Hey,
I’m pulling together a bunch of medical data for our patients who have surgery at our hospital.
The data is being pulled from a bunch of different machines, spreadsheets, workbooks, etc and these measurements happen on different days during the rehabilitation period.
I’m trying to figure out the best way to parse and model the data.
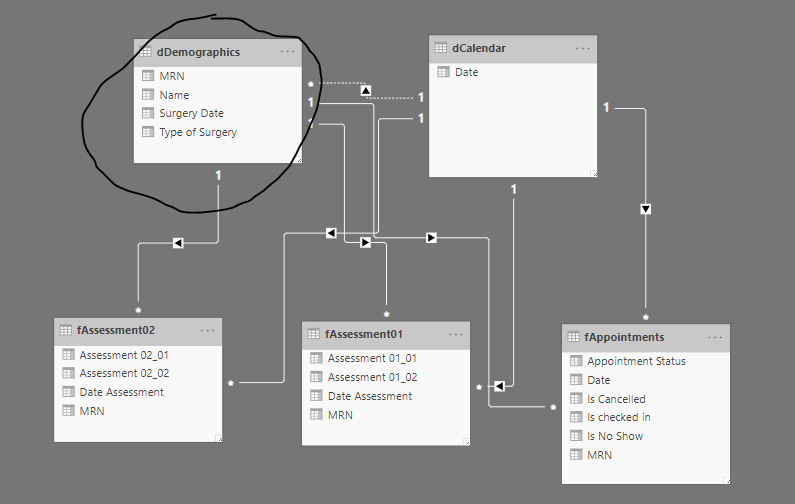
I have a single table identifying the surgery date for each individual, along with other demographic information (fDemographics in the image below).
Most of my analyses will have “Days since surgery” on the x-axis - i.e. the difference between the particular assessment date for that individual, and the date of that individual’s surgery.
As I see it I could do a LOOKUPVALUE for every individual assessment type table for the surgery date, and then for every assessment have a “Days since surgery” column.
This approach works, but strikes me as inelegant, and prone to error as the end users will have to remember to choose the ‘correct’ ‘Days since surgery’ value for the x-axis for every visualisation.
The other thought I had was an equally inelegant merging of all the different assessment tables so there’s simply the one data table for every assessment value, and then one patient dimension table (each patient is uniquely identified by a Medical Record Number)
I’ve tried to visualise the problem here:
!
I’d appreciate any thoughts, especially if I’ve missed something very obvious here (which is likely)
@rodwhiteley
Would there be any chance to get some dummy data you are working with?
Nick

Edit: Removed - see reply below
I’ve made up some dummy data in more or less the format of my data, albeit much less complex. Note the names, medical record numbers, dates of assessment, dates of appointments, and assessment values are all randomly generated, so no doubt there will be some nonsense in here
DummyMedicalData.xlsx (57.2 KB)
Edit: I’ve added 2 columns in the source “Assessment” tables so I can do some checking for any formulae I make in PBI - lookup colums for the individual’s surgery date, and the days difference between that given assessment and that individual’s surgery date*****
Edit: Here’s a .pbix with the data imported so you can see the model
DummyMedicalData.pbix (121.1 KB)
I am now playing with this data set to see if I can figure out, in modelling, how to create the “Days since surgery” the best way. As a Reminder, this will be the number of days from the “Surgery Date” in the dDemographics table for the given MRN for the associated MRN in either of the fAssessment tables.
Obviously this could be a VLOOKUP there in Excel, but then there’s one of these columns for every one of the source tables. I’m thinking there’s got to be a way to link this to a calendar table, and then figure out the date difference between the date in the Demographics table for that individual, and the date of the assessment in question which would then be correct across all tables.
Any help greatly appreciated.
*****“Why don’t you just do this for all tables in your model?” - Because then I will have a “Days since surgery” variable for every table of assessments - there are about 20 of these in the real model. This will confuse the end users when they are making visuals
Ok this is an interesting scenario.
I would solve it like this.
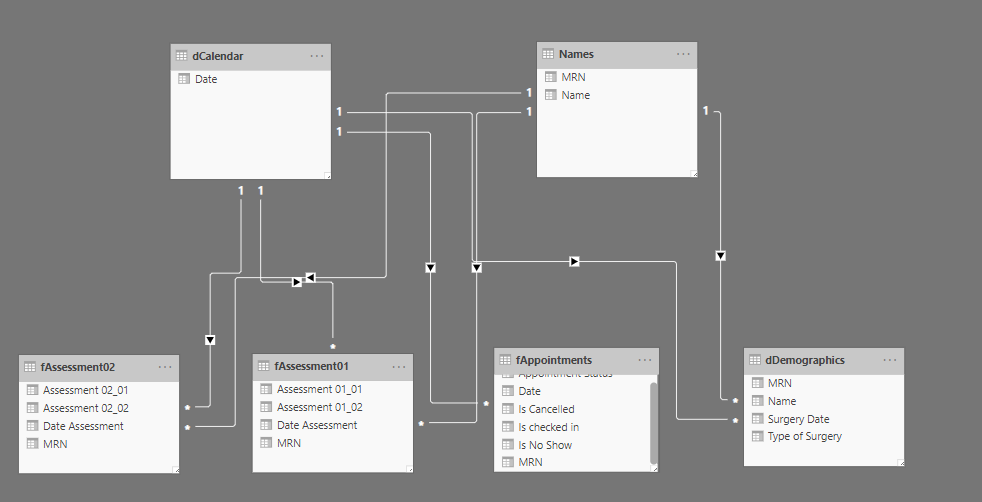
I would turn this table here into a fact table.
Then create another table with just the MRNs and name and have that as your Lookup table.
Something like the below
Also can you append these two table somehow? This would also be more efficient
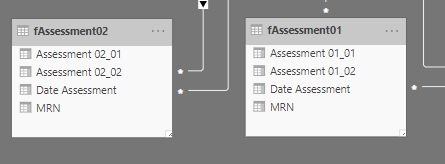
You might just add a column suggesting Assessment1/Assessment2 but to me it looks like the data structure is similar so you want to get these into the one table.
Days since last surgery should be too difficult now if you want to look at this by MRN and name.
You have the date table and MRN/Name table all linked up correctly. So if you filter from your lookup tables everything should filter well from here.
Give this a go. I think your DAX formulas should be much simpler now with a solid setup.
Sam