Hello @KhinKyeSin,
Still, in my file, it has been right as with the wrong measure. In other words, the second rank “2” has been still keep startingly right even it is drilled down to the next level and not changing to “3” like in the example of youtube video or in your dataset file.
The reason why it’s working in your file is because the relationship which is being created between the tables are not inserting any “HIDDEN” blank values inside the data model. When hidden blank values take place inside the data model, it disrupts this kind of calculations.
Now, coming to your next query -
I always though that “AddColumn” and “Summarize” are somewhat similar that “Addcolumn” is just adding another column to its reference table and it would be completely same when it is referencing to the virtual table of Summarize.
The reason why I used “ADDCOLUMNS()” alongwith “SUMMARIZE()” is because “SUMMARIZE()” function is executed into a filter context corresponding to the values in the grouped columns. That is, if a column is created inside the “SUMMARIZE()” function itself then, in that case, everything will be considered as one single set of group. So for example, let’s execute a below provided query and see the results in a physical table -
Table Based On SUMMARIZE Function =
SUMMARIZE(
'Location Master' ,
'Location Master'[States and Regions] ,
"@Total Sales" , [Total Sales] ,
"@Ranking" , RANKX( ALL( 'Location Master'[States and Regions] ) , [Total Sales] , , DESC ) )
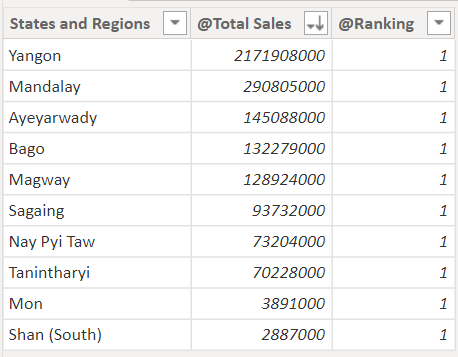
As you can observe in the above screenshot, all the rows are being ranked as 1. That’s because, the entire table is being summarized as one single group.
But now, on the other hand, when you create those exact same virtual columns inside the “ADDCOLUMNS()” section. See what happens when the below query is executed -
Table Based On ADDCOLUMNS with SUMMARIZE Function =
ADDCOLUMNS(
SUMMARIZE(
'Location Master' ,
'Location Master'[States and Regions] ) ,
"@Total Sales" , [Total Sales] ,
"@Ranking" , RANKX( ALL( 'Location Master'[States and Regions] ) , [Total Sales] , , DESC ) )
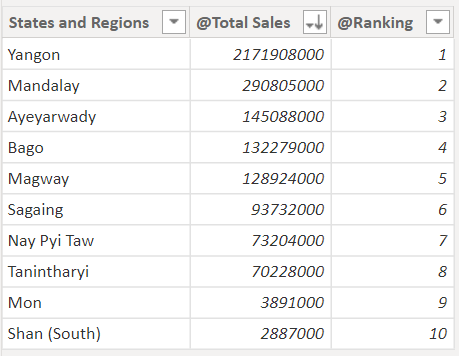
As you can observe in the above screenshot, now, all the rows are being ranked properly. But why did this happened actually? So the reason is, “ADDCOLUMNS()” function operates in a “ROW Context” that does not automatically propagate into a filter context.
And this is why, I used the “ADDCOLUMNS()” function alongwith “SUMMARIZE()” in order to evaluate the results. Secondly, when we use this type of method, it’ll also ignore all the hidden blank values, if there are any, which is being brought inside the data model because when we summarized the table, it’ll only consider the values which are actually present inside the data model. So if my model contains any physical blank values i.e., any value which is being kept as blank by me then it’ll consider the blank otherwise hidden values will be ignored.
I’m also providing a link below pertaining to the topic - “Best practices using SUMMARIZE and ADDCOLUMNS” for the reference purposes.
Hoping you find this explanation useful and strengthens your understanding about this concept.
Thanks and Warm Regards,
Harsh