Sample Table.pbix (536.6 KB)
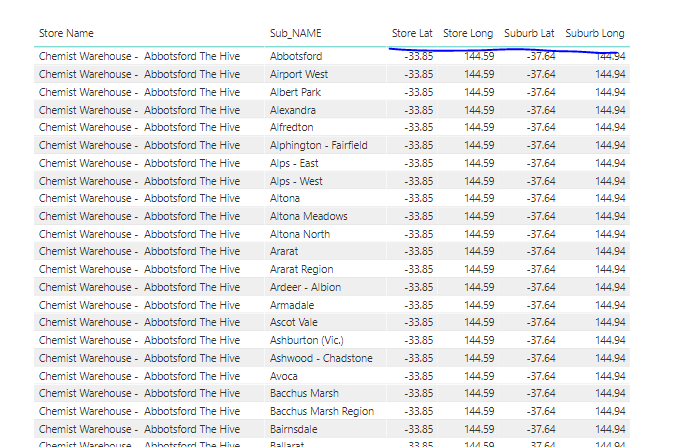
I’ve worked my way through the creation of a virtual table that calculates the distance between Lat/Long coordinates for suburbs and Lat/Long coordinates for stores. When I materialise this virtual table through the “Make Table” function I’m able to obtain a table of Suburb Name, Store Name and Distance… which is great except it’s 4.3 million rows and creates performance issues for the calculations that use the table. What I want to achieve is a means of reducing the size of the table by filtering the Distance column ie. Suburb to Store distances < 10Km.
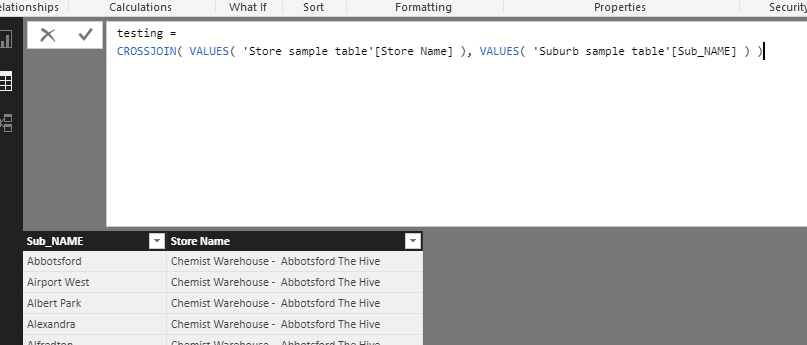
The Dax code is
VAR Final_Table =
SELECTCOLUMNS( Crossjoin_Table, // crossjoin of Suburb, Lat, Long and Store, Lat,Long
"Sub_Name", 'Sub Heirarchy'[Name],
"Store_Name", 'Retailers Table'[Store Name],
"Sub-Store Dist", [Dist] // a calculation of distance between Suburbs and Stores... 4.3M values.
Return
However, I’ve tried every possible permutation and combination of dax expressions to filter the distance values of the Sub-Store Dist field without success. The major issue being the Field is not available for use in a Calculate or Calculatetable statement and only appears in the following code,
SUMMARIZE(Final_Table,
[Sub_Name],
[Store_Name],
[Sub-Store Dist])
which returns the 4.3M rows. Any suggestions on how I can reference this field in a Calculatetable function so I can reduce the number of rows returned by the table? A sample file containing data and the current Make Table Dax calculation is attached.