Hi
I have an old payroll system. I do not have access to the data files themselves but only to reports. Attached is a pdf report out of the sample company. When I Import into Power Query using Get From PDF I get several tables per page. Each Employee starts on a new page but can span a page. Each time the report is run the Page may have a different number of tables I on it eg. this time Employee 1002 doesn’t have Table A and next time they do – or the other way around.
BTW: Each user will store their version of the pdf in a different location with a different name.
I want the data in
- Personal Section (present on every page)
- Job Section (present on every page)
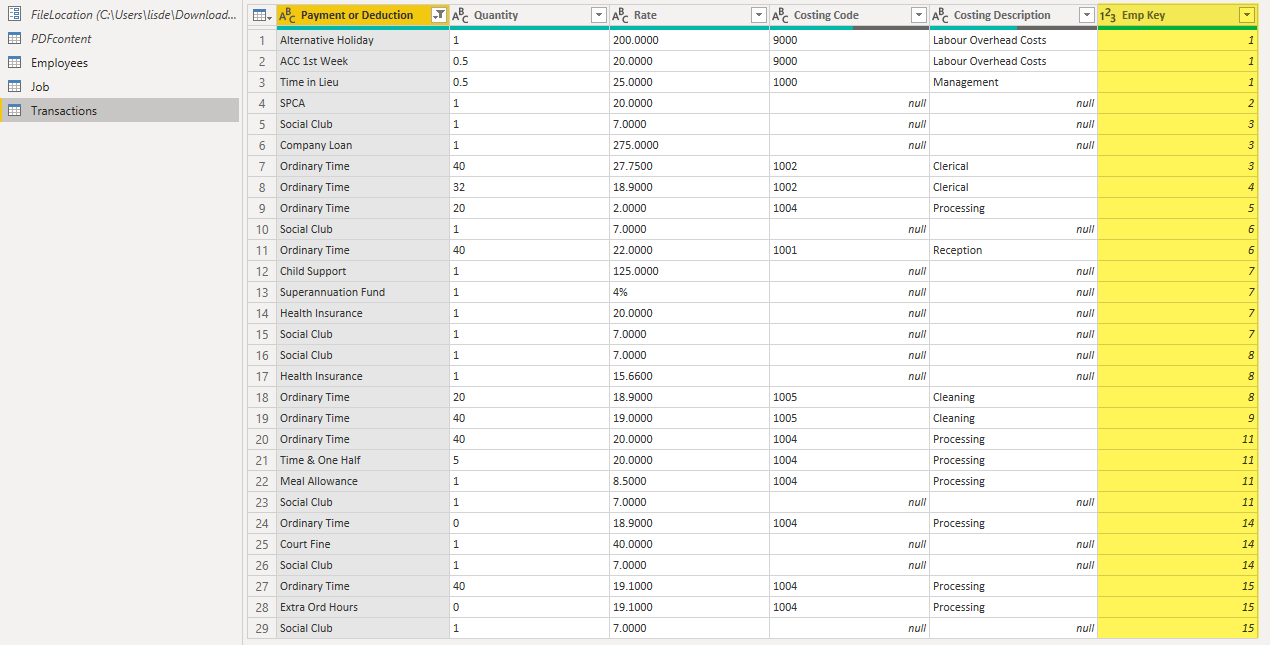
- A particular Table (call it Table A). Only some pages have this table. The table I want is the one like the last on Page 1 – the first heading is “Payment or Deduction” the second “Quantity” etc.
I want to
- Combine all the Personal Section for each Employee into one table with the employee as a column.
- The same for the Job Section
- The same for any instance of TABLE A in the File
My issue is how to identify which Tables to import from each page when they do not have meaningful names.
How would I go about getting the data I need as above?
Kind regards
Allister
GetPDF.xlsb (13.1 KB)Splits.PDF (353.1 KB)
Hi @AllisterB,
Not all Employees have an Employee number so instead I added an Emp Key, that links all tables.
Here’s your sample PBIX: ConvertPDF.pbix (38.5 KB)
I hope this is helpful.
2 Likes
Thank You Melissa
Will I have to alter it much for PQ?
Allister
Hi @AllisterB,
You can copy all queies over to Excel, don’t expect any issues there.
@Melissa
Hi Melissa
The solution works fine and I was as you said able to copy it directly over - Thank you.
I have used your work to successfully bring in other parts of the Report.
However, I was asked to bring in more data to the pdf report - the section called SUPERANNUATION - KIWISAVER. The new PDF is Called SplitsKS. When I went to create a query for this table I discovered that using the modified PDF file causes the first occurrence of SUPERANNUATION - KIWISAVER to insert a new Starting Column. I cannot see why this should not work the same as the other sections of eth PDF. The insertion of the Column misaligns the query output table.
Is there a fix or will I have to work around it somehow ?
Kind Regards
Allister
Convert2.xlsm (455.3 KB)
SplitsKS.PDF (411.6 KB)
Hi @AllisterB,
The solution is designed for a specific input file. Changing that can cause problems, like you’ve already experienced… Here’s a modified version based on the new lay-out.
ConvertPDF2.pbix (39.6 KB)
In future, know that this is a change in requirement, please try to avoid these types of iterations as much as possible so the members giving up their free time to help others can do so more effectively.
Thank you!
3 Likes