Hello,
I have a question about how to use a measure as a slicer. A sample data is like this:
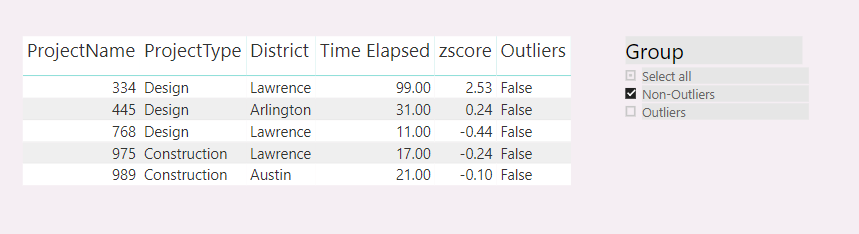
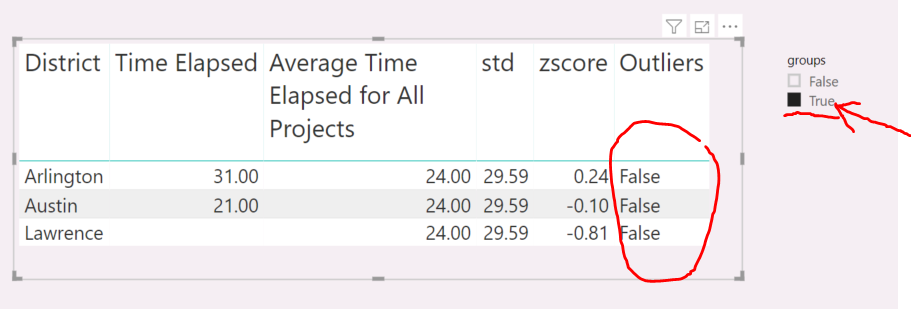
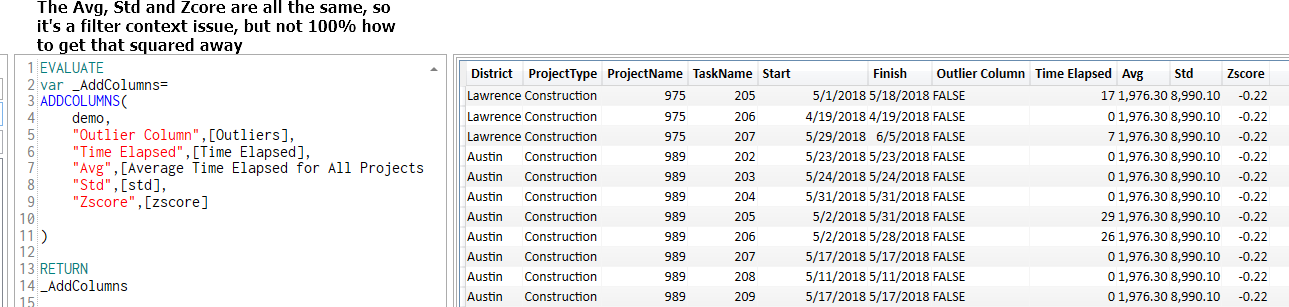
Where each project has its ProjectName, ProjectType, District, and Time Elapsed (how long it takes to finish). Time Elapsed is a measure. In order to find outliers, I calculated the Z-scores using the formula: (Time Elapsed-mean)/standard deviation. And Z-scores is also a measure. Then, I created another measure to indicate if it is an outlier based on the value of Z-scores, if it between -3 and 3, it is not an outlier, otherwise, it is. So far in the visual table, all measures showed the correct results. The next step I need is to be able to filter outliers and non-outliers using a slicer, which I am stuck. I watched the video of banding and segregating, and created a supporting table as below:
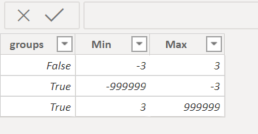
and use the following code to calculate Outliers:
Outliers = CALCULATE(
SELECTEDVALUE('Outlier supporting'[groups],BLANK()),
FILTER(ALL('Outlier supporting'),
[zscore]>'Outlier supporting'[Min] &&
[zscore]<='Outlier supporting'[Max]))
I used the group column as the value of a slicer, but it doesn’t work, it always showed all data no matter what I selected. I am wondering where I did wrong and how to fix this.
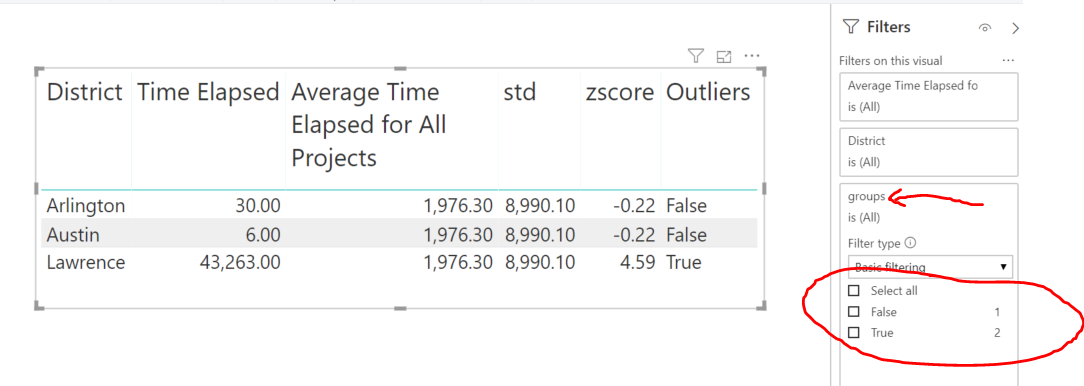
In addition, I also tried to use the Filters function, but when I click the Outliers tab, no options is showed up for some reasons.
Thanks!