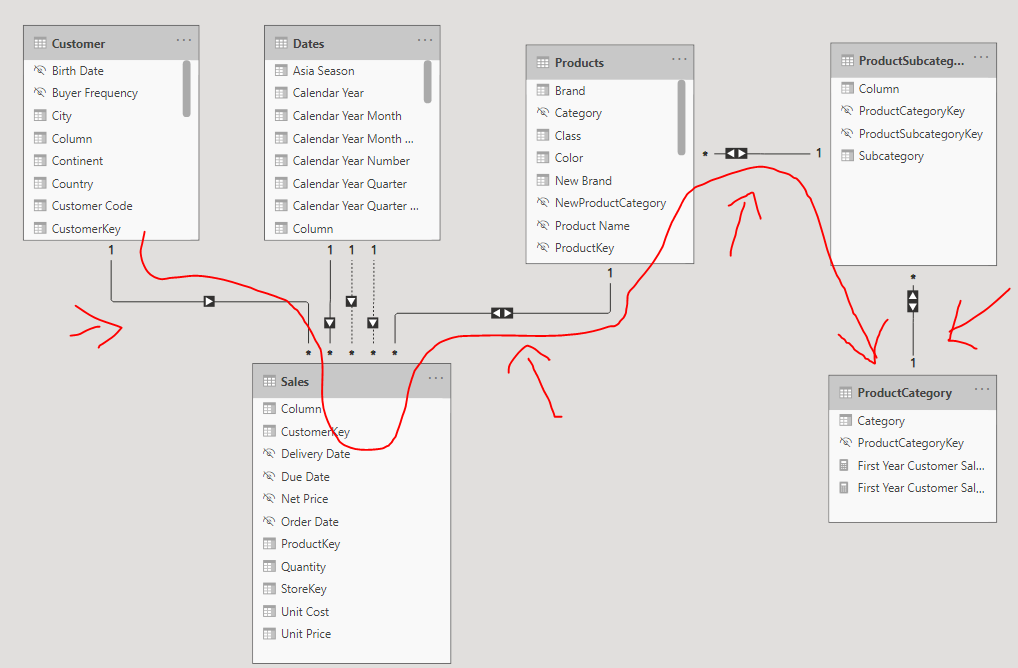
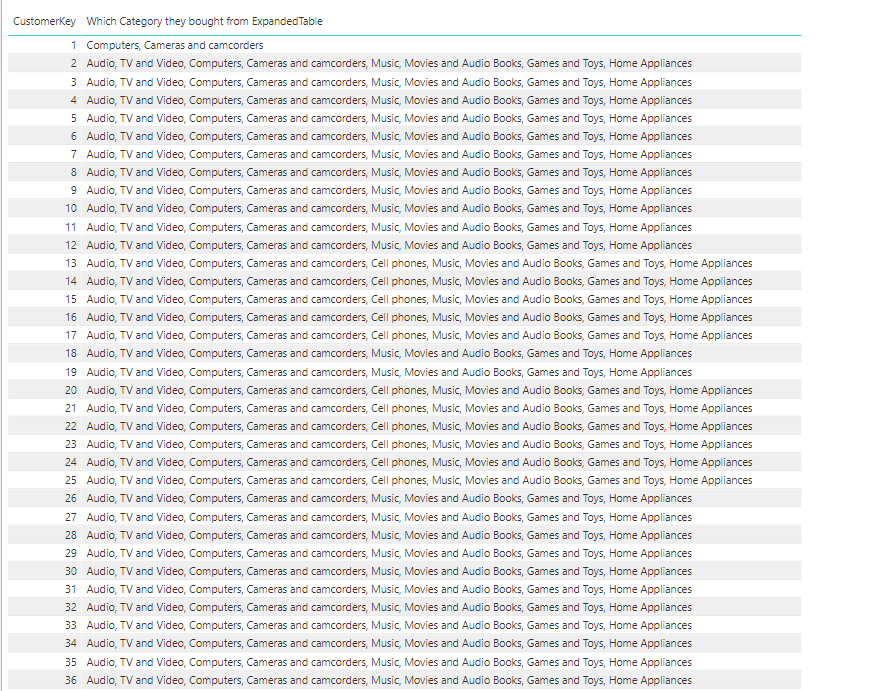
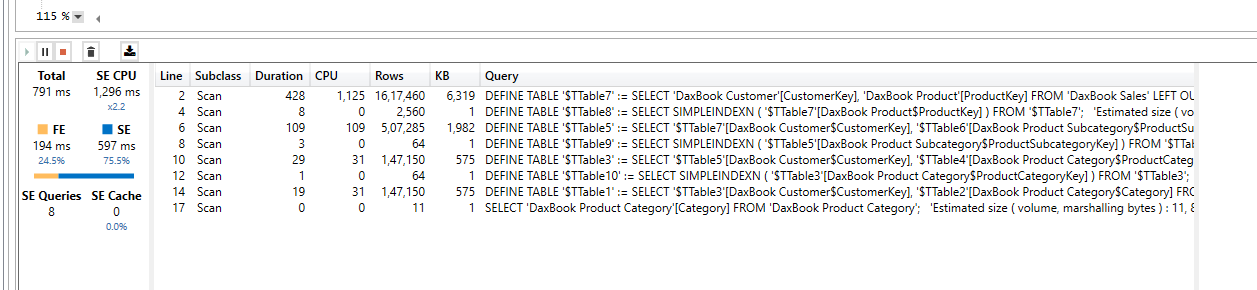
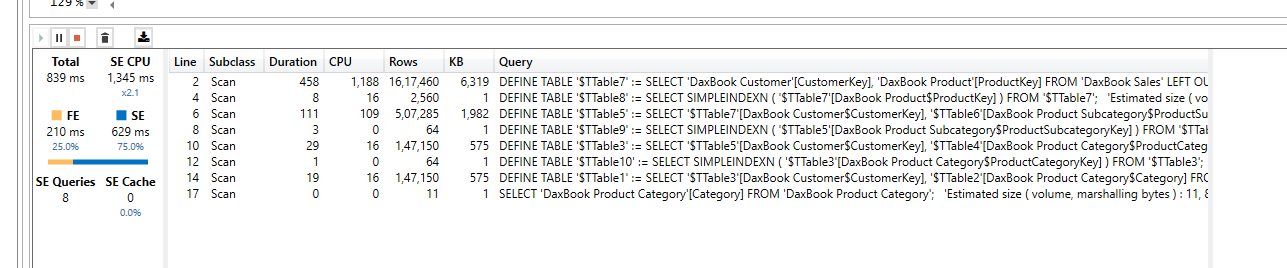
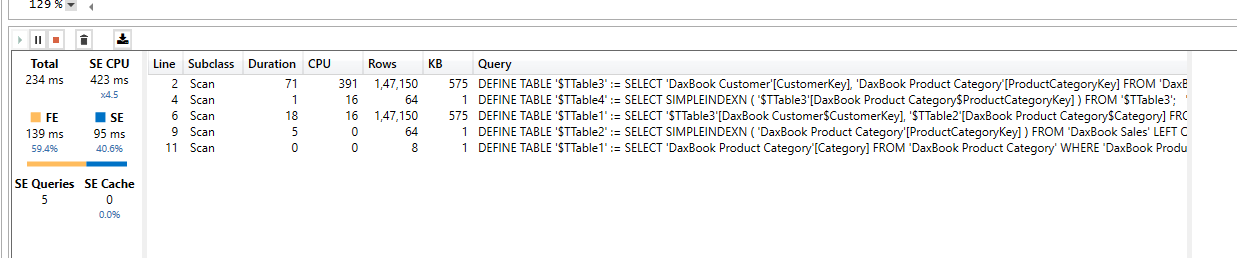
I don’t think there will be any performance difference in CROSSFILTER vs Bi-Directional filtering, however TableExpansion proves to be much efficient in contoso dataset. I the below example I am trying to get the list of Categories from which each customer bought.
Here are the queries generated by
Bi-Directional filtering:
Which Category they bought from =
CONCATENATEX (
VALUES ( ProductCategory[Category] ),
ProductCategory[Category],
", "
)
CROSSFILTER ( no difference in both )
Which Category they bought from CrossFilter =
CALCULATE (
CONCATENATEX (
VALUES ( ProductCategory[Category] ),
ProductCategory[Category],
", "
),
CROSSFILTER ( Sales[ProductKey], Products[ProductKey], Both ),
CROSSFILTER ( Products[ProductSubcategoryKey], ProductSubcategory[ProductSubcategoryKey], Both ),
CROSSFILTER ( ProductSubcategory[ProductCategoryKey], ProductCategory[ProductCategoryKey], Both )
)
Table Expansion: Wins the match
Which Category they bought from ExpandedTable =
CALCULATE (
CONCATENATEX (
VALUES ( ProductCategory[Category] ),
ProductCategory[Category],
", "
),
Sales
)
So the answer is “it depends”, one code will be not be the best one for every model you have to play with it and find what works best for you.