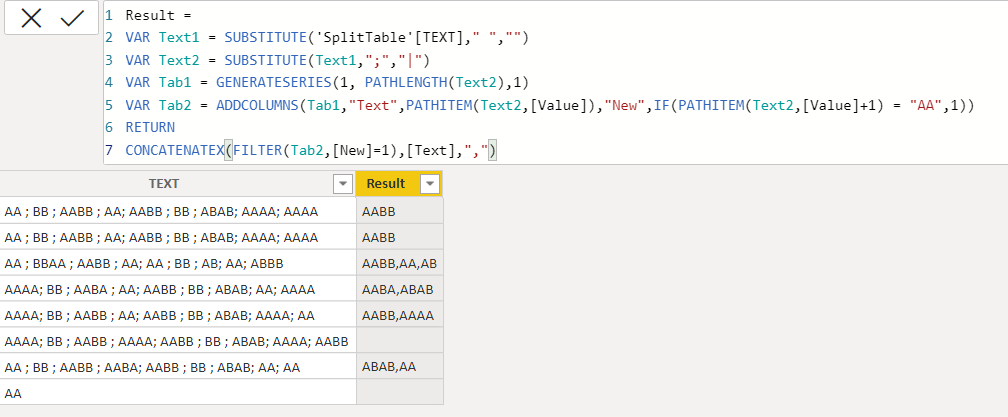
Hello,
I am struggling to find a DAX Calculation that will help me extract values before “AA” in the sample data below.
Please see current data and desired outcome here;
Regards
Gladys
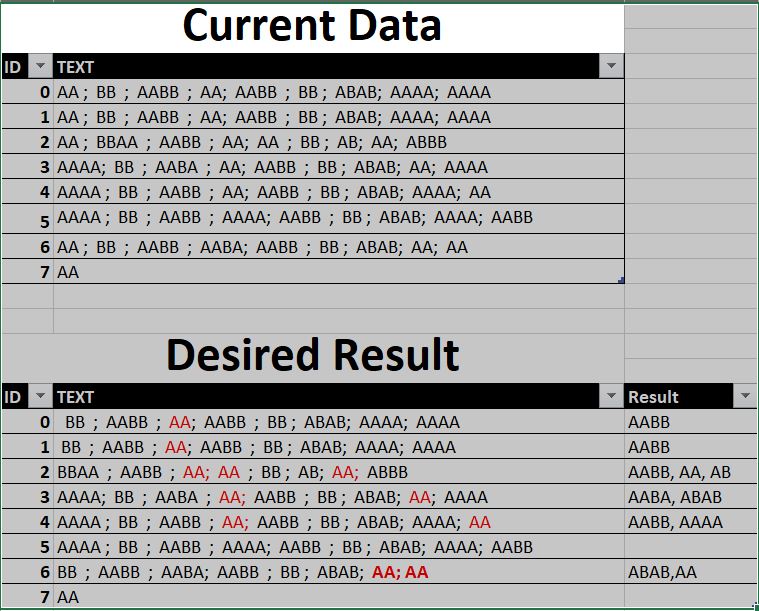
Hello,
I am struggling to find a DAX Calculation that will help me extract values before “AA” in the sample data below.
Please see current data and desired outcome here;
Regards
Gladys
Hi @GladysN
If I got your requirement correctly, then use split column under the transform tab.
Select split column by delimiter and use custom. As I can see your data has a pattern so in custom use " ; AA; " and you can get the new column with your desired results.
Please let me know if any thing else needed.
Thanks,
Ankit Kukreja
www.linkedin.com/in/ankit-kukreja1904
Hi @GladysN,
Welcome to the Forum!
This sounds like a job for Power Query. Here’s what I did.
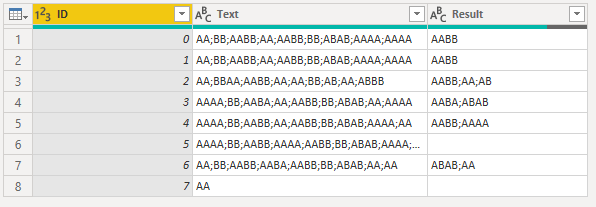
I hope this is helpful. Here’s my sample file.
eDNA - Extract values before a specific text.pbix (25.0 KB)
Welcome to the forum - great to have you here!!
@Melissa and I have a regular routine on the forum, where we often start working on a problem at the same time. She typically provides efficient, elegant solutions in power query, while I typically throw a lot of DAX at the problem.
She finished and posted her solution before I did, but I thought in the interests of education I would post my “throw a lot of DAX at the problem” solution anyway.
I first unpivoted data as @Melissa did, then used the following calculated column to find the strings prior to AA:
Prior to AA =
VAR PriorIndex =
CALCULATE(
MAX('Data Unpivoted'[Index]),
FILTER(
'Data Unpivoted',
'Data Unpivoted'[ID] = EARLIER( 'Data Unpivoted'[ID] ) &&
'Data Unpivoted'[Index] < EARLIER( 'Data Unpivoted'[Index] )
)
)
VAR PriorString =
CALCULATE(
MAX( 'Data Unpivoted'[Segment] ),
FILTER(
'Data Unpivoted',
'Data Unpivoted'[ID] = EARLIER( 'Data Unpivoted'[ID] ) &&
'Data Unpivoted'[Index] = PriorIndex
)
)
VAR Result=
IF( 'Data Unpivoted'[NonFirst AA] = 1,
PriorString,
BLANK()
)
RETURN
Result
Then I used the following measure to virtually link the pivoted and unpivoted data tables together through the ID fields in each table via TREATAS, and then concatenate the results from the prior calculated column by the ID field in the original table:
Concat PriorAA =
CALCULATE(
CONCATENATEX(
'Data Unpivoted',
'Data Unpivoted'[Prior to AA],
", " ,
'Data Unpivoted'[Index],
ASC
),
ALLEXCEPT(
Data,
Data[ID]
),
TREATAS(
VALUES( Data[ID] ),
'Data Unpivoted'[ID]
),
FILTER(
'Data Unpivoted',
'Data Unpivoted'[Prior to AA] <> BLANK()
)
)
Not nearly as elegant as @Melissa’s approach, but still gets the job done:
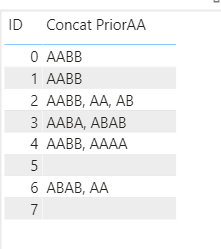
Full solution file posted below if you want to look at the details.
Hi @Melissa
Today I saw your video in Youtube excellent solution in M.
I just want to share my DAX Solution
@Rajesh ,
Wow! Really creative, elegant solution in about 1/4 of the lines it took me to do it in DAX. 
Hi @Rajesh,
Thanks for sharing!
Yes, there are many different ways to solve this ‘puzzle’ not only in Power Query but also in DAX. You’ve just illustrated that in an amazing way