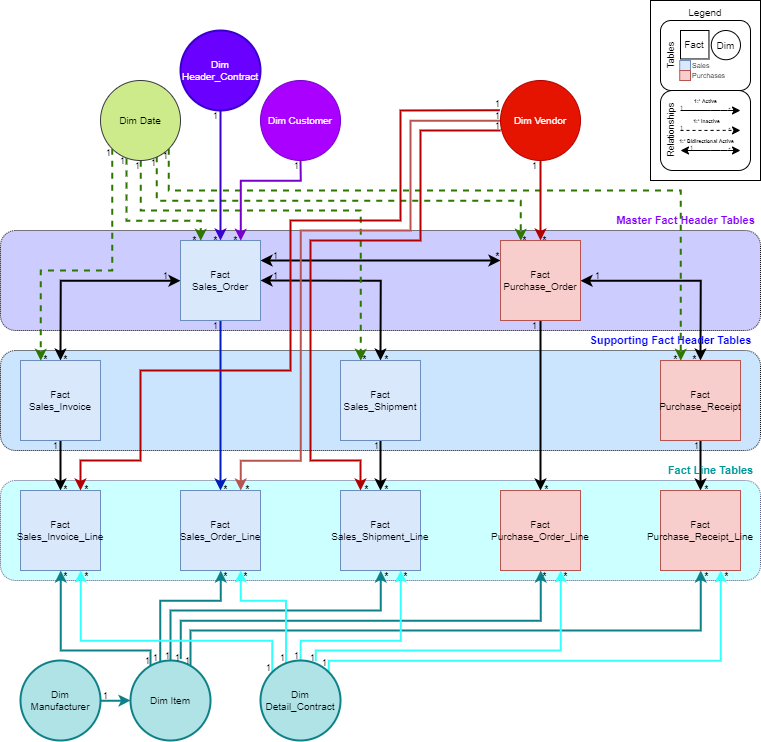
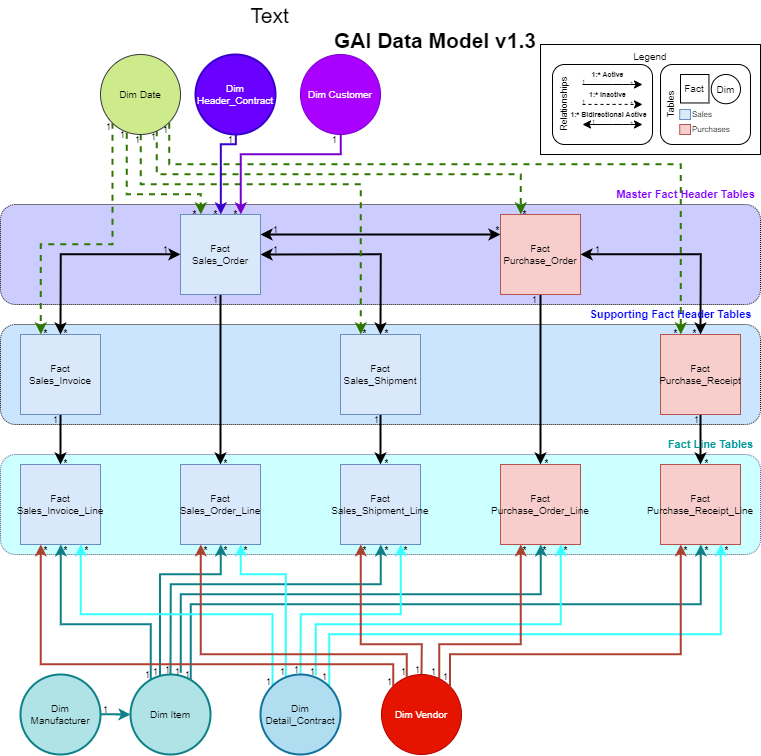
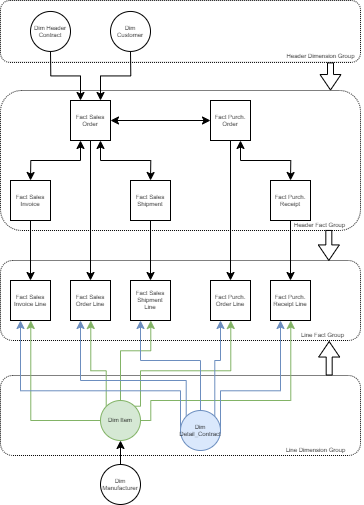
I’m wondering why there’s a Sales_Invoice and Sales_Invoice_Line as well as well as the same with Orders. Why the 2 tables?
In my original model, I had a single query for both Sales_Invoice and Sales_Invoice_Line, combined.
Similarly, I had a single query for both Sales_Order and Sales_Order Line, combined. Header values were repeated on every line.
I didn’t think it would be good to leave those header and line tables combined. The main thing driving me to refactor this data model was to create relationships between my various fact tables, specifically:
- Sales Orders [1:*] with Sales Invoices,
- Sales Orders [1:*] with Purchase Orders,
- Purchase Orders [1:*] with Purchase Receipts
- Sales Orders [1:*] with Sales Shipments.
If I leave these fact tables connected as they are (see original post’s data model diagram), I think I need lines and headers in separate tables to preserve the 1:* relationships between fact tables. Conversely, If I was to combine header and line tables, I wouldn’t be able to connect my fact tables to each other without creating : relationships.
Also, when it comes to simplifying, a Key_Measures table fixes a ton, that way you’re not recreating calculations within new measures and instead measure branching.
I basically do have a Key Measures table, but am having a great deal of difficulty determining how to create both Booked (Sales Order) and Invoiced (Sales Invoice) measures, which is the current issue I’m facing.
Some of my key measures, all of which are struggling to cope with my data model:
Ext. List =
CALCULATE(
SUMX('Fact Sales_Order_Line','Fact Sales_Order_Line'[Quantity] * 'Fact Sales_Order_Line'[Unit List]),
USERELATIONSHIP('Dim Dates'[Date], 'Fact Sales_Order'[Order Date])
)
Ext. Cost =
CALCULATE(
SUMX('Fact Sales_Order_Line','Fact Sales_Order_Line'[Quantity] * 'Fact Sales_Order_Line'[Unit Cost]),
USERELATIONSHIP('Dim Dates'[Date], 'Fact Sales_Order'[Order Date])
)
Ext. Price =
CALCULATE(
SUMX('Fact Sales_Order_Line','Fact Sales_Order_Line'[Quantity] * 'Fact Sales_Order_Line'[Unit Price]),
USERELATIONSHIP('Dim Dates'[Date], 'Fact Sales_Order'[Order Date])
)
Ext. Discount = [Ext. List] - [Ext. Price]
Gross Profit = [Ext. Price] - [Ext. Cost]
Inv. Ext. List =
CALCULATE(
SUMX('Fact Sales_Invoice_Line', 'Fact Sales_Invoice_Line'[Quantity] * 'Fact Sales_Invoice_Line'[Unit List]),
USERELATIONSHIP('Dim Dates'[Date], 'Fact Sales_Invoice'[Posting Date])
)
Inv. Ext. Cost =
CALCULATE(
SUMX('Fact Sales_Invoice_Line', 'Fact Sales_Invoice_Line'[Quantity] * 'Fact Sales_Invoice_Line'[Unit Cost]),
USERELATIONSHIP('Dim Dates'[Date], 'Fact Sales_Invoice'[Posting Date])
)
Inv. Ext. Price =
CALCULATE(
SUMX('Fact Sales_Invoice_Line', 'Fact Sales_Invoice_Line'[Quantity] * 'Fact Sales_Invoice_Line'[Unit Price]),
USERELATIONSHIP('Dim Dates'[Date], 'Fact Sales_Invoice'[Posting Date])
)
Inv. Ext. Discount = [Inv. Ext. List] - [Inv. Ext. Price]
Inv. Gross Profit = [Inv. Ext. Price] - [Inv. Ext. Cost]
Here’s some demo data specifically pertaining to this issue. PBI Demo Order Invoice Relationship (2).zip (148.5 KB)
I felt so confident two days ago, and now I’m reconsidering whether I’ve had an epiphany or just a rush of hubris. There’s some crucial rule I don’t know I’m violating in my data model, and some part of my approach is entirely wrong. I don’t know where to look.