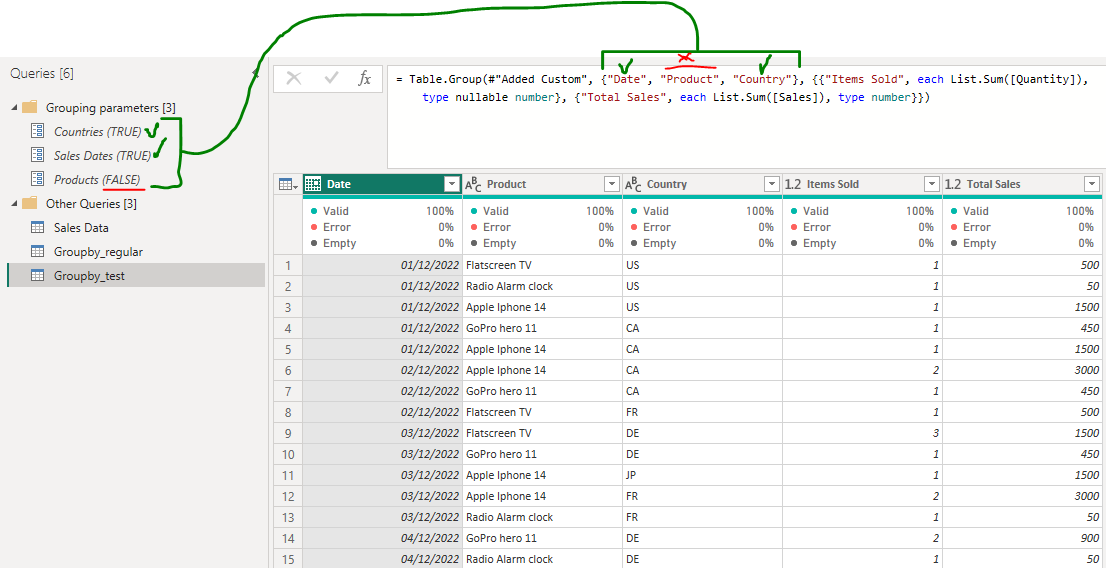
I’m looking for a method to dynamically select the columns on which a table with data is to be grouped, summarizing sales and items sold depending on the grouping.
I’ve got a number of sources that deliver very granular data, in some cases I need to zoom into this granularity, in others it’s not really needed.
In order to optimize the queries I’m looking for ways to minimize the number of rows by adjusting only a few parameters instead of having to dive into the table.group formulas for each source.
Appending all the queries before the grouping step is one option I’ve considered, but I’m specifically looking to do the grouping and minimizing the rows in an earlier stage.
My guess is combining Table.Group with an if statement and parameters (true/false) for the columns that I’d like to exclude or include depending on the situation, but I’m not sure where to start with the if statement.
Below is an example .pbix. In the query editor you will find an example setup and parameters set to define which columns to include in the Group By. Any help would be much appreciated!
eDNA Forum question - Group By - dynamic column selection.pbix (83.9 KB)
Any other suggestions for a similar setup are welcome also!