I have a horrible data cleaning problem that I have finally resolved, but the refresh performance is horrible, and I think that part of the bottleneck might be able to be resolved with the use of both Table.Buffer and List.Buffer, but I need some hand-holding.
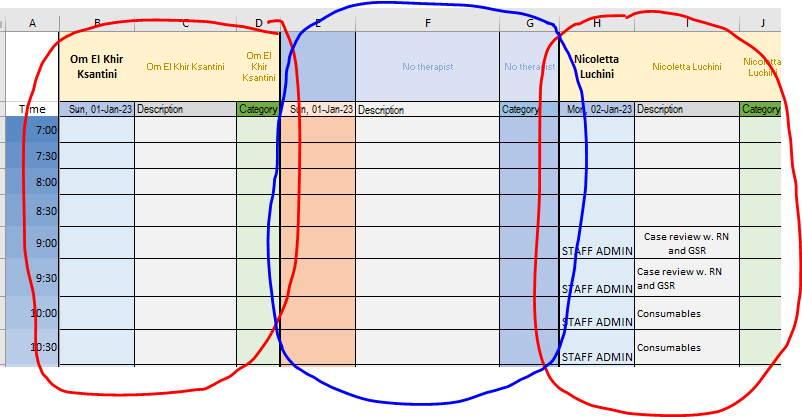
Some background: at our hospital for reasons you don’t care about, some staff contact is recorded in an Excel workbook where we record a week’s activity per sheet, with 3 columns per staff member, per day (the “real sheet” has 208 week - 4 years’ information):
IPLoadMASKED.pbix (332.6 KB)
IP_Load_2023_Dummy.xlsx (638.0 KB)
Because I have to pull out each of the individual columns, from each individual sheet, and then ascribe the values to the individual staff resource for that day, I have written 2 queries for each therapist for each day, (14 queries for the whole week) and then finally appended all these together to the main query (“fInPateints” in the .pbix). Each of these queries is also looping through each of the 208 sheets in the source Excel, and since it’s doing this from a OneDrive file, we have the extra network bottleneck.
Finally my question: I think that I should be able to improve performance by buffering the source table rather than fetching it each time, and similarly buffering the small lists that I use to parse the “full” query which is grabbing the first 43 columns from every sheet in the workbook that’s not hidden.
Obviously I’m going to need to explain more, unless someone is truly fluent in reading my poorly written M code, so I might leave it at that.
Final point: each of the queries in the attached pbix are pointing to the OneDrive file (which I can’t share), and the attached masked Excel file I have provided is of the same format, but I’ve cut it down to 4 sheets for the sake of simplicity.
As proof of concept though, if someone were able to implement Table.Buffer and List.Buffer in one of the queries, I think I could sort the remaining 13 out myself.
Thanks in advance for any help,
Rod
