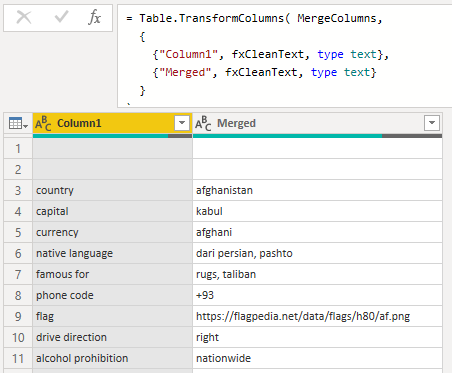
Which can then be Invoked to Transform both columns in a single step.
.
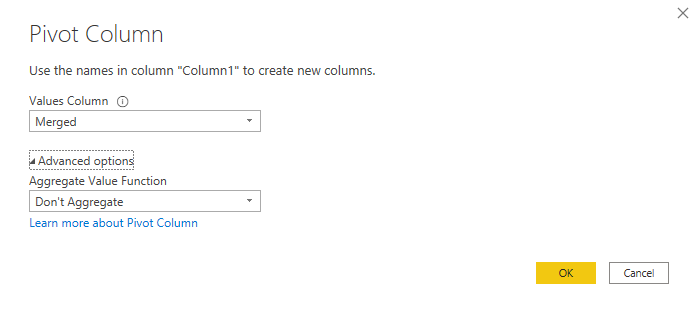
Creating segments to Pivot the data (aka identifying each separate block of stacked data)
Nested 2 functions here and only returned the 3 Columns mentioned in the square brackets.
If you have any questions in regards to my solution please reach out and @mention me.
.
Things I noticed or want to call out after reviewing your submissions.
For both @chrish and @logicalbi participating here was their first Forum contribution
On the number of query steps… @BrianJ required the most 45 in total, @Rajesh 's second entry the least with just 15 steps (note I’m incl. let and in clause) followed by @chrish with 17 and @alexbadiu with 19 steps.
I thought the change @chrish made to the Source step was pretty slick.
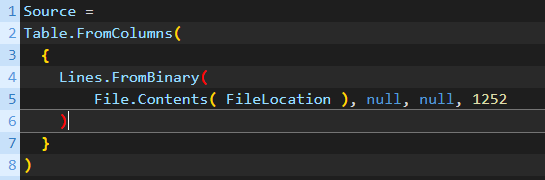
Both Hossein Satour and @amira.bedhiafi.pro also used a combination with Lines.FromBinary in the Source step - Can you guys comment on how/why you decided to do that?
Thanks!
Several methods were used for segmenting and setting up the Pivot step:
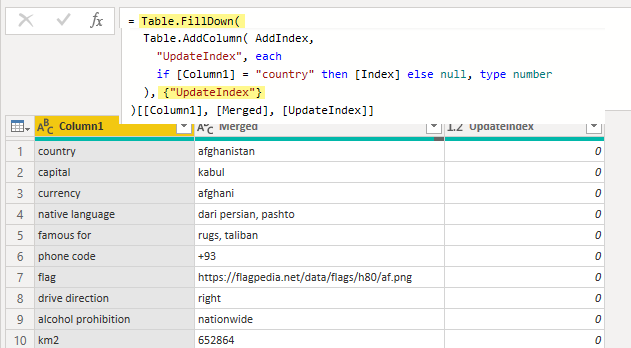
if-then-else constructs like: if [Column1] = “Country” then [Index] else null
Divisions like: Number.IntegerDivide([Index], 22) or [Index]/10 or each _ / 22
Modulo like: Number.Mod([Index], 20)
Not everyone chose to do a Pivot to get to the tabular format other methods used:
Nested table Transpose by @MK3010 and Hossein Satour
and last but not least @MK3010 did an excellent write up so I recommend reviewing that, if you haven’t already.
.
If you have more to share on your own entry I would enjoy reading AND appreciate that
As you know to encourage participation, we do a random drawing of five participants who will receive a cool Enterprise DNA vinyl laptop sticker. This round’s winners, in alphabetical order, are:
That about sums it up for me… If you went exploring too and feel I missed any of the hidden gems, please feel free to leave your thoughts in a post below. Thanks!
Thanks -terrific job leading this week’s problem, including an excellent writeup and solution video.
With regard to this section of your analysis:
My rubberducking session for this problem went something like this:
Add index
Add modulo
Pivot with no aggregation on modulo
Fill up
Filter non-Country rows
Make an inefficient mess of the cleanup process
So, mission accomplished!
As soon as I started reviewing the other solutions coming in, I realized that creating the tabular form BEFORE doing the cleanup was not a wise decision on my part. Beyond that, learned a lot of innovative techniques for text cleaning from the solution submitted.
Huge thanks to all who participated. We hope you are finding these problems both educational and entertaining, and we absolutely welcome your feedback.
Because December has five Wednesdays in it this year, no new POTW next week, but we will be back on the first Wednesday of January (1/6) with a new DAX problem, led by Enterprise DNA expert @greg who has cooked up another good one for you.
Brian
P.S. if you were selected in this round of the drawing for the laptop stickers, please email me your mailing address at brian.julius@enterprisedna.co, and I will get your sticker mailed off to you right away.
Thanks for sharing your thoughts and problem break down
But I don’t think that’s the actual issue…
In my view grouping similar transformations as much as you can, in general will reduce the number of query steps. Looking at your solution for example there’s a lot of duplication in steps:
9x Replace Value (through just the UI this is the only one that can’t be reduced to a single step)
8x Rename Columns
5x Capitalize Each Word
4x Change Type
2x Remove Columns
Removing this type of duplication will have a significant effect. Try it.
I’d love to hear the result…
In the first YouTube Solution video I discussed the general approach I have taken in solving this problem. All specific details on my submission and a link to that first video - you can find in my earlier post.
The second video related to this challenge was released today, here’s a link to that. It covers the Custom Text Cleaning function with more detail. I hope you enjoy it.
I wanted to try my hand at this nice problem too.
I have tried, as much as possible, to use the UI. for this reason the steps of the solution are more than strictly necessary.
the idea is developed according to the following points:
cleaning of the text;
aggregation of some subfields (Area; Iso; …)
group the data relating to each variable into lists
use the first column of this table as a list of the names of the searched table and the second column as a list of the columns of the searched table.
Like what you have done here.
Demonstrates another creative solution to a problem like this. Thank you so much for participating!
Hope to see you in future challenges.










 You’ve sure been keeping busy. Entering Power BI Challenge 10- Supplier Insight and both POTW challenges this month. Just amazing. Thank you.
You’ve sure been keeping busy. Entering Power BI Challenge 10- Supplier Insight and both POTW challenges this month. Just amazing. Thank you.