Hi, You know when you go round and round and end up getting confused about the simplest things. That’s where i am at now
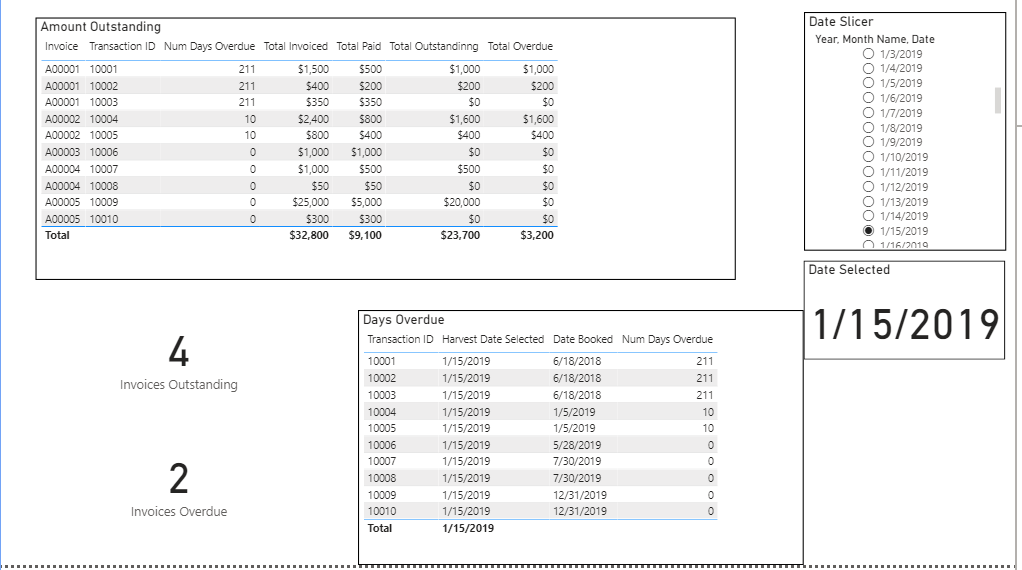
Attached is a basic PBIX file. I require to select a date and it show:
The number of invoices outstanding (i.e a) Invoice not fully paid, b) invoice not overdue
The number of invoices overdue (i.e a) Invoice not fully paid, b) invoice overdue
The value of invoices outstanding (i.e a) Invoice not fully paid, b) invoice not overdue
The value of invoices overdue (i.e a) Invoice not fully paid, b) invoice not overdue
An invoice can have multiple transactions and a transaction can have multiple payments on different dates.
I would like it to be dynamic such that when a date is selected it calculates the total amount already paid based on date. I have a disconnected table to assist with the overdue calc and think i am getting myself further confused with this too.
Hope this makes more sense to you than it is making to me right now
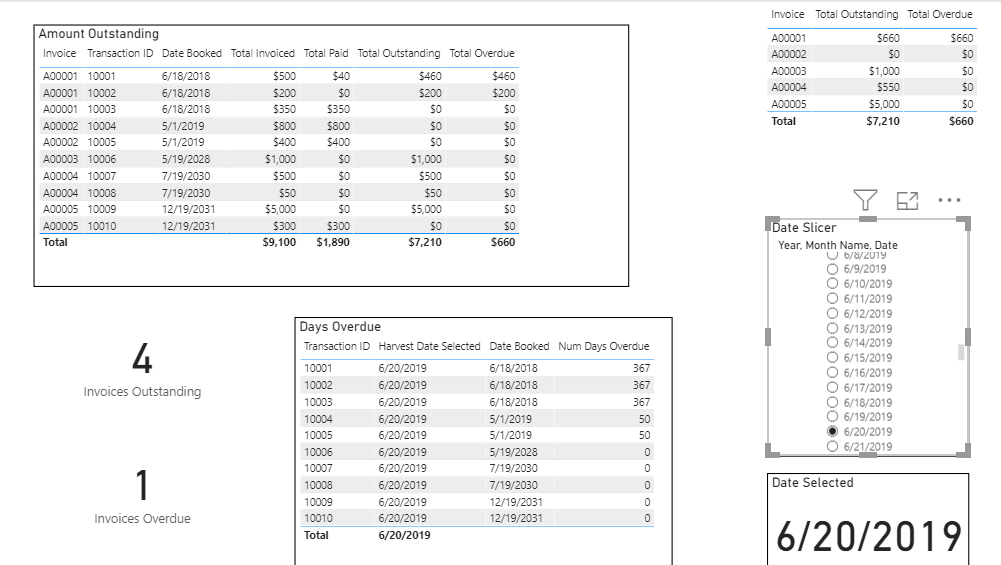
Your DAX was on the right track - the reason you were getting wrapped around the axle was that your data model was flawed, thereby making your DAX go sideways. Whenever you’ve got relationships between your fact tables, that’s a sign you’ve got problems with your data model. In addition, you have multiple dates that you need to handle via inactive relationships. There are multiple way to revise the data model to address these problems - I chose to merge your two fact tables into one master transactions table, although there are certainly valid structures that maintain multiple fact tables. I also linked the date table to the transactions table via inactive relationships on date booked and date paid. These then get turned on in the appropriate calculations using the USERELATIONSHIP function.
I then rewrote the DAX measures based on this new model. Here’s what it looks like all put together:
P.S. If you’re interested, the following is an outstanding article laying out the performance, memory, and data size trade-offs inherent in the single versus multiple fact table decision:
As always massive thanks for your response - Above and beyond
I have been questioning my model setup (which is a lot more complicated than the sample i have uploaded). I played around with merge when creating the model initially, but using your example, the total invoiced is duplicated so whereas trans ID should have value $500 it has a total of $1500.
I will read through the documentation you kindly provided (thanks again). Would it be best if i marked this as solved or would it be better for me to review the attached documentation and come back with anything new? Happy to do whichever you advise…
Is there a way of direct messaging you my linked in details? Would be great to have you as a contact on there.
You’re absolutely right about the need to be careful about duplication issues when you denormalize tables, like I did with your fact table. So for example, when counting invoices outstanding and invoices overdue, I used DISTINCTCOUNTNOBLANK() instead of COUNTA() to account for the duplication in Invoice numbers when merging with the transactions table. Unfortunately, I let one slip past in the solution I sent you and the Total Invoiced measure does not properly account for the duplication.
My apologies - will fix that measure shortly and send you back a revised solution.
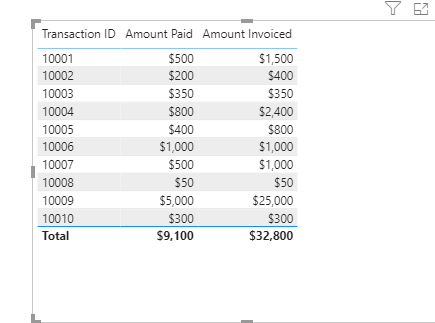
It was more the fields in the table that were confusing me than the measures. If i now create a basic table and bring in amount paid and amount invoiced, the amount invoiced is triplicated.
Per below table for ID 10001 Both the amount paid and amount invoiced should be £500 but instead the amount invoiced is triplicated to show £1500. Is this as you would expect? Cheers
Yes, that’s what I’d expect from a transaction table containing both invoices and transactions. Because transactions are a higher level of granularity than invoices, you’ll see duplication at the invoice level. Simple aggregate measures on the field with the highest granularity (transactions) will be fine, but aggregations on the fields with lower granularity will need to take account of the duplication. Does that make sense?
Just checking through my revised solution - will send off shortly, which will provide some useful specifics to the discussion above.
Re: your question about closing out a thread. If a solution meets your original requirements, mark it as solved. It’s fine to continue to ask followup questions to understand the solution provided, but if you’re asking a new question beyond the original requirements, we ask that you start a new topic (but always helpful to refer/link back to the original thread as background info).
re: LinkedIn - thanks for the invite, but I never got on that train and it just seems too daunting to start now.
Revised solution provided below. Just give a shout if any of it is unclear.
BTW - great job on the initial post - clear statement of the requirements, the problem and PBIX file attached. All of that makes it much easier to provide good support.
Thanks Brian - Will go through tonight and come back tomorrow morn if that’s ok. Re linked in understood (made me laugh as i was the same until a few years ago- I do find its a good way to try and keep up to date with anything new that’s out there once you get past the initial pretence of it all)
Hi @Hitman, did the response provided by @BrianJ help you solve your query? If not, how far did you get, and what kind of help you need further? If yes, kindly mark the thread as solved. Thanks!
Hope you’re getting over your battle with tonsillitis.
In terms of the @ - that’s the naming convention recommended by the SQLbi guys to identify columns in virtual tables, avoiding the usual ambiguity as to whether [Overdue] is a measure or a column in a virtual table. For more explanation, see the attached article below. If you work with virtual table variables, I highly recommend adopting this convention.
Your second question about whether merging the tables is “best” is much tougher to answer. There are clearly some objectively wrong ways to construct a data model, but the “right” or “best” way often depends on the analyses you want to do and the questions you want to answer. A structure that works well for one set of questions/analyses may not work as well for a different set. When I start data modeling for any project, I always first think of the analyses I want to produce and then work backwards to the structure that best supports those analyses, even to the point of storyboarding my reports before I engage in any data modeling. That way, as I’m modeling I can think of the measures I’ll need to generate and then evaluate my data model alternatives in terms of how easy or difficult it will be to calculate those measures. That’s probably an unsatisfying answer, but I think there is a lot of art to data modeling that doesn’t lend itself to hard and fast rules.
Generally the rules to stick to are:
strive to conform to a star schema
avoid bidirectional relationships
build your fact table(s) long and narrow (lots of rows, relatively small number of columns)
Beyond that it really is what works best for your individual project requirements.
Whilst we are paying homage to the Godfathers of Dax, i read the below article the other day and it was nice to hear one of the gurus expressing the difficulties in learning Dax. Now days there are so many sources which promote zero to hero solutions and realistically even with the best resources it is a journey which will take years to master.
I agree @BrianJ. Storyboarding or wireframes or sketches of the end goal (along with hopefully the questions that you want answered, or insights you want to display) should lead you to the model that best answers those. Always strive to use the simplest data model you can, and if any forks-in-the-road appear, take the simplest route.
One time this might not be the case is when you are preparing a data model for use by others (users and/or reports) [e.g., a shared dataset]. Then the data model should use the most standard approach and rules possible, as @Brian described.