I would like some help in improving my query. In the attached PBIX I created a query where two tables are cross joined, a distance calculation is being performed on the resulting table and rows are being filtered for a specific distance threshold.
The query works fine technically, but lacks proper performance, even when using Table.Buffer.
Both input tables consist of 7.000 rows and 13.000 rows respectively. This results in a cross joined table of 7.000 x 13.000 = 91 million rows of which after filtering for the threshold only 150.000 remain.
Therefore I would like to integrate the distance threshold as a condition in the actual merge operation, which should result in less rows being generated in the merged table.
Can someone help me with adjusting the query in this way?
There is no need to integrate the exact distance calculation in the merge condition. A more simple condition like: “not cross joining rows where both Lattitude and Longitude differ more than 0.1” would be sufficient.
Thanks for responding.
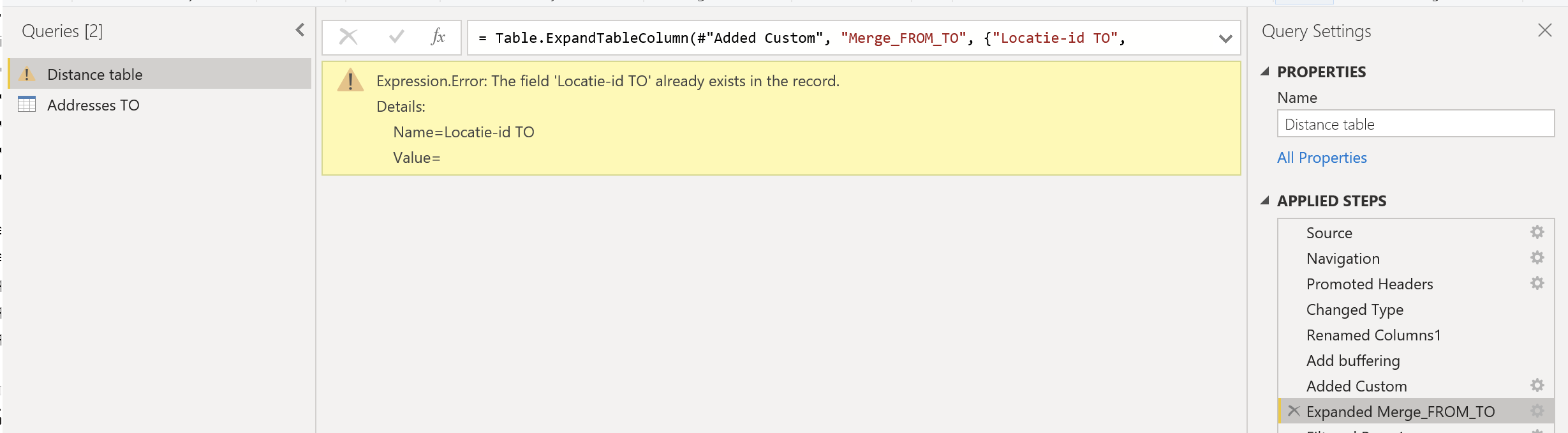
I see that the step “Table.AddColumn” does not reference to the previous “Add buffer” step. But I am a bit confused by your suggestion in the red rectangle. Do you mean correct it like:
#"Added Custom" = Table.AddColumn(#"Add buffering", "Merge_FROM_TO", each #"Addresses TO")
or
#"Added Custom" = Table.AddColumn(#"Renamed Columns1", "Merge_FROM_TO", each #"Add buffering")
Considering the merge on a rounded Lattitude might work. But I still don’t get exactly how you would do that. Somehow the engine has to generated every possible combination, then evaluate whether the rounded attitude and the rounded longitude differ both less than 0.1 and either drop the combination row or keep it in the merged table.
If you can show me how to create such an evaluating condition within the actual merging operation, that would be great. In that case I can use that approach also for other similar situations.
#“Added Custom” = Table.AddColumn(#“Add buffering”, “Merge_FROM_TO”, each #“Addresses TO”)
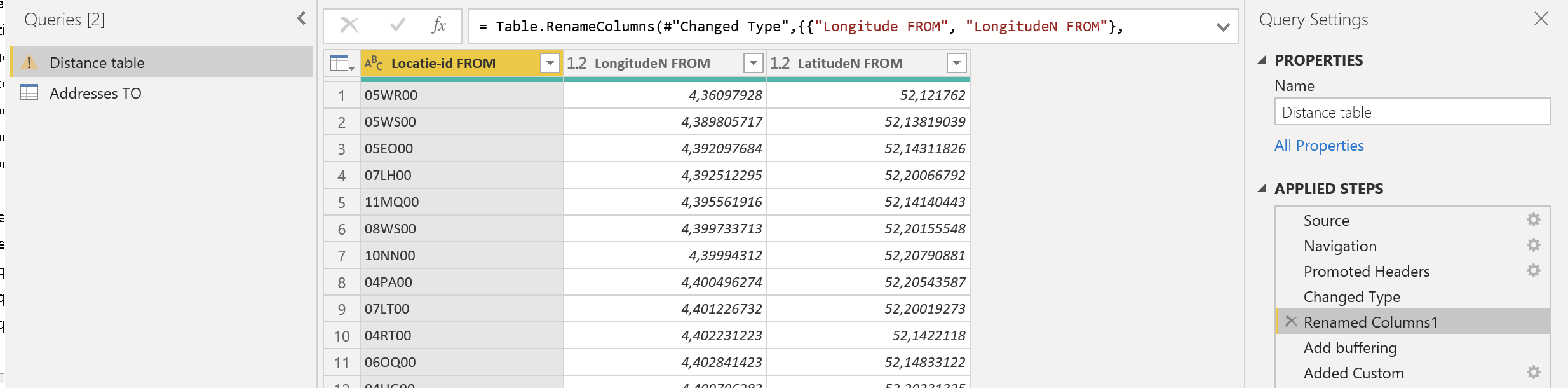
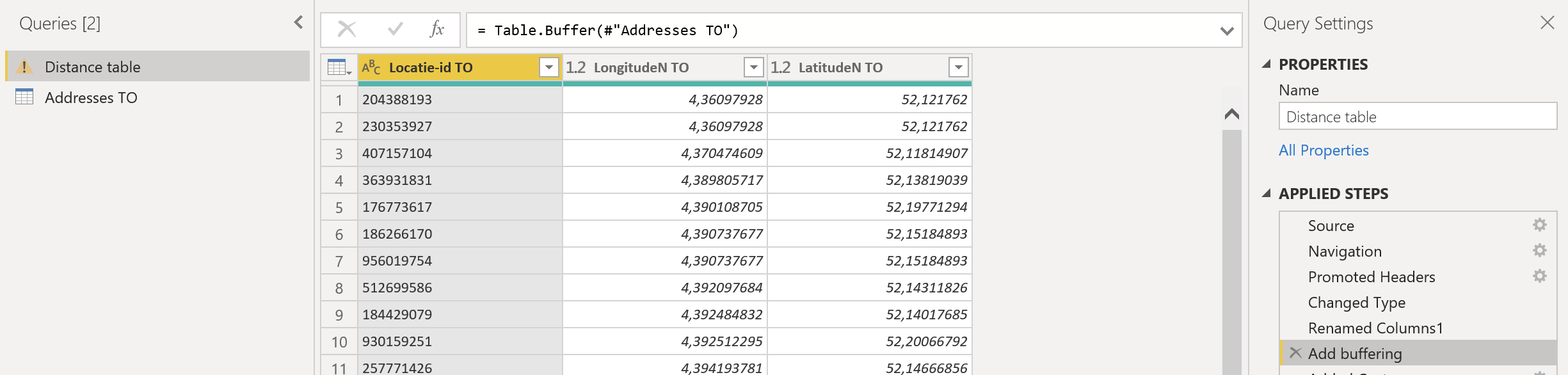
That doesn’t work and generates and error upon expanding the merged columns. Is the buffering operation correctly used in my query? I see directly after the buffering action, that the query actually changes the column-names. See images:
No as I depicted it. The first parameter in the M function Table.AddColumn is be base table you want to add that column to - so that needs to be the #“Renamed Columns1” step…
I will check it thoroughly. The change in returning rows feels strange. Perhaps the rounding off is a bit too rigid. I’ll check it out and come back to you.
Hi Melissa, great that you participate in this one, Bas has posted about his model a few times, @BrianJ did work already and I suggested to overcome the issue of the enormous amount of resulting rows in a DAX measure. As you know I prefer PQ, but in this case it might actually be better to calculate in a measure in the context of the filtering thus avoiding long processing in PQ. I have no idea what effect this will have on speed but it is worth a try I guess.
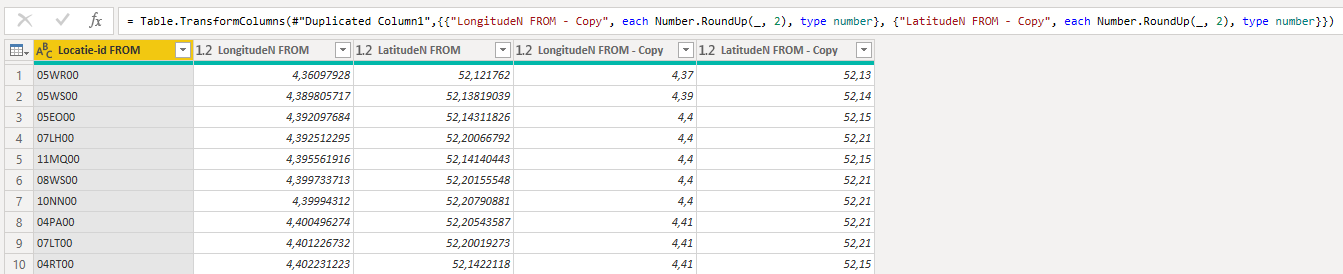
The lat lon values need to show more decimals, for accuracy.
Paul
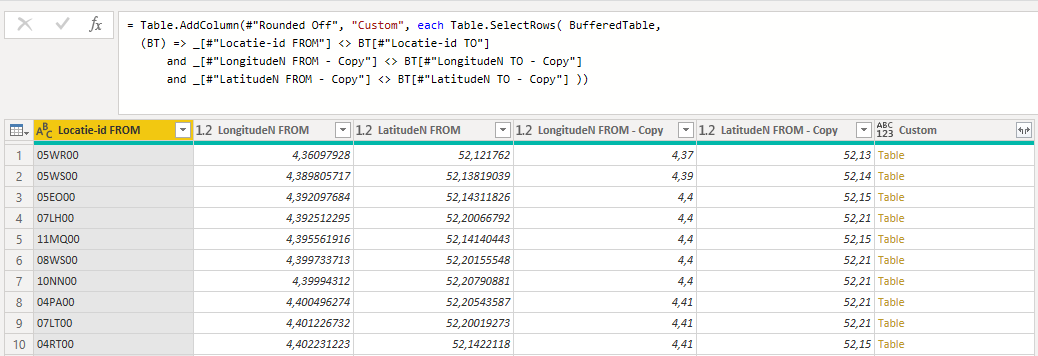
I think I figured it out.It has something to do with the way we round the numbers and how we set the conditions in the Table.SelectRows when merging both tables.
In order to adjust this properly I have to understand a little bit better how you defined this Table.SelectRows operation. A few questions:
What stands “(BT)” for?
What is the meaning of “=>” and the use of underscores in: _[#“Locatie-id FROM”]
Can we only use comparisons like: _[#“LongitudeN FROM - Copy”] <> BT[#“LongitudeN TO - Copy”] or alo something like: _[#“LongitudeN FROM - Copy”] - BT[#“LongitudeN TO - Copy”] > 0.01 ??
Can conditions be grouped like: (A <> B and C <>D) or (E=F and G=H)?
That’s just a variable name I made up to reference the BufferedTable, so BT for short.
()=> is used to create a function in M
“_” is a nameless variable, that can be used to access the current record
No Table.SelectRows takes a table as first parameter and a condition as function as the second parameter which can be anything that defines your true / false logic
.
I hope this is helpful, let me know if you need further assistance.
Hi @Sebastiaan, a response on this post has been tagged as “Solution”. If you have a follow question or concern related to this topic, please remove the Solution tag first by clicking the three dots beside Reply and then untick the check box. Thanks!
I figured out how to make it work. Just rounding up wasn’t sufficient to get a proper examination whether two latitudes or longitudes do not differ more dan 0.1. See the attachment for a more detailed analysis of the logic behind the conditional statement.
The final result in the query looks like this:
#"Added Custom" = Table.AddColumn(#"Rounded Off", "Custom", each Table.SelectRows( BufferedTable, (BT) => (_[#"LongitudeN FROM - Round"] = BT[#"LongitudeN TO - Round"] or _[#"LongitudeN FROM - Round"] = BT[#"LongitudeN TO - RoundUp"] or _[#"LongitudeN FROM - RoundUp"] = BT[#"LongitudeN TO - Round"]) and (_[#"LatitudeN FROM - Round"] = BT[#"LatitudeN TO - Round"] or _[#"LatitudeN FROM - Round"] = BT[#"LatitudeN TO - RoundUp"] or _[#"LatitudeN FROM - RoundUp"] = BT[#"LatitudeN TO - Round"] ) )),
Thanks for helping me out on this issue. A short recap what I learned from your responses:
Table.Buffer should not be seen as a consecutive step in a query, but as a sidestep that should be referenced to in a step furtheron in the query.
Table.SelectRows can be used when merging two tables to set a conditional stage for the merged records.
=> can be used to create a custom function; in this case to define a true/false logic for the Table.SelectRows operation.