Ok so I’ve been exploring ways to avoid the second Group By operation and succeded  So would you be so kind to test these variatons as well and let me know if performance improved?
So would you be so kind to test these variatons as well and let me know if performance improved?
Thanks @Jetuke_ES
Now for future reference, this is what I’ve done:
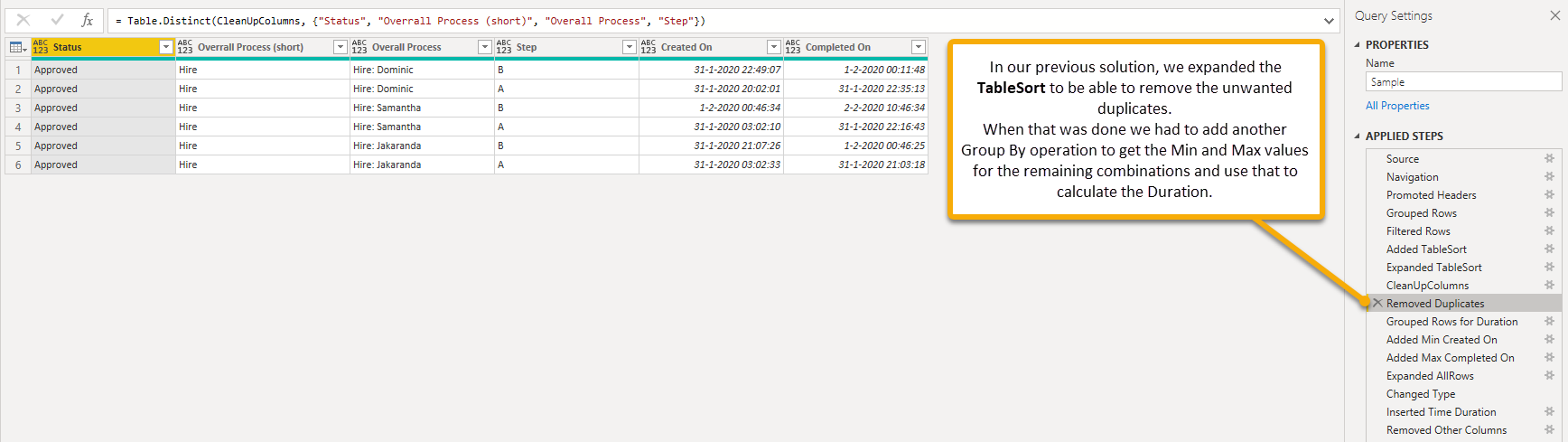
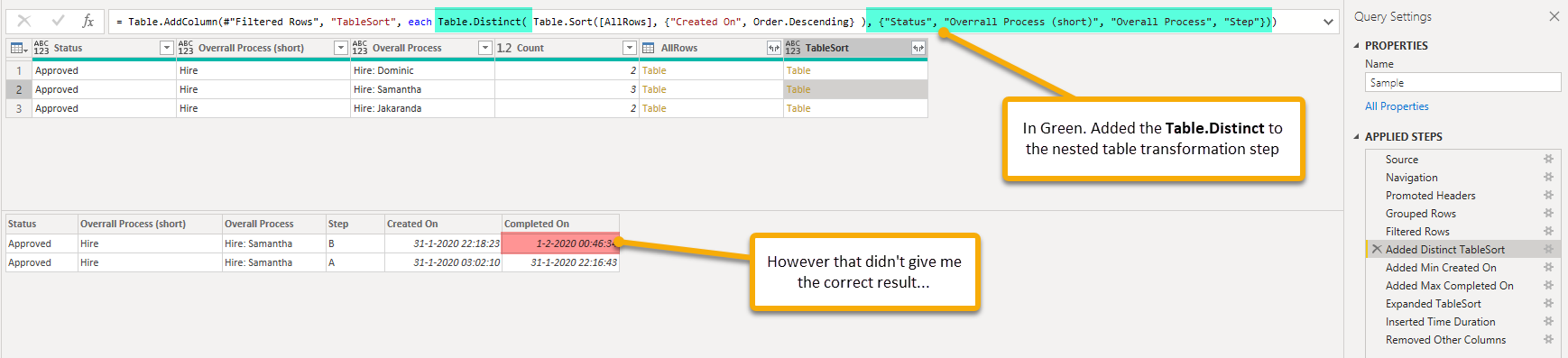

Next I extracted the Min value for [Created On] in two different ways:

Did the same for the Max value for [Completed on] also two approaches:

Here are the updates files. I hope this is helpful.
eDNA - Identify data sets to keep (3b).pbix (44.7 KB)
eDNA - Identify data sets to keep (4b).pbix (40.6 KB)