Hi,
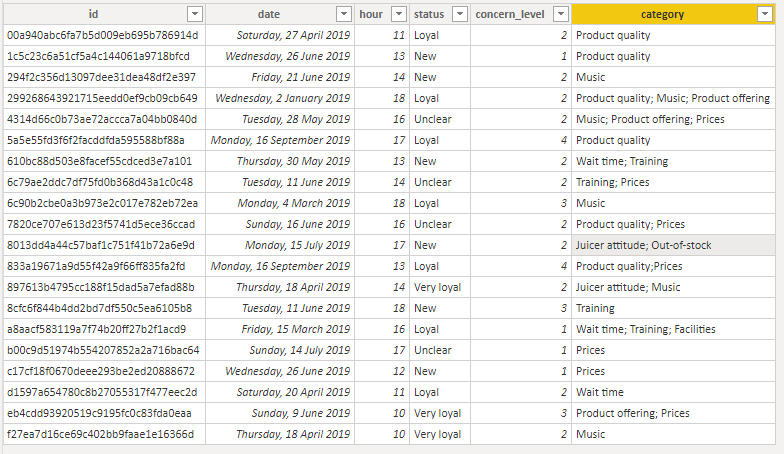
I have a table containing unique rows, each defined by a unique ID column.
In the last column, I have a category column, containing multiple categories in one string, separated by a semicolon.
I want to separate the categories, so that I know how many id’s “product category” fx was mentioned on. At the same time i wan’t to be able to create two measures:
- Total ID's = DISTINCTCOUNT(Table_Original[id])
- Average Concern level = AVERAGE(Table_Original[concern_level])
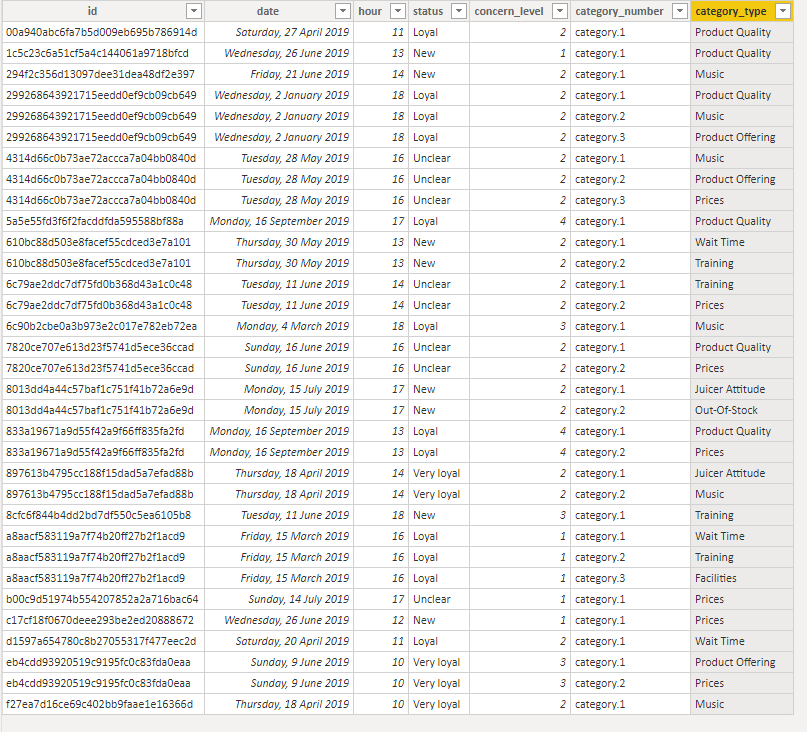
I tried to split the category column by delimiter “;”, and then unpivoted the table:
The problem is that the measure for Concern-level is not working anymore, as the values are duplicated for each category.
Does anybody have an idea for how i can work with this kind of data in the best possible way?
(See example PBIX file attached)
PBIX_test_file.pbix (63.8 KB)
Hi @JNordentoft,
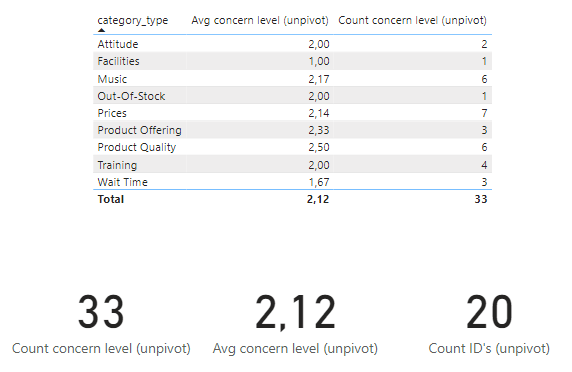
I’ve used your Table_Original_Multiple_Rows table which has a 1:* relationship to your Product Categories table. For the Avg.
Avg concern level (unpivot) =
AVERAGEx( Table_Original_Multiple_Rows, [concern_level] )
for the count
Count concern level (unpivot) =
COUNTROWS( Table_Original_Multiple_Rows )
and unique ID’s
Count ID's (unpivot) =
COUNTROWS( VALUES( Table_Original_Multiple_Rows[id] ))
with this result.
If you are expecting a different result please provide a mockup illustrating the desired outcome.
Here’s your sample file:
PBIX_test_file.pbix (64.2 KB)
I hope this is helpful.
1 Like
Hi Melissa,
Thanks for the response!
The Count ID’s works perfectly. Though the average concern level gives me the wrong output since it does not take into account that some of the values are duplicated (since we unpivoted the table to get categories on individual rows).
Example:
Here the ID is duplicated in order to get the three categories on seperate rows.
Therefore the average is affected, and counts three “2’s” on the average instead of one.
Hope it makes sense 
Hi @JNordentoft,
Please supply a mockup of the desired result because you are now calculating Avg over the Category so to which Category should the concern level be attributed, if not to all??
Maybe this is what you are after…
Avg concern level per ID =
VAR vTable =
SUMMARIZE( Table_Original,
Table_Original[id],
Table_Original[status],
Table_Original[date],
Table_Original[hour],
Table_Original[concern_level]
)
RETURN
AVERAGEX( vTable, [concern_level] )
I hope this is helpful
1 Like
Hi @JNordentoft, good to see you are having progress with your inquiry.
Did the response provided by @Melissa help you solve your query? If not, how far did you get and what kind of help you need further? If yes, kindly mark as solution the answer that solved your query.
I hope that you are having a great experience using the Support Forum so far. Kindly take time to answer the Enterprise DNA Forum User Experience Survey, we hope you’ll give your insights on how we can further improve the Support forum. Thanks!
1 Like
Hi Melissa,
Exactly what I was looking for. Just used the “Table_Original_Multiple_Rows” instead. Since my goal is to keep only one of the fact tables
Good to hear that @JNordentoft. We marked that answer as SOLVED.
If you have a follow question or concern related to this topic, please remove the Solution tag first by clicking the three dots beside Reply and then untick the check box.
Kindly take time to answer the Enterprise DNA Forum User Experience Survey, we hope you’ll give your insights on how we can further improve the Support forum. Thanks!