Doing some data wrangling (easy stuff) my ETL starts generation millions of rows and taking forever starting from Excel files where the largest hardly reach 25K rows.
I just merge (I could do a VLOOKUP) and append (some copy and paste would do) to get intermediate results to the final dataset.
Is there anything I should pay attention? Is there any best practice to avoid this doom?
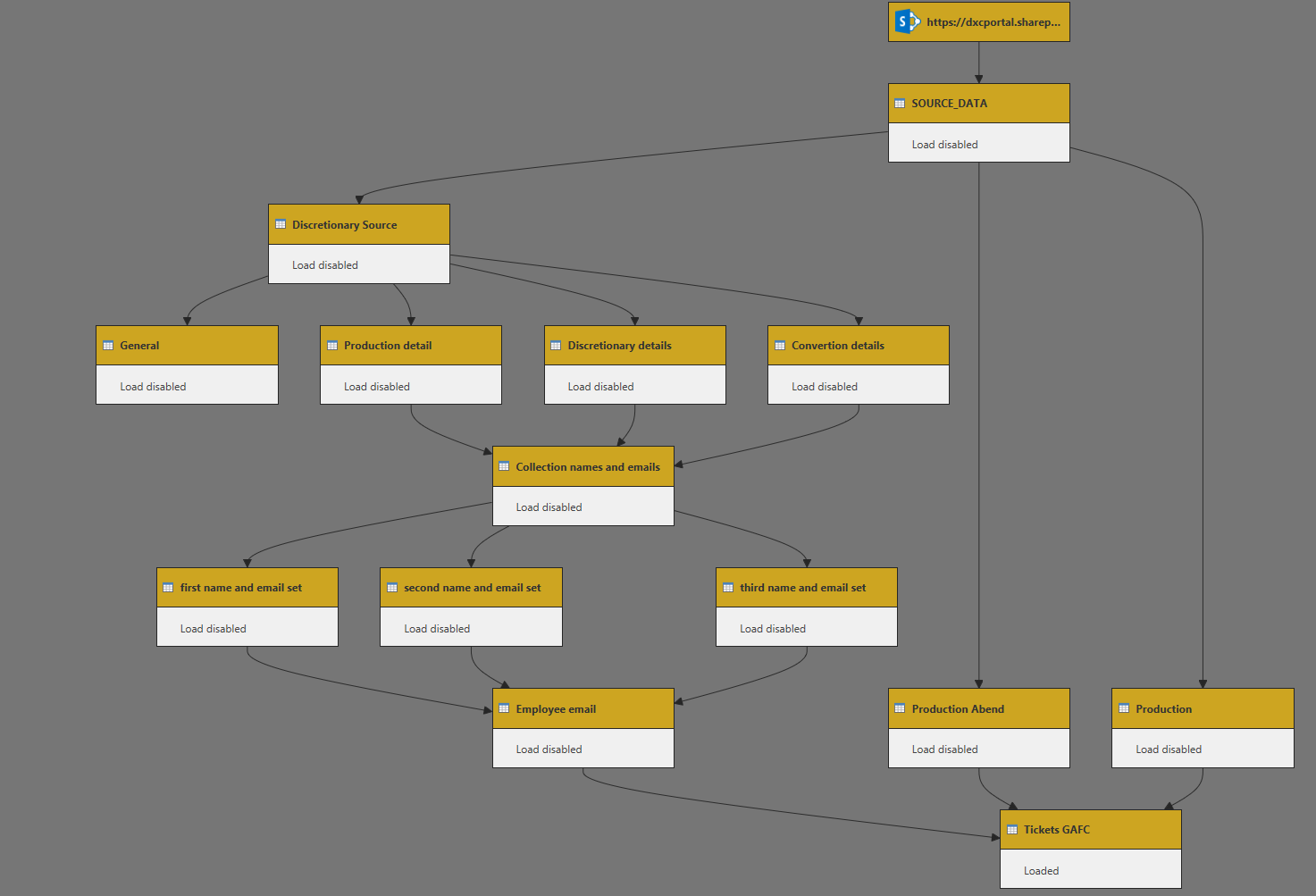
I think I found where the number of rows spikes. It’s the Table.NestedJoin but the behavior is unexpected.
The left table is 22,564 row and when merged rises to 87,782.
From documentation using the JoinKind.LeftOuter should perform a left outer join that is all rows from the table in the first parameter are returned only matching rows from the right table are returned.
I’m doing something wrong. But what? Right table is clean, no null or empty value. Really weird.
Hopefully you are stepping through your transformations and seeing step by step where the issues are appearing.
Have you tried some of the other joins to see if you get the expected results? Sometimes it just testing out a few of these to see where things are going wrong and then ultimately correcting them.
Also are you sure you’re merging on the correct columns. Review this as well.
@Roberto ,
I typically see results like that in SQL Server queries where there is unexpected matching occurring. The LEFT JOIN is just circumstantial in this case.
In a “normal” situation, the right table may produce multiple matches for each record in the left table. So one employee in the left table with multiple matches in the right table on name or email address. You can also have the reverse if the left table is a fact table and the right table is a dimension table.
In an “exception” situation, you can actually have multiple records in the left table that each match the same multiple records in the right table. Joins on common values like last names or trying to join 2 fact tables together can do this.
Your output is between 3 and 4 times the source record count, so I would try to look for groupings of “duplicate” records in that range, although in some scenarios you can have a batch of many “duplicate” records and a bunch of the expected 1-to-1 matches. This analysis is really easy to do in MS Access if you don’t have SQL Server. You just import the Excel data as tables into Access and then create a simple query joining the tables the same way you are in the M code.
Thanks to the contributors of this post. Due to the length by which this post has been active, we are tagging it as Solved. For further questions related to this post, please make a new thread.