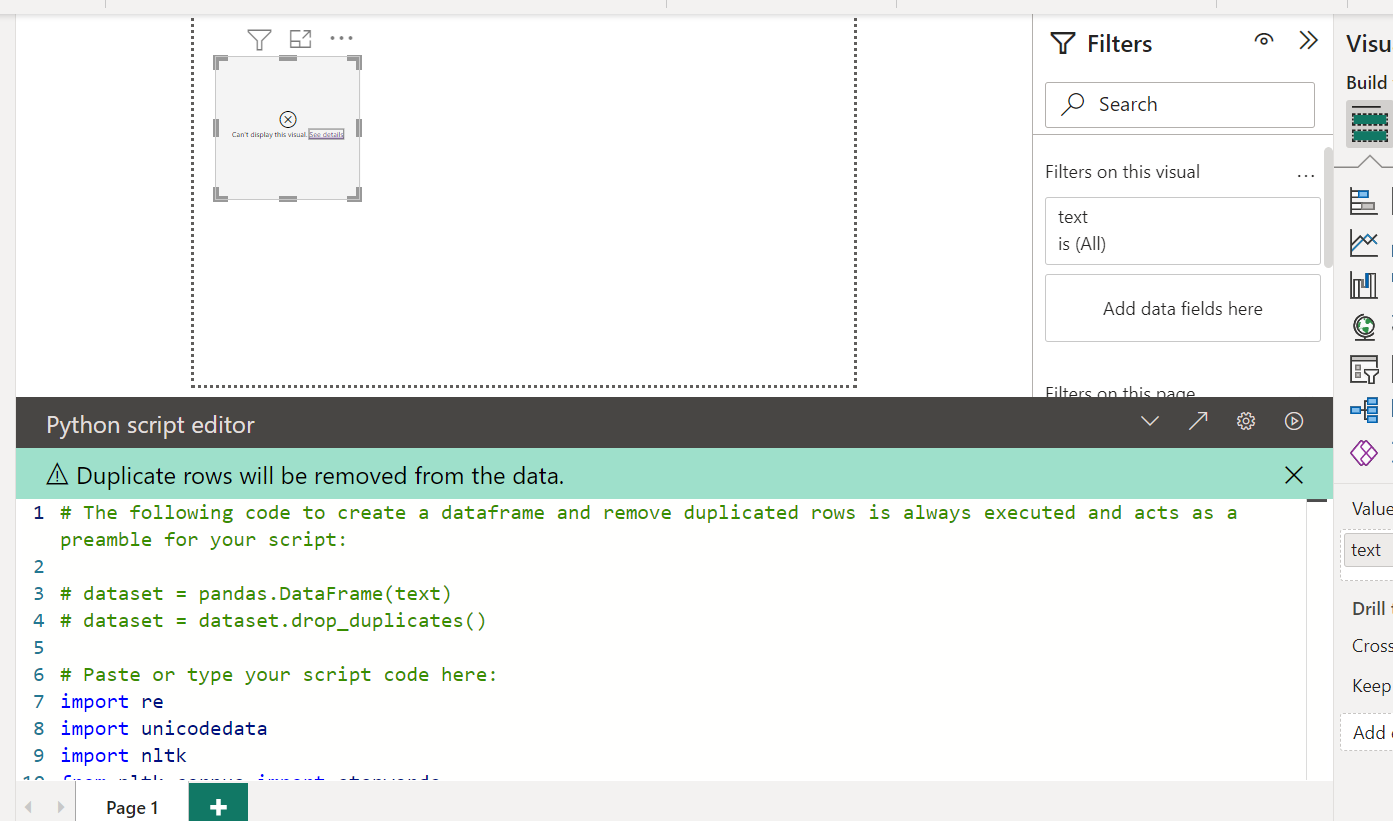
Currently i want to implement N Grams - Visual using Power Bi.
Attached is the PBix and the code i got from internet which is failing in my case. Kindly request you help me with the same. test.pbix (30.9 KB)
Next I split the code into steps so it is easier to debug
import re
import unicodedata
import nltk
from nltk.corpus import stopwords
import pandas as pd
import matplotlib.pyplot as plt
ADDITIONAL_STOPWORDS = ['covfefe']
def basic_clean(text):
wnl = nltk.stem.WordNetLemmatizer()
stopwords = nltk.corpus.stopwords.words('english') + ADDITIONAL_STOPWORDS
text = (unicodedata.normalize('NFKD', text)
.encode('ascii', 'ignore')
.decode('utf-8', 'ignore')
.lower())
words = re.sub(r'[^\w\s]', '', text).split()
return [wnl.lemmatize(word) for word in words if word not in stopwords]
words = basic_clean(''.join(str(dataset['text'].tolist())))
bigrams_series = (pd.Series(nltk.ngrams(words, 2)).value_counts())[:12]
bigrams_series.sort_values(inplace=True)
ax = plt.barh(bigrams_series, color='blue', width=.9, figsize=(12, 8))
plt.show()
Just following up if the response above helps you solve your inquiry.
If it did, please mark his answer as the SOLUTION.
We’ve noticed that no response was received from you on the post above. If there won’t be any activity in the next few days, we’ll tag this post as Solved.
I hope you are doing well. I was wondering if it would be possible for us to close this thread temporarily while you are trying out the solutions provided above. Once you have made progress and require additional support, feel free to open this thread or open a new one and reach out to us again.
Thank you for your understanding and I look forward to assisting you further in the future.
Due to inactivity, a response on this post has been tagged as “Solution”.
If you have a follow-up question or concern related to this topic, please remove the Solution tag first by clicking the three dots beside Reply and then untick the check box.